(一)使用Docker-compose实现Tomcat+Nginx负载均衡
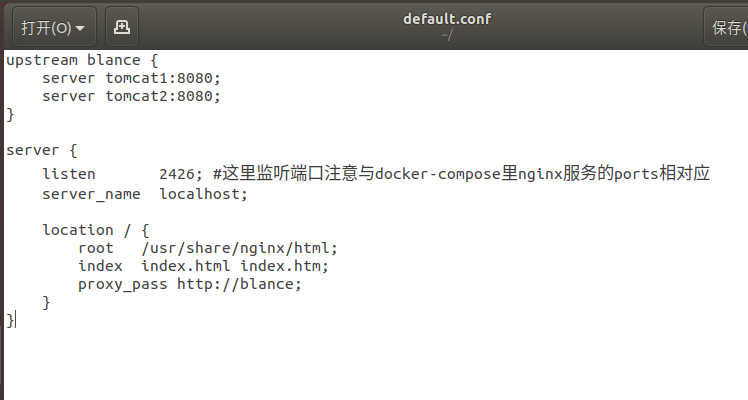
1.nginx.conf
采用最简单的轮询方式
user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
server {
listen 80;
location / {
proxy_pass http://blance;
}
}
upstream blance{
server tomcat01:8080;
server tomcat02:8080;
server tomcat03:8080;
}
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
#gzip on;
include /etc/nginx/conf.d/*.conf;
}
第二种方法 ip hash方式
upstream blance{
ip_hash;
server tomcat01:8080;
server tomcat02:8080;
server tomcat03:8080;
}
2.index.jsp
<%@ page language="java" contentType="text/html; charset=utf-8" import="java.net.InetAddress"
pageEncoding="utf-8"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<title>(一)、Tomcat+Nginx负载均衡</title>
</head>
<body>
<%
InetAddress addr = InetAddress.getLocalHost();
out.println("031702405");
out.println("主机地址:"+addr.getHostAddress()+"<br/>");
out.println("主机名:"+addr.getHostName()+"<br/>");
%>
</body>
</html>
3.docker-compose.yml
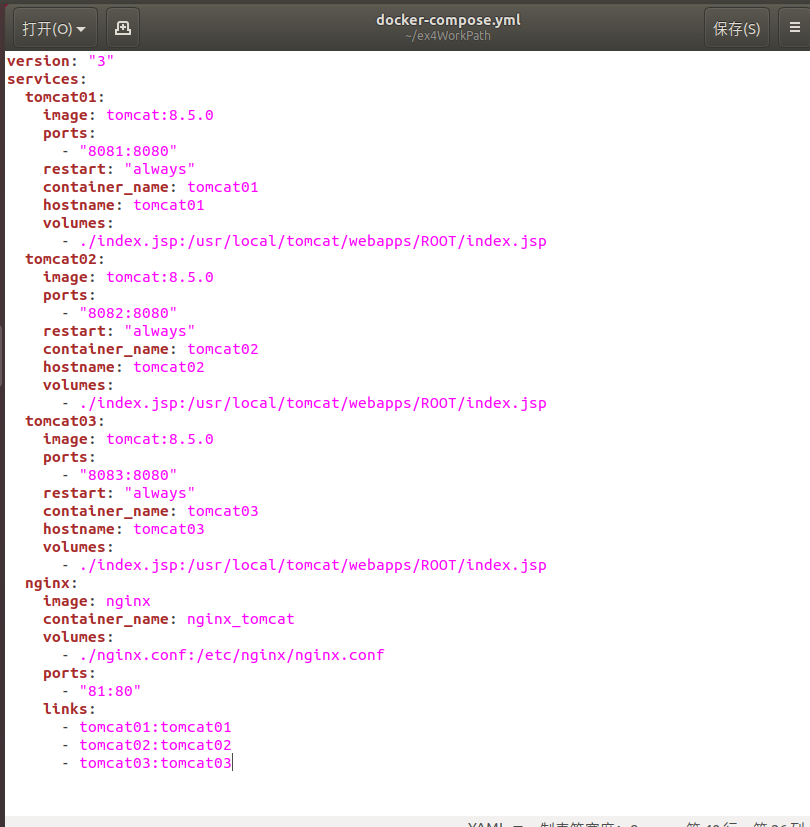
4.启动运行
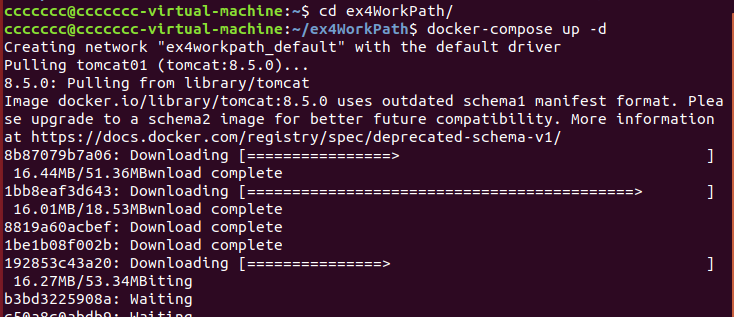
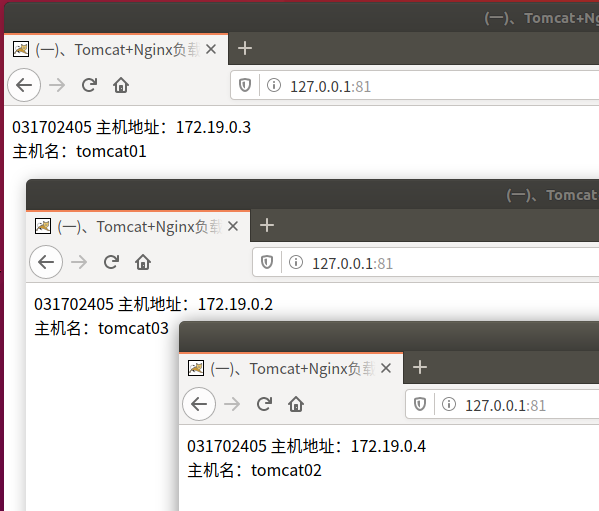
启动成功

