1、get请求的quote方法 : 将str数据转换为对应编码
urllib.parse.quote 将str数据转换为对应编码
urllib.parse.unquote 将编码后的数据转换为编码前的数据
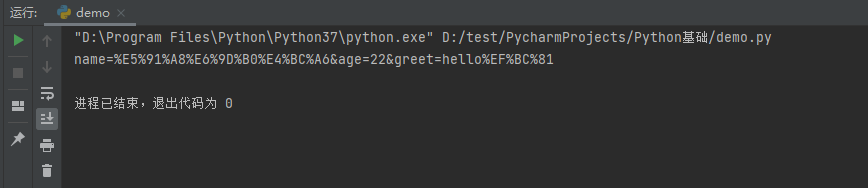
#https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6 # 需求 获取 https://www.baidu.com/s?wd=周杰伦的网页源码 import urllib.request import urllib.parse url = 'https://www.baidu.com/s?wd=' # 请求对象的定制为了解决反爬的第一种手段 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36' } # 依赖urllib.parse.quote 将周杰伦三个字变成unicode的编码格式 name = urllib.parse.quote('周杰伦') url = url + name # 请求对象的定制 request = urllib.request.Request(url=url,headers=headers) # 模拟浏览器向服务器发送请求 response = urllib.request.urlopen(request) # 获取响应的内容 content = response.read().decode('utf-8') # 打印数据 print(content)
-
运行结果
2、urlencode 方法:将字典中key:value转换为key=编码后的value
import urllib.parse
data = {'name': '周杰伦',
'age': 22,
'greet': 'hello!'}
dt = urllib.parse.urlencode(data)
print(dt)
-
运行结果