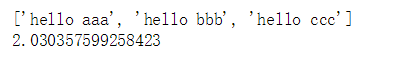爬取网页遇到问题: http://sc.chinaz.com/jianli/free.html爬取简历模板 HTTPConnectionPool(host:XX)Max retries exceeded with url。 原因: 1当你在短时间内发起高频请求时,http 的连接池中的连接资源被耗尽 Connection:keep-alive 2 IP 被封 解决方法: 1 请求headers 中添加: Connection:'close' 2换ip 数据解析 目的:实现聚焦爬虫!!! 数据解析的通用原理: 1.标签定位 2.数据提取 bs4: 1.实例化一个BeautifulSoup的对象,将即将被解析的页面源码加载到该对象 2.属性和方法实现标签定位和数据的提取 soup.tagName soup.find/findall('tagName',class='value') select('选择器'):返回的是列表 tag.text/string:字符串 tag['attrName'] xpath:xpath方法返回的一定是列表 表达式最左侧的/ 和 //的区别 非最左侧的/和//的区别 属性定位://div[@class="xxx"] 索引定位://div[2] /text() //text() /div/a/@href
代理
代理操作 目的:为解决ip被封的情况 什么是代理? 代理服务器:fiddler 为什么使用了代理就可以更改请求对应的ip呢? 本机的请求会先发送给代理服务器,代理服务器会接受本机发送过来的请求(当前请求对应的ip就是本机ip), 然后代理服务器会将该请求进行转发,转发之后的请求对应的ip就是代理服务器的ip。 提供免费代理ip的平台 www.goubanjia.com 快代理 西祠代理 代理精灵:http://http.zhiliandaili.cn 代理ip的匿名度 透明:使用了透明的代理ip,则对方服务器知道你当前发起的请求使用了代理服务器并且可以监测到你真实的ip 匿名:知道你使用了代理服务器不知道你的真实ip 高匿:不知道你使用了代理服务器也不知道你的真实ip 代理ip的类型 http:该类型的代理IP只可以转发http协议的请求 https:只可以转发https协议的请求
# 代理 import requests import random from lxml import etree headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36" } # 搭建一个简易的代理池 proxy_list=[ {'https':'118.26.170.209:8080'}, {'https':'212.64.51.13:8888'}, ] url='https://www.baidu.com/s?wd=ip' # 基础方法 # page_text=requests.get(url=url,headers=headers,proxies={'https':'118.26.170.209:8080'}).text page_text=requests.get(url=url,headers=headers,proxies=random.choice(proxy_list)).text # 查看代理 with open('ip.html','w',encoding='utf-8') as fp: fp.write(page_text)
# 代理精灵 http.zhiliandaili.cn # 代理 import requests import random from lxml import etree headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36" } p_ips=[] ip_url='http://ip.11jsq.com/index.php/api/entry?method=proxyServer.generate_api_url&packid=1&fa=0&fetch_key=&groupid=0&qty=3&time=1&pro=&city=&port=1&format=html&ss=5&css=&dt=1&specialTxt=3&specialJson=' page_text=requests.get(url=ip_url,headers=headers).text tree=etree.HTML(page_text) ip_list=tree.xpath('//body//text()') for ip_port in ip_list: dic={"https":ip_port} p_ips.append(dic) print(p_ips) all_ips=[] url='https://www.kuaidaili.com/free/inha/%d/' for page in range(1,3): print("爬取第{}页数据".format(page)) new_url=format(url%page) iipp = random.choice(p_ips) print(iipp) page_text=requests.get(url=new_url,headers=headers,verify=False,proxies=iipp).text tree=etree.HTML(page_text) tr_list=tree.xpath("//div[@id='list']/table//tr")[1:] for tr in tr_list: ip=tr.xpath("./td[1]/text()")[0] port=tr.xpath("./td[2]/text()")[0] type=tr.xpath("./td[4]/text()")[0] dic={ "ip":ip, "port":port, "type":type, } all_ips.append(dic) print(all_ips) print(len(all_ips))
cookie