可看到三个服务器轮流响应请求
(二)、使用Docker-compose部署javaweb运行环境
1.修改文件
docker-compose.yml

default.conf
设置数据库连接ip
把下载的文件解压后进入文件目录
把 jdbc.properties里的ip修改为本机的ip
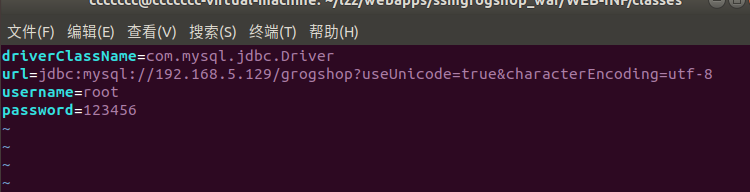
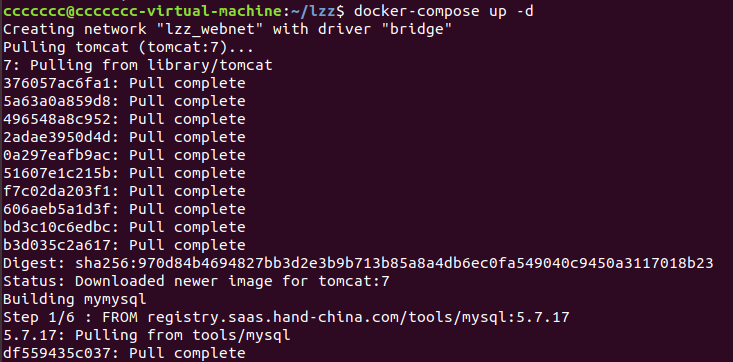
运行

