课程主页:http://cs231n.stanford.edu/
Introduction to neural networks



-Training Neural Network

_____________________________________________________________________________________________________________________________________________________________________________
-Activation Functions

为什么要把线性转换为非线性?
引用ufldl:


*sigmoid neuron

(引自:http://blog.csdn.net/han_xiaoyang/article/details/50447834):
- sigmoid函数在实际梯度下降中,容易饱和和终止梯度传递。我们来解释一下,大家知道反向传播过程,依赖于计算的梯度,在一元函数中,即斜率。而在sigmoid函数图像上,大家可以很明显看到,在纵坐标接近0和1的那些位置(也就是输入信号的幅度很大的时候),斜率都趋于0了。我们回想一下反向传播的过程,我们最后用于迭代的梯度,是由中间这些梯度值结果相乘得到的,因此如果中间的局部梯度值非常小,直接会把最终梯度结果拉近0,也就是说,残差回传的过程,因为sigmoid函数的饱和被杀死了。说个极端的情况,如果一开始初始化权重的时候,我们取值不是很恰当,而激励函数又全用的sigmoid函数,那么很有可能神经元一个不剩地饱和到无法学习,整个神经网络也根本没办法训练起来。
- sigmoid函数的输出没有
0中心化,这是一个比较闹心的事情,因为每一层的输出都要作为下一层的输入,而未0中心化会直接影响梯度下降,我们这么举个例子吧,如果输出的结果均值不为0,举个极端的例子,全部为正的话(例如 f=wTx+b中所有
f=wTx+b中所有 x>0),那么反向传播回传到W上的梯度将全部为负,这带来的后果是,梯度更新的时候,不是平缓地迭代变化,而是类似锯齿状的突变。当然,要多说一句的是,这个缺点相对于第一个缺点,还稍微好一点,第一个缺点的后果是,很多场景下,神经网络根本没办法学习。
x>0),那么反向传播回传到W上的梯度将全部为负,这带来的后果是,梯度更新的时候,不是平缓地迭代变化,而是类似锯齿状的突变。当然,要多说一句的是,这个缺点相对于第一个缺点,还稍微好一点,第一个缺点的后果是,很多场景下,神经网络根本没办法学习。

*tanh

Tanh函数的图像如上图所示。它会将输入值压缩至-1到1之间,当然,它同样也有sigmoid函数里说到的第一个缺点,在很大或者很小的输入值下,神经元很容易饱和。但是它缓解了第二个缺点,它的输出是0中心化的。所以在实际应用中,tanh激励函数还是比sigmoid要用的多一些的。
*ReLU

ReLU是修正线性单元(The Rectified Linear Unit)的简称,近些年使用的非常多,图像如上图所示。它对于输入x计算![]() f(x)=max(0,x)。换言之,以0为分界线,左侧都为0,右侧是y=x这条直线。
f(x)=max(0,x)。换言之,以0为分界线,左侧都为0,右侧是y=x这条直线。
它有它对应的优势,也有缺点:
- 优点1:实验表明,它的使用,相对于sigmoid和tanh,可以非常大程度地提升随机梯度下降的收敛速度。不过有意思的是,很多人说,这个结果的原因是它是线性的,而不像sigmoid和tanh一样是非线性的。具体的收敛速度结果对比如下图,收敛速度大概能快上6倍:
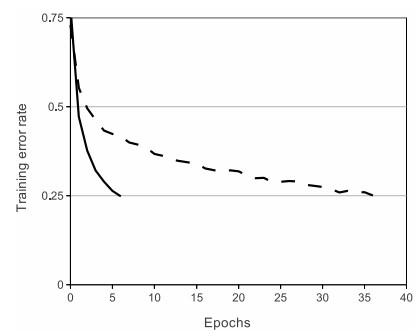
- 优点2:相对于tanh和sigmoid激励神经元,求梯度不要简单太多好么!!!毕竟,是线性的嘛。。。
- 缺点1:ReLU单元也有它的缺点,在训练过程中,它其实挺脆弱的,有时候甚至会挂掉。举个例子说吧,如果一个很大的梯度
流经ReLU单元,那权重的更新结果可能是,在此之后任何的数据点都没有办法再激活它了。一旦这种情况发生,那本应经这个ReLU回传的梯度,将永远变为0。当然,这和参数设置有关系,所以我们要特别小心,再举个实际的例子哈,如果学习速率被设的太高,结果你会发现,训练的过程中可能有高达40%的ReLU单元都挂掉了。所以我们要小心设定初始的学习率等参数,在一定程度上控制这个问题。
*Leaky ReLU

上面不是提到ReLU单元的弱点了嘛,所以孜孜不倦的ML researcher们,就尝试修复这个问题咯,他们做了这么一件事,在x<0的部分,leaky ReLU不再让y的取值为0了,而是也设定为一个坡度很小(比如斜率0.01)的直线。f(x)因此是一个分段函数,x<0时,![]() f(x)=αx(α是一个很小的常数),x>0时,
f(x)=αx(α是一个很小的常数),x>0时,![]() f(x)=x。有一些researcher们说这样一个形式的激励函数帮助他们取得更好的效果,不过似乎并不是每次都比ReLU有优势。
f(x)=x。有一些researcher们说这样一个形式的激励函数帮助他们取得更好的效果,不过似乎并不是每次都比ReLU有优势。
*Maxout

也有一些其他的激励函数,它们并不是对![]() WTX+b做非线性映射
WTX+b做非线性映射![]() f(WTX+b)。一个近些年非常popular的激励函数是Maxout(详细内容请参见Maxout)。简单说来,它是ReLU和Leaky ReLU的一个泛化版本。对于输入x,Maxout神经元计算
f(WTX+b)。一个近些年非常popular的激励函数是Maxout(详细内容请参见Maxout)。简单说来,它是ReLU和Leaky ReLU的一个泛化版本。对于输入x,Maxout神经元计算![]() max(wT1x+b1,wT2x+b2)。有意思的是,如果你仔细观察,你会发现ReLU和Leaky ReLU都是它的一个特殊形式(比如ReLU,你只需要把
max(wT1x+b1,wT2x+b2)。有意思的是,如果你仔细观察,你会发现ReLU和Leaky ReLU都是它的一个特殊形式(比如ReLU,你只需要把![]() w1,b1设为0)。因此Maxout神经元继承了ReLU单元的优点,同时又没有『一不小心就挂了』的担忧。如果要说缺点的话,你也看到了,相比之于ReLU,因为有2次线性映射运算,因此计算量也double了。
w1,b1设为0)。因此Maxout神经元继承了ReLU单元的优点,同时又没有『一不小心就挂了』的担忧。如果要说缺点的话,你也看到了,相比之于ReLU,因为有2次线性映射运算,因此计算量也double了。
*summary

以上就是我们总结的常用的神经元和激励函数类型。顺便说一句,即使从计算和训练的角度看来是可行的,实际应用中,其实我们很少会把多种激励函数混在一起使用。
那我们咋选用神经元/激励函数呢?一般说来,用的最多的依旧是ReLU,但是我们确实得小心设定学习率,同时在训练过程中,还得时不时看看神经元此时的状态(是否还『活着』)。当然,如果你非常担心神经元训练过程中挂掉,你可以试试Leaky ReLU和Maxout。额,少用sigmoid老古董吧,有兴趣倒是可以试试tanh,不过话说回来,通常状况下,它的效果不如ReLU/Maxout。
_____________________________________________________________________________________________________________________________________________________________________________
-Data Preprocessing
*Preprocess the data


*Weight Initialization

learning nothing
随机生成初始W值:

导致反向传递时,由于需要计算对w的偏导,由于x的值太小,所以乘到最前面的层时,结果几乎为0.


但是,如果用relu作为激活函数时,


*batch normalisation
以下引自知乎:
1. What is BN?
顾名思义,batch normalization嘛,就是“批规范化”咯。Google在ICML文中描述的非常清晰,即在每次SGD(stochastic gradient descent)时,通过mini-batch来对相应的activation做规范化操作,使得结果(输出信号各个维度)的均值为0,方差为1. 而最后的“scale and shift”操作则是为了让因训练所需而“刻意”加入的BN能够有可能还原最初的输入(即当
 关于DNN中的normalization,大家都知道白化(whitening),只是在模型训练过程中进行白化操作会带来过高的计算代价和运算时间。因此本文提出两种简化方式:1)直接对输入信号的每个维度做规范化(“normalize each scalar feature independently”);2)在每个mini-batch中计算得到mini-batch mean和variance来替代整体训练集的mean和variance. 这便是Algorithm 1.
关于DNN中的normalization,大家都知道白化(whitening),只是在模型训练过程中进行白化操作会带来过高的计算代价和运算时间。因此本文提出两种简化方式:1)直接对输入信号的每个维度做规范化(“normalize each scalar feature independently”);2)在每个mini-batch中计算得到mini-batch mean和variance来替代整体训练集的mean和variance. 这便是Algorithm 1.2. How to Batch Normalize?
怎样学BN的参数在此就不赘述了,就是经典的chain rule:
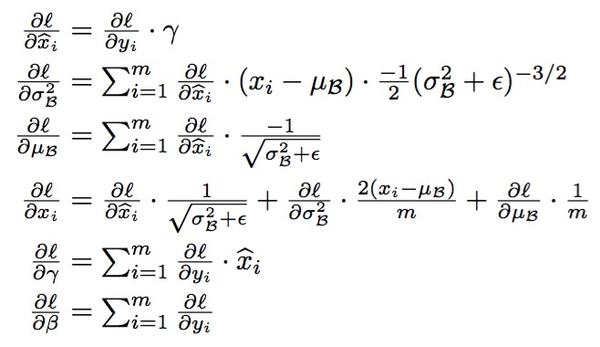
3. Where to use BN?
BN可以应用于网络中任意的activation set。文中还特别指出在CNN中,BN应作用在非线性映射前,即对
4. Why BN?
好了,现在才是重头戏--为什么要用BN?BN work的原因是什么?
说到底,BN的提出还是为了克服深度神经网络难以训练的弊病。其实BN背后的insight非常简单,只是在文章中被Google复杂化了。
首先来说说“Internal Covariate Shift”。文章的title除了BN这样一个关键词,还有一个便是“ICS”。大家都知道在统计机器学习中的一个经典假设是“源空间(source domain)和目标空间(target domain)的数据分布(distribution)是一致的”。如果不一致,那么就出现了新的机器学习问题,如,transfer learning/domain adaptation等。而covariate shift就是分布不一致假设之下的一个分支问题,它是指源空间和目标空间的条件概率是一致的,但是其边缘概率不同,即:对所有
那么好,为什么前面我说Google将其复杂化了。其实如果严格按照解决covariate shift的路子来做的话,大概就是上“importance weight”(ref)之类的机器学习方法。可是这里Google仅仅说“通过mini-batch来规范化某些层/所有层的输入,从而可以固定每层输入信号的均值与方差”就可以解决问题。如果covariate shift可以用这么简单的方法解决,那前人对其的研究也真真是白做了。此外,试想,均值方差一致的分布就是同样的分布吗?当然不是。显然,ICS只是这个问题的“包装纸”嘛,仅仅是一种high-level demonstration。
那BN到底是什么原理呢?说到底还是为了防止“梯度弥散”。关于梯度弥散,大家都知道一个简单的栗子:
5. When to use BN?
OK,说完BN的优势,自然可以知道什么时候用BN比较好。例如,在神经网络训练时遇到收敛速度很慢,或梯度爆炸等无法训练的状况时可以尝试BN来解决。另外,在一般使用情况下也可以加入BN来加快训练速度,提高模型精度。
诚然,在DL中还有许多除BN之外的“小trick”。别看是“小trick”,实则是“大杀器”,正所谓“The devil is in the details”。希望了解其它DL trick(特别是CNN)的各位请移步我之前总结的:Must Know Tips/Tricks in Deep Neural Networks
链接:https://www.zhihu.com/question/38102762/answer/85238569
来源:知乎著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

_____________________________________________________________________________________________________________________________________________________________________________
check:




_________________________________________________________________________________
Hyperparameter Optimization









