在《Python爬虫实战—— Request对象之header伪装策略》中,我们就已经讲到:“在header当中,我们经常会添加两个参数——cookie 和 User-Agent,来模拟浏览器登录,以此提高绕过后台服务器反爬策略的可能性。”
User-Agent已经讲过,这篇我们则主要讲cookie的使用案例。
通俗地讲:User-Agent的作用是模拟浏览器,cookie的作用是模拟登陆,所以二者合起来,便是模拟浏览器登录啦。
为了方便理解,现在我们试一下爬取CSDN学院中自己的收藏的课程。
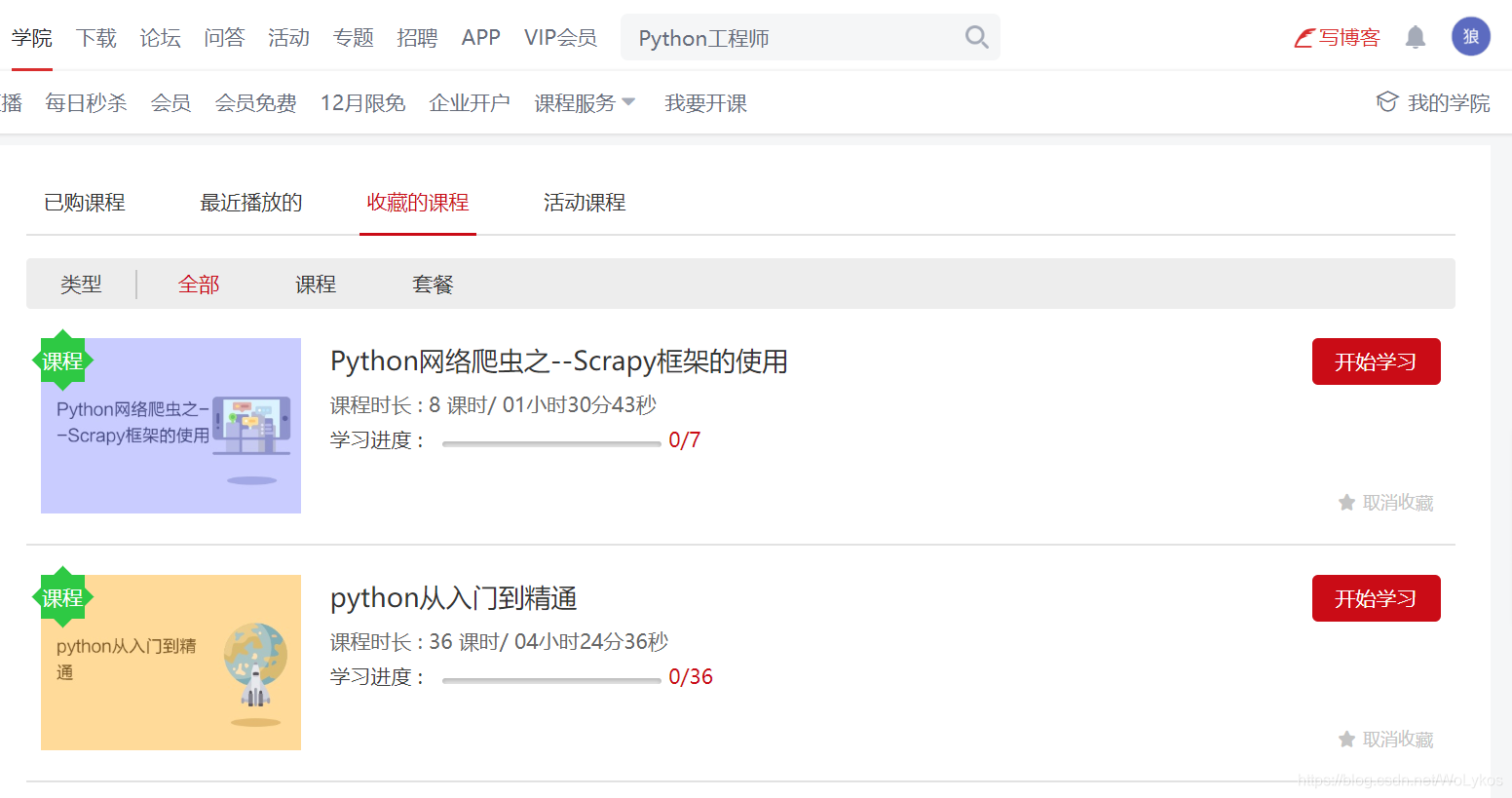
1. 为了验证,我麻溜地瞎收藏了几个课程:
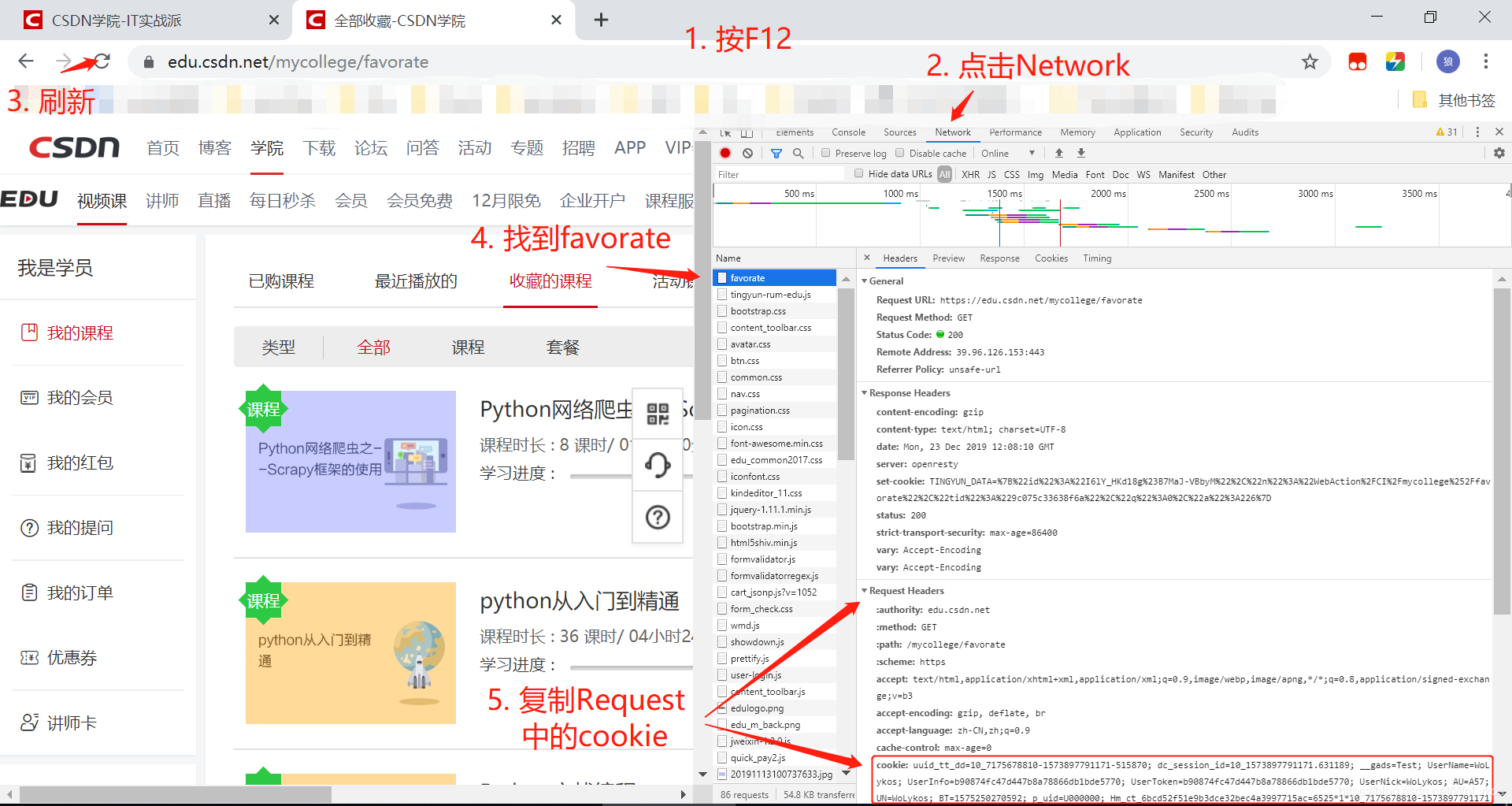
2. 获取cookie:
3. 创建一个request对象:
import urllib.request as ur
import user_agent
import lxml.etree as le
request = ur.Request(
url='https://edu.csdn.net/mycollege/favorate',
headers={
'User-Agent': user_agent.get_user_agent_pc(),
'Cookie': 'uuid_tt_dd=10_7175678810-1573897791171-515870; dc_session_id=10_1573897791171.631189; __gads=Test; UserName=WoLykos; UserInfo=b90874fc47d447b8a78866db1bde5770; UserToken=b90874fc47d447b8a78866db1bde5770; UserNick=WoLykos; AU=A57; UN=WoLykos; BT=1575250270592; p_uid=U000000; Hm_ct_6bcd52f51e9b3dce32bec4a3997715ac=6525*1*10_7175678810-1573897791171-515870!5744*1*WoLykos; acw_tc=2760823f15766000004357185efdb2fe81badf98c5418fdaaa006c8fb641e2; UM_distinctid=16f1e154f3e6fc-06a15022d8e2cb-7711a3e-e1000-16f1e154f3f80c; Hm_lvt_e5ef47b9f471504959267fd614d579cd=1576843409; Hm_ct_e5ef47b9f471504959267fd614d579cd=5744*1*WoLykos!6525*1*10_7175678810-1573897791171-515870; __yadk_uid=BWljcDoqISiHxWKSFRvypn90shczp7Ay; firstDie=1; ADHOC_MEMBERSHIP_CLIENT_ID1.0=fa924465-1b26-cf9e-e00b-4ca8a6fe68e2; Hm_lvt_6bcd52f51e9b3dce32bec4a3997715ac=1576889587,1577070936,1577087859,1577098502; PHPSESSID=5nfs1s5g2kl8hiot0duljcaao6; TY_SESSION_ID=820b1d6d-9ef0-4d5b-8dea-a74643320a77; cname10651=1; dc_tos=q2ys77; Hm_lpvt_6bcd52f51e9b3dce32bec4a3997715ac=1577102659; announcement=%257B%2522isLogin%2522%253Atrue%252C%2522announcementUrl%2522%253A%2522https%253A%252F%252Fblog.csdn.net%252Fblogdevteam%252Farticle%252Fdetails%252F103603408%2522%252C%2522announcementCount%2522%253A0%252C%2522announcementExpire%2522%253A3600000%257D',
}
)
4. 将response结果写入到本地文件:
response = ur.urlopen(request).read().decode('utf-8')
# 由于response是字符串类型,所以此处只需‘w’即可
with open('myfavorate.html', 'w', encoding='utf-8') as f:
f.write(response)
结果如下:
5. 如果注释掉cookie又会如何呢:
import urllib.request as ur
import user_agent
import lxml.etree as le
request = ur.Request(
url='https://edu.csdn.net/mycollege/favorate',
headers={
'User-Agent': user_agent.get_user_agent_pc(),
}
)
response = ur.urlopen(request).read().decode('utf-8')
# 由于response是字符串类型,所以此处只需‘w’即可
with open('myfavorate2.html', 'w', encoding='utf-8') as f:
f.write(response)
结果如下:

注意:
这是一个重定向,转至CSDN的登录界面。
6. 利用XPath提取课程名称:
import lxml.etree as le
# 加载文本内容
html_x = le.HTML(response)
# 提取当前用户收藏的课程名称
title_s = html_x.xpath('//li[@class="item_box"]//h1/a/text()')
print(title_s)
输出如下:

全文完整代码:
import urllib.request as ur
import user_agent
import lxml.etree as le
request = ur.Request(
url='https://edu.csdn.net/mycollege/favorate',
headers={
'User-Agent': user_agent.get_user_agent_pc(),