登录
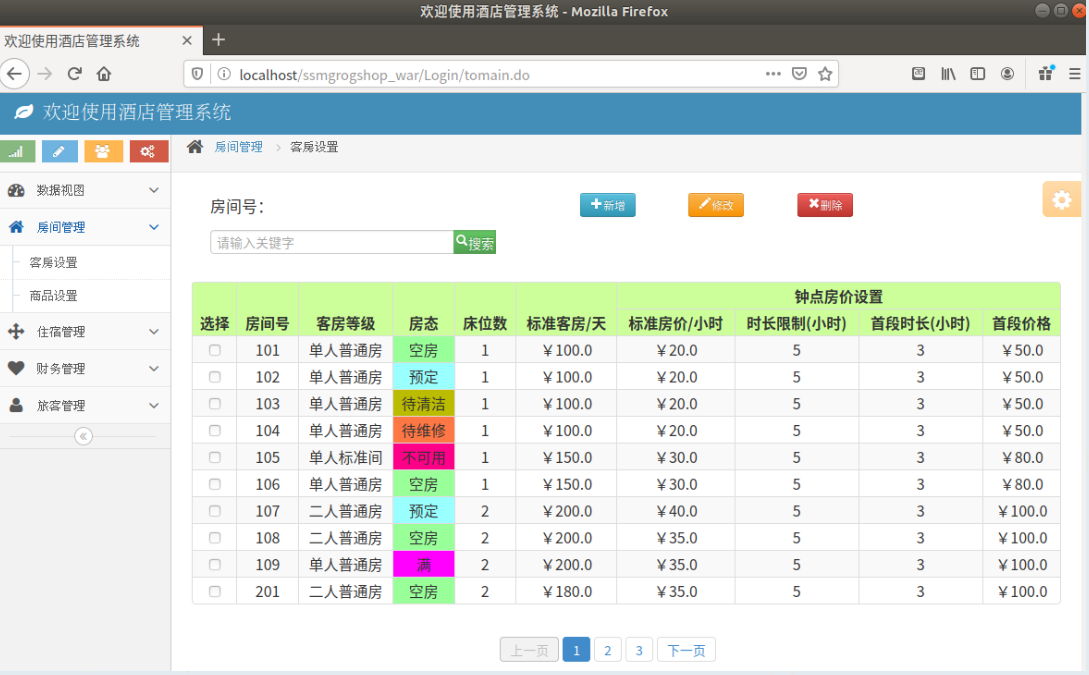
(三)、使用Docker搭建大数据集群环境
1.拉取运行Ubuntu镜像,并配置
拉取Ubuntu镜像(版本18)并运行后,设置自动启动ssh
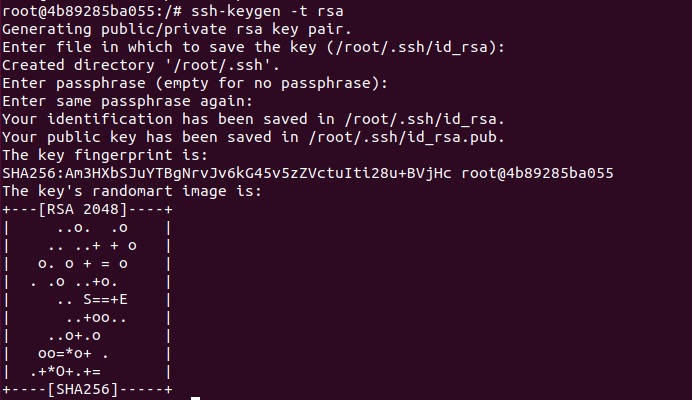
2.配置并授权ssh

3.安装jdk并配置文件


4.commit镜像

5.运行镜像,安装hadoop

因为大数据实践这门课老师直接有给Hadoop安装包,所以直接把这个安装包放在我运行镜像命令里的文件夹中,就会被同步到容器的文件夹中
然后解压即可,通过./bin/hadoop version可查看安装成功

6.配置Hadoop文件
hadoop-env.sh

core-site.xml

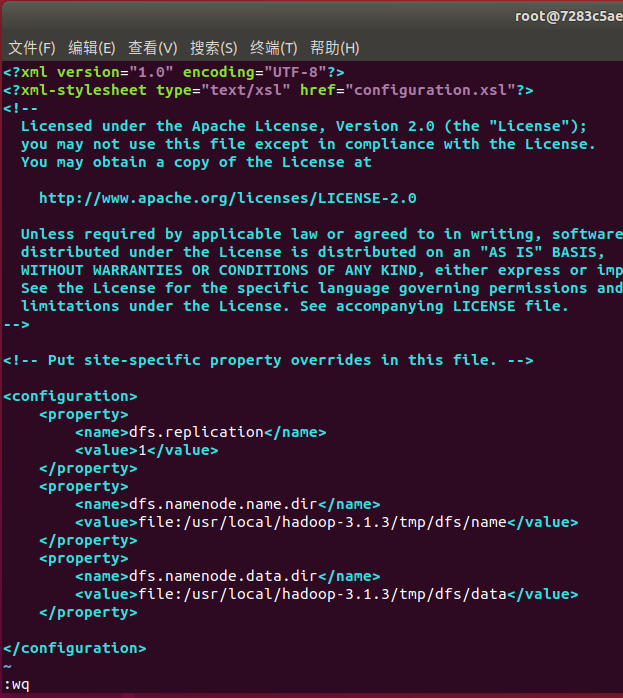
hdfs-site.xml
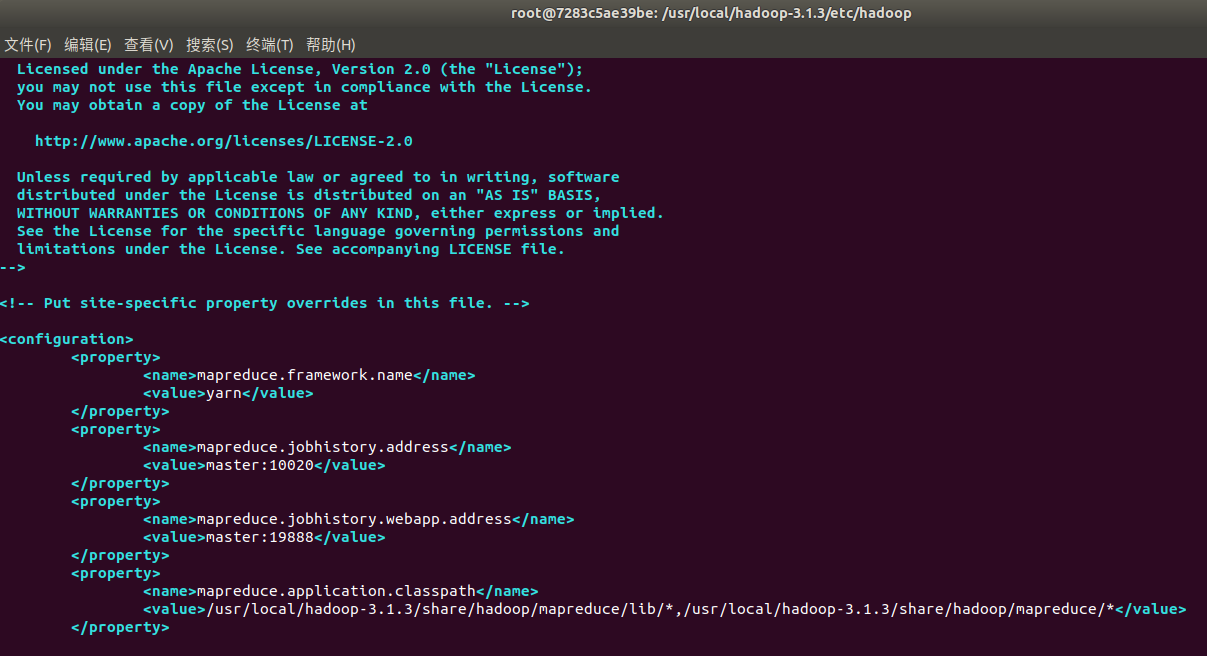
mapred-site.xml
yarn-site.xml

.sh脚本文件
start-dfs.sh和stop-dfs.sh文件:
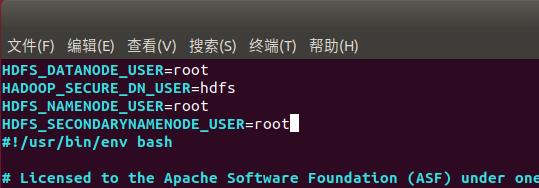
start-yarn.sh和stop-yarn.sh文件:
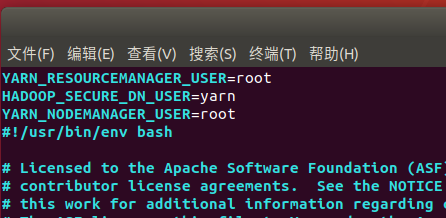
commit当前这个容器

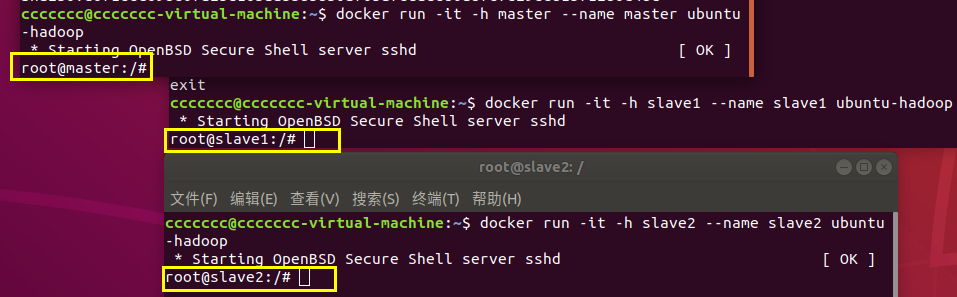
7.运行三个容器
分别创建名为master slave1 slave2的三个容器
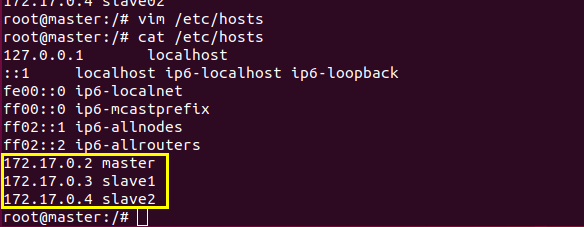
分别修改三个主机的hosts文件
通过cat命令来查看三个容器的ip