# Cookie # 什么是cookie? # 保存在客户端的键值对 # 爬取雪球网中的新闻数据:https://xueqiu.com/ # import requests # import random # from lxml import etree # headers={ # "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36" # } # # 通过抓包工具捕获基于Ajax 请求的数据包中的url # url='https://xueqiu.com/v4/statuses/public_timeline_by_category.json?since_id=-1&max_id=20343440&count=15&category=-1' # data=requests.get(url=url,headers=headers).text # print(data) # # 报错信息 # # {"error_description":"遇到错误,请刷新页面或者重新登录帐号后再试", # # "error_uri":"/v4/statuses/public_timeline_by_category.json","error_data":null,"error_code":"400016"} import requests import random from lxml import etree headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36" } # 创建一个Session的对象 session=requests.Session() first_url='https://xueqiu.com/' # 获取cookie 并将其保存到 session中 session.get(url=first_url,headers=headers) # 通过抓包工具捕获基于Ajax 请求的数据包中的url url='https://xueqiu.com/v4/statuses/public_timeline_by_category.json?since_id=-1&max_id=20343440&count=15&category=-1' 携带cookie 发送请求 data=session.get(url=url,headers=headers).json() print(data)
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
验证码
# - 验证码的识别 # - 超级鹰:http://www.chaojiying.com/about.html # - 使用流程: # - 注册:用户中心身份的账号 # - 登陆: # - 充值一块 # - 创建一个软件:软件ID-》生成一个软件ID # - 下载示例代码:下载基于python的示例代码 # - 云打码:http://www.yundama.com/demo.html
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
实例展示
#!/usr/bin/env python # coding:utf-8 # 这是直接调用超级鹰 的开发文档 import requests from hashlib import md5 class Chaojiying_Client(object): def __init__(self, username, password, soft_id): self.username = username password = password.encode('utf8') self.password = md5(password).hexdigest() self.soft_id = soft_id self.base_params = { 'user': self.username, 'pass2': self.password, 'softid': self.soft_id, } self.headers = { 'Connection': 'Keep-Alive', 'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)', } def PostPic(self, im, codetype): """ im: 图片字节 codetype: 题目类型 参考 http://www.chaojiying.com/price.html """ params = { 'codetype': codetype, } params.update(self.base_params) files = {'userfile': ('ccc.jpg', im)} r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers) return r.json() def ReportError(self, im_id): """ im_id:报错题目的图片ID """ params = { 'id': im_id, } params.update(self.base_params) r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers) return r.json()
# if __name__ == '__main__': # chaojiying = Chaojiying_Client('超级鹰用户名', '超级鹰用户名的密码', '96001') #用户中心>>软件ID 生成一个替换 96001 # im = open('a.jpg', 'rb').read() #本地图片文件路径 来替换 a.jpg 有时WIN系统须要// # print chaojiying.PostPic(im, 1902) # 传入参数 def getCodeImgText(imgPath,imgType): # 用户的信息 密码 id chaojiying = Chaojiying_Client('bobo328410948', 'bobo328410948', '899370')#用户中心>>软件ID 生成一个替换 96001 im = open(imgPath, 'rb').read()#本地图片文件路径 来替换 a.jpg 有时WIN系统须要// return chaojiying.PostPic(im,imgType)['pic_str']
# 获取验证码 参考实例 # import requests # import random # from lxml import etree # headers={ # "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36" # } # # 获取验证码图片 登录地址获取 # url='https://so.gushiwen.org/user/login.aspx?from=http://so.gushiwen.org/user/collect.aspx' # page_text=requests.get(url=url,headers=headers).text # tree=etree.HTML(page_text) # img_src='https://so.gushiwen.org'+tree.xpath('//*[@id="imgCode"]/@src')[0] # img_data=requests.get(url=img_src,headers=headers).content # with open('codeImg.jpg','wb') as fp: # fp.write(img_data) # #进行验证码的识别 根据不同类型 选取不同参数值 # getCodeImgText('codeImg.jpg',1004) # {'err_no': 0, # 'err_str': 'OK', # 'md5': '970e041fa158bcad2efd479b94308594', # 'pic_id': '9076217532357600191', # 'pic_str': 'l5vg'}
import requests import random from lxml import etree headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36" } # 添加session session=requests.Session() # 获取验证码图片 登录地址获取 url='https://so.gushiwen.org/user/login.aspx?from=http://so.gushiwen.org/user/collect.aspx' page_text=session.get(url=url,headers=headers).text tree=etree.HTML(page_text) img_src='https://so.gushiwen.org'+tree.xpath('//*[@id="imgCode"]/@src')[0] img_data=session.get(url=img_src,headers=headers).content with open('codeImg.jpg','wb') as fp: fp.write(img_data) # <input type="hidden" name="__VIEWSTATE" id="__VIEWSTATE" value="dysU8FT3M/c3eKDVrUAE67+EnvHnTNDMuBq93Ox3GtOEtATQ1Ln9FhzjUFkbxlwwCDQ2+XVGO2liru9sOke6bsYKRz8nR1dyqzYGPkjoR87PcgiETz2lAGQd/gg="> # 运行发现依然没有登录上,去前端查询 修改 data 中的参数 (动态变化的请求参数) #解析动态变化的请求参数 __VIEWSTATE = tree.xpath('//input[@id="__VIEWSTATE"]/@value')[0] __VIEWSTATEGENERATOR = tree.xpath('//input[@id="__VIEWSTATEGENERATOR"]/@value')[0] # print(__VIEWSTATE,__VIEWSTATEGENERATOR) #进行验证码的识别 根据不同类型 选取不同参数值 code_text=getCodeImgText('codeImg.jpg',1004) print(code_text) # 模拟登录 url='https://so.gushiwen.org/user/login.aspx?from=http%3a%2f%2fso.gushiwen.org%2fuser%2fcollect.aspx' # 运行发现依然没有登录上,去前端查询发现不是固定值 修改 data 中的参数 (动态变化的请求参数) data={ '__VIEWSTATE': __VIEWSTATE, '__VIEWSTATEGENERATOR':__VIEWSTATEGENERATOR, 'from': 'http://so.gushiwen.org/user/collect.aspx', 'email': 'www.zhangbowudi@qq.com', 'pwd': 'bobo328410948', 'code': code_text, 'denglu': '登录', } main_page_text=session.post(url=url,headers=headers,data=data).text with open('./main.html','w',encoding='utf-8') as fp: fp.write(main_page_text) # 总结 # 有哪些反爬机制: cookie 动态请求参数 验证码
线程池 异步爬取
# flask服务器代码: from flask import Flask from time import sleep app=Flask(__name__) @app.route("/aaa") def index1(): sleep(2) return 'hello aaa' @app.route("/bbb") def index2(): sleep(2) return 'hello bbb' @app.route("/ccc") def index3(): sleep(2) return 'hello ccc' app.run()
# 提升requests模块爬取数据的效率 # 普通效果展示 import requests import time headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36" } urls = [ 'http://127.0.0.1:5000/aaa', 'http://127.0.0.1:5000/bbb', 'http://127.0.0.1:5000/ccc', ] start=time.time() for url in urls: page_text=requests.get(url=url,headers=headers).text print(page_text) print(time.time()-start)
# 基于线程池实现异步爬取 from multiprocessing.dummy import Pool #线程池模块 import requests import time headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36" } #必须只有一个参数 def my_requests(url): return requests.get(url=url,headers=headers).text start = time.time() urls = [ 'http://127.0.0.1:5000/aaa', 'http://127.0.0.1:5000/bbb', 'http://127.0.0.1:5000/ccc', ] pool = Pool(3)
#map:两个参数 #参数1:自定义的函数,必须只可以有一个参数 #参数2:列表or字典 #map的作用就是让参数1表示的自定义的函数异步处理参数2对应的列表或者字典中的元素 page_text=pool.map(my_requests,urls) print(page_text) print(time.time()-start)
对比: