磁盘阵列(Redundant Arrays of Independent Disks,RAID),有“独立磁盘构成的具有冗余能力的阵列”之意,,数据读取无影响。将数据切割成许多区段,分别存放在各个硬盘上。 磁盘阵列还能利用同位检查(Parity Check)的观念,在数组中任意一个硬盘故障时,仍可读出数据...硬件用的多。
注:RAID可以预防数据丢失,但是它并不能完全保证你的数据不会丢失,所以大家使用RAID的同时还是注意备份重要的数据
RAID的创建有两种方式:软RAID(通过操作系统软件来实现)和硬RAID(使用硬件阵列卡);了解raid1、raid5和raid10。不过随着云的高速发展,供应商一般可以把硬件问题解决掉。
RAID几种常见的类型
|
RAID类型 |
最低磁盘个数 |
空间利用率 |
各自的优缺点 |
|
|
级 别 |
说 明 |
|||
|
RAID0 |
条带卷 |
2+ |
100% |
读写速度快,不容错 |
|
RAID1 |
镜像卷 |
2 |
50% |
读写速度一般,容错 |
|
RAID5 |
带奇偶校验的条带卷 |
3+ |
(n-1)/n |
读写速度快,容错,允许坏一块盘 |
|
RAID10 |
RAID1的安全+RAID0的高速 |
4 |
50% |
读写速度快,容错 |
RAID基本思想:把好几块硬盘通过一定组合方式把它组合起来,成为一个新的硬盘阵列组,从而使它能够达到高性能硬盘的要求
RAID有三个关键技术:
镜像:提供了数据的安全性;
条带(块大小也可以说是条带的粒度),它的存在的就是提供了数据并发性
数据的校验:提供了数据的安全
Raid相对于单个磁盘优点:
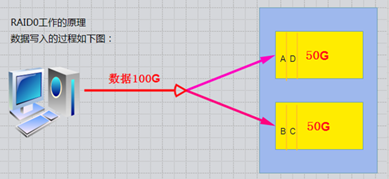
RAID-0的工作原理
条带 (strping),最早出现,需磁盘数量:2块以上(大小最好相同),是组建磁盘阵列中最简单的一种形式、
特点:成本低,可以提高整个磁盘的性能。RAID 0没有提供冗余或错误修复能力,速度快.
任何一个磁盘的损坏将损坏全部数据;磁盘利用率为100%。

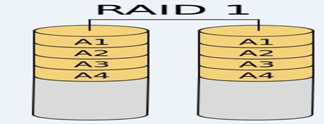
RAID-1
mirroring(镜像卷),需要磁盘两块以上
原理:是把一个磁盘的数据镜像到另一个磁盘上,(同步复制备份)
RAID 1 mirroring(镜像卷),至少需要两块硬盘
磁盘利用率为50%,即2块100G的磁盘构成RAID1只能提供100G的可用空间。如下图
RAID-5
需要三块或以上硬盘,可以提供热备盘实现故障的恢复;只损坏一块,没有问题。但如果同时损坏两块磁盘,则数据将都会损坏。 空间利用率: (n-1)/n 少一块磁盘,这块少的作了热备盘,存放校验码和算法, 2/3 如下图所示
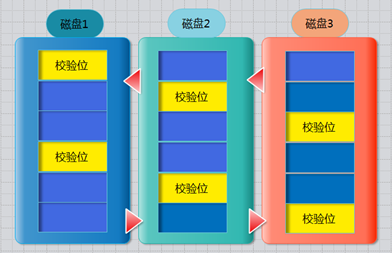
奇偶校验信息的作用:
当RAID5的一个磁盘数据发生损坏后,利用剩下的数据和相应的奇偶校验信息去恢复被损坏的数据。是一种数据算法。
扩展:异或运算
所谓的“奇偶校验”可以简单理解为二进制运算中的“异或运算”,通常用 xor 标识。
最左边的是原始数据,右边分别是三块硬盘,假设第二块硬盘出了故障,通过第一块硬盘上的 1 和第三块硬盘上的 1 xor 2,就能够还原出 2。同理可以还原出 3 和 8。至于 5 xor 6 则更简单了,直接用 5 和 6 运算出来即可。
一句话解释 raid 5 的数据恢复原理就是:都是用公式算出来的。
嵌套RAID级别
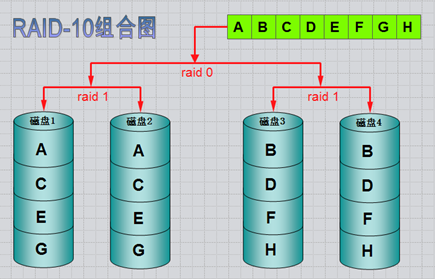
RAID-10镜像+条带
RAID 10是将镜像和条带进行两级组合的RAID级别,第一级是RAID1镜像对,第二级为RAID 0。比如我们有8块盘,它是先两两做镜像,形成了新的4块盘,然后对这4块盘做RAID0;当RAID10有一个硬盘受损其余硬盘会继续工作,这个时候受影响的硬盘只有2块,允许坏一半。
数据比金钱更重要DBA。
RAID硬盘失效处理
一般两种处理方法:热备和热插拔
热备:HotSpare
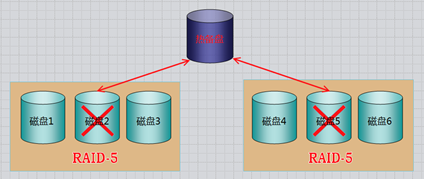
定义:当冗余的RAID组中某个硬盘失效时,在不干扰当前RAID系统的正常使用的情况下,用RAID系统中另外一个正常的备用硬盘自动顶替失效硬盘,及时保证RAID系统的冗余性
全局式:备用硬盘为系统中所有的冗余RAID组共享
专用式:备用硬盘为系统中某一组冗余RAID组专用
如下图所示:是一个全局热备的示例,该热备盘由系统中两个RAID组共享,可自动顶替任何一个RAID中的一个失效硬盘
热插拔:HotSwap
定义:在不影响系统正常运转的情况下,用正常的物理硬盘替换RAID系统中失效硬盘。
RAID-0-1-5-10搭建及使用-删除RAID及注意事项
RAID的实现方式
面试题:我们做硬件RAID,是在装系统前还是之后?
答:先做阵列才装系统 ,一般服务器启动时,有显示进入配置Riad的提示。
硬RAID:需要RAID卡,我们的磁盘是接在RAID卡的,由它统一管理和控制。数据也由它来进行分配和维护;它有自己的cpu,处理速度快
软RAID:通过操作系统实现
Mdadm命令详解
用软件实现RAID。
Linux内核中有一个md(multiple devices)模块在底层管理RAID设备,它会在应用层给我们提供一个应用程序的工具mdadm ,mdadm是linux下用于创建和管理软件RAID的命令。
mdadm命令常见参数解释:
|
参数 |
作用 |
|
-a |
检测设备名称 添加磁盘 |
|
-n |
指定设备数量 |
|
-l |
指定RAID级别 |
|
-C |
创建 |
|
-v |
显示过程 |
|
-f |
模拟设备损坏 |
|
-r |
移除设备 |
|
-Q |
查看摘要信息 |
|
-D |
查看详细信息 |
|
-S |
停止RAID磁盘阵列 |
互动: raid5需要3块硬盘。 那么使用4块硬盘,可以做raid5吗?
可以的
实战搭建raid10阵列
新添加4块硬盘,添加过程一直点击下一步即可

第一步:查看磁盘
[root@ken ~]# ls /dev/sd* /dev/sda /dev/sda1 /dev/sda2 /dev/sdb /dev/sdc /dev/sdd /dev/sde
做一张快照。
第二步:下载mdadm
[root@ken ~]# yum install mdadm -y
第三步:创建raid10阵列

[root@ken ~]# mdadm -Cv /dev/md0 -a yes -n 4 -l 10 /dev/sd{b,c,d,e}
mdadm: layout defaults to n2
mdadm: layout defaults to n2
mdadm: chunk size defaults to 512K
mdadm: size set to 20954112K
mdadm: Fail create md0 when using /sys/module/md_mod/parameters/new_array
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
指定的阵列名称md10和raid10保持数字一致
查看磁盘创建详细信息 :# mdadm -D /dev/md10 过程较慢
第四步:格式磁盘阵列为ext4 (格式化后才能使用)
[root@ken ~]# mkfs.ext4 /dev/md0
mapper/ mcelog md0 mem midi mqueue/
[root@ken ~]# mkfs.ext4 /dev/md0
mke2fs 1.42.9 (28-Dec-2013)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=128 blocks, Stripe width=256 blocks
2621440 inodes, 10477056 blocks
523852 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=2157969408
320 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624
Allocating group tables: done
Writing inode tables: done
Creating journal (32768 blocks): done
Writing superblocks and filesystem accounting information: done
进行挂载: # mkfs.xfs /dev/md10
# mkdir /ken # mount /dev/md10 /ken # df -h (50%)
设置开机自启 :# vim /etc/fstab (/dev/md10 /ken xfs defaults 0 0)
第五步:挂载
[root@ken ~]# mkdir /raid10 [root@ken ~]# mount /dev/md0 /raid10 [root@ken ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/mapper/centos-root 17G 1.2G 16G 7% / devtmpfs 224M 0 224M 0% /dev tmpfs 236M 0 236M 0% /dev/shm tmpfs 236M 5.6M 230M 3% /run tmpfs 236M 0 236M 0% /sys/fs/cgroup /dev/sda1 1014M 130M 885M 13% /boot tmpfs 48M 0 48M 0% /run/user/0 /dev/md0 40G 49M 38G 1% /raid10
第六步:查看/dev/md0的详细信息
[root@ken ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Thu Feb 28 19:08:25 2019
Raid Level : raid10
Array Size : 41908224 (39.97 GiB 42.91 GB)
Used Dev Size : 20954112 (19.98 GiB 21.46 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Thu Feb 28 19:11:41 2019
State : clean, resyncing
Active Devices : 4
Working Devices : 4
Failed Devices : 0
Spare Devices : 0
Layout : near=2
Chunk Size : 512K
Consistency Policy : resync
Resync Status : 96% complete
Name : ken:0 (local to host ken)
UUID : c5df1175:a6b1ad23:f3d7e80b:6b56fe98
Events : 26
Number Major Minor RaidDevice State
0 8 16 0 active sync set-A /dev/sdb
1 8 32 1 active sync set-B /dev/sdc
2 8 48 2 active sync set-A /dev/sdd
3 8 64 3 active sync set-B /dev/sde
第七步:写入到配置文件中
[root@ken ~]# echo "/dev/md0 /raid10 ext4 defaults 0 0" >> /etc/fstab
损坏磁盘阵列及修复
之所以在生产环境中部署RAID 10磁盘阵列,是为了提高硬盘存储设备的读写速度及数据的安全性,但由于我们的硬盘设备是在虚拟机中模拟出来的,因此对读写速度的改善可能并不直观。
在确认有一块物理硬盘设备出现损坏而不能继续正常使用后,应该使用mdadm命令将其移除,然后查看RAID磁盘阵列的状态,可以发现状态已经改变。
第一步:模拟设备损坏
[root@ken ~]# mdadm /dev/md0 -f /dev/sdb
mdadm: set /dev/sdb faulty in /dev/md0
[root@ken ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Thu Feb 28 19:08:25 2019
Raid Level : raid10
Array Size : 41908224 (39.97 GiB 42.91 GB)
Used Dev Size : 20954112 (19.98 GiB 21.46 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Thu Feb 28 19:15:59 2019