分别修改hosts文件

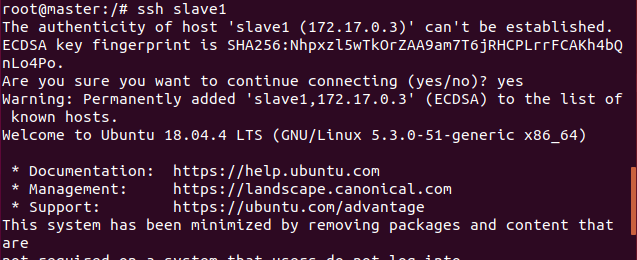
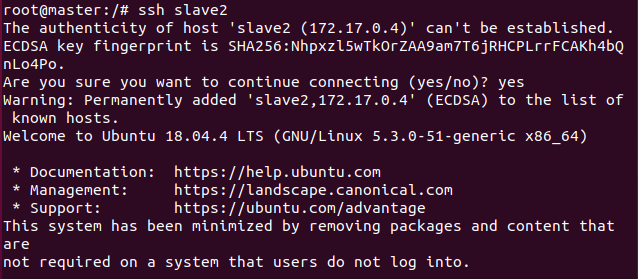
在master上登录slave1和slave2,可以登录
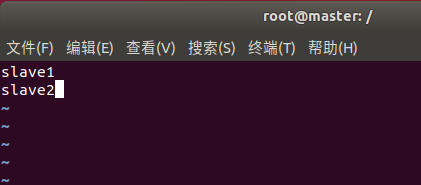
修改master上的workers文件
8.Hadoop集群测试
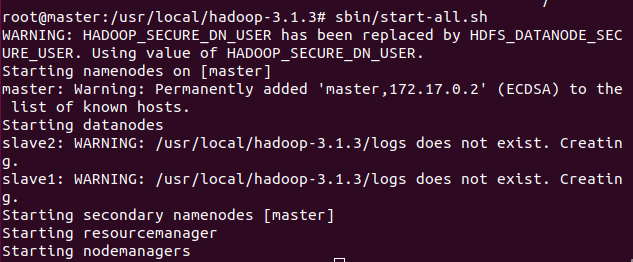
在master上初始化节点

启动服务
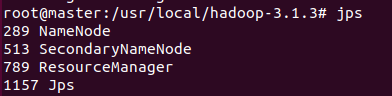
slave1:
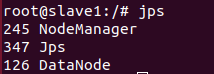
slave2:
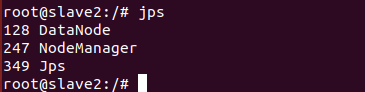
9.测试样例
上传文件
在master上创建文件夹

创建要上传的文件test.txt,并把它放在这个文件夹


测试文件
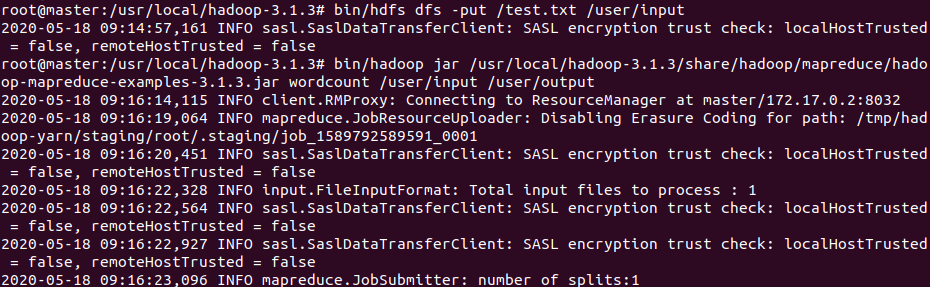
查看结果

(四)、总结
遇到的问题
1.
不会JavaWeb,然后就使用了参考案例
2.
在Hadoop运行wordcount时爆内存,虚拟机直接卡死了,只能关机重新调内存,把内存调到4.9GB发现可以运行了
3.重启虚拟机之后执行start-all.sh时,在另
外两台slave上没有datanodes
解决办法:把这三个容器删除,重新运行就可以了
实验时长
四天 共16个小时