'Cookie': 'uuid_tt_dd=10_7175678810-1573897791171-515870; dc_session_id=10_1573897791171.631189; __gads=Test; UserName=WoLykos; UserInfo=b90874fc47d447b8a78866db1bde5770; UserToken=b90874fc47d447b8a78866db1bde5770; UserNick=WoLykos; AU=A57; UN=WoLykos; BT=1575250270592; p_uid=U000000; Hm_ct_6bcd52f51e9b3dce32bec4a3997715ac=6525*1*10_7175678810-1573897791171-515870!5744*1*WoLykos; acw_tc=2760823f15766000004357185efdb2fe81badf98c5418fdaaa006c8fb641e2; UM_distinctid=16f1e154f3e6fc-06a15022d8e2cb-7711a3e-e1000-16f1e154f3f80c; Hm_lvt_e5ef47b9f471504959267fd614d579cd=1576843409; Hm_ct_e5ef47b9f471504959267fd614d579cd=5744*1*WoLykos!6525*1*10_7175678810-1573897791171-515870; __yadk_uid=BWljcDoqISiHxWKSFRvypn90shczp7Ay; firstDie=1; ADHOC_MEMBERSHIP_CLIENT_ID1.0=fa924465-1b26-cf9e-e00b-4ca8a6fe68e2; Hm_lvt_6bcd52f51e9b3dce32bec4a3997715ac=1576889587,1577070936,1577087859,1577098502; PHPSESSID=5nfs1s5g2kl8hiot0duljcaao6; TY_SESSION_ID=820b1d6d-9ef0-4d5b-8dea-a74643320a77; cname10651=1; dc_tos=q2ys77; Hm_lpvt_6bcd52f51e9b3dce32bec4a3997715ac=1577102659; announcement=%257B%2522isLogin%2522%253Atrue%252C%2522announcementUrl%2522%253A%2522https%253A%252F%252Fblog.csdn.net%252Fblogdevteam%252Farticle%252Fdetails%252F103603408%2522%252C%2522announcementCount%2522%253A0%252C%2522announcementExpire%2522%253A3600000%257D',
}
)
response = ur.urlopen(request).read().decode('utf-8')
# 由于response是字符串类型,所以此处只需‘w’即可
# with open('myfavorate2.html', 'w', encoding='utf-8') as f:
# f.write(response)
# 加载文本内容
html_x = le.HTML(response)
# 提取当前用户收藏的课程名称
title_s = html_x.xpath('//li[@class="item_box"]//h1/a/text()')
print(title_s)
为我心爱的女孩~~