State : clean, degraded
Active Devices : 3
Working Devices : 3
Failed Devices : 1
Spare Devices : 0
Layout : near=2
Chunk Size : 512K
Consistency Policy : resync
Name : ken:0 (local to host ken)
UUID : c5df1175:a6b1ad23:f3d7e80b:6b56fe98
Events : 30
Number Major Minor RaidDevice State
- 0 0 0 removed
1 8 32 1 active sync set-B /dev/sdc
2 8 48 2 active sync set-A /dev/sdd
3 8 64 3 active sync set-B /dev/sde
0 8 16 - faulty /dev/sdb
第二步:添加新的磁盘
在RAID 10级别的磁盘阵列中,当RAID 1磁盘阵列中存在一个故障盘时并不影响RAID 10磁盘阵列的使用。当购买了新的硬盘设备后再使用mdadm命令来予以替换即可,在此期间我们可以在/RAID目录中正常地创建或删除文件。由于我们是在虚拟机中模拟硬盘,所以先重启系统,然后再把新的硬盘添加到RAID磁盘阵列中。
[root@ken ~]# reboot
[root@ken ~]# umount /raid10
[root@ken ~]# mdadm /dev/md0 -a /dev/sdb
mdadm: added /dev/sdb
[root@ken ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Thu Feb 28 19:08:25 2019
Raid Level : raid10
Array Size : 41908224 (39.97 GiB 42.91 GB)
Used Dev Size : 20954112 (19.98 GiB 21.46 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Thu Feb 28 19:19:14 2019
State : clean, degraded, recovering
Active Devices : 3
Working Devices : 4
Failed Devices : 0
Spare Devices : 1
Layout : near=2
Chunk Size : 512K
Consistency Policy : resync
Rebuild Status : 7% complete #这里显示重建进度
Name : ken:0 (local to host ken)
UUID : c5df1175:a6b1ad23:f3d7e80b:6b56fe98
Events : 35
Number Major Minor RaidDevice State
4 8 16 0 spare rebuilding /dev/sdb #rebuilding重建中
1 8 32 1 active sync set-B /dev/sdc
2 8 48 2 active sync set-A /dev/sdd
3 8 64 3 active sync set-B /dev/sde
再次查看发现已经构建完毕
[root@ken ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Thu Feb 28 19:08:25 2019
Raid Level : raid10
Array Size : 41908224 (39.97 GiB 42.91 GB)
Used Dev Size : 20954112 (19.98 GiB 21.46 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Thu Feb 28 19:20:52 2019
State : clean
Active Devices : 4
Working Devices : 4
Failed Devices : 0
Spare Devices : 0
Layout : near=2
Chunk Size : 512K
Consistency Policy : resync
Name : ken:0 (local to host ken)
UUID : c5df1175:a6b1ad23:f3d7e80b:6b56fe98
Events : 51
Number Major Minor RaidDevice State
4 8 16 0 active sync set-A /dev/sdb
1 8 32 1 active sync set-B /dev/sdc
2 8 48 2 active sync set-A /dev/sdd
3 8 64 3 active sync set-B /dev/sde
模拟磁盘损坏:
查看详细信息:# mdadm -D /dev/md10 选择模拟损坏的磁盘
# mdadm /dev/md10 -f /dev/sde # mdadm -D /dev md10 (磁盘已损坏)
# poweroff 关机 (在实际中,需要关机拿掉坏的磁盘,换上新的磁盘,不能自动识别)
还需要手动添加先查看: # mdadm -D /dev/md10
添加:# mdadm /dev/md10 -a /dev/sde (a = add)
查看:# mdadm -D /dev/md10 (Rebuild Status :显示数据同步状况)
实战搭建 raid5 阵列+备份盘
(命令做阵列仅供了解)
为了避免多个实验之间相互发生冲突,我们需要保证每个实验的相对独立性,为此需要大家自行将虚拟机还原到初始状态。另外,由于刚才已经演示了RAID 10磁盘阵列的部署方法,我们现在来看一下RAID 5的部署效果。部署RAID 5磁盘阵列时,至少需要用到3块硬盘,还需要再加一块备份硬盘,所以总计需要在虚拟机中模拟4块硬盘设备。
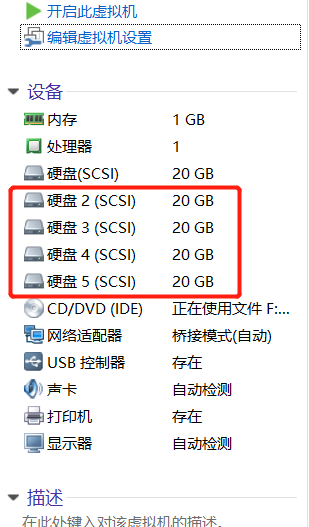
第一步:查看磁盘
[root@ken ~]# ls /dev/sd* /dev/sda /dev/sda1 /dev/sda2 /dev/sdb /dev/sdc /dev/sdd /dev/sde
第二步:创建RAID5阵列
[root@ken ~]# mdadm -Cv /dev/md0 -n 3 -l 5 -x 1 /dev/sd{b,c,d,e}
mdadm: layout defaults to left-symmetric
mdadm: layout defaults to left-symmetric
mdadm: chunk size defaults to 512K
mdadm: size set to 20954112K
mdadm: Fail create md0 when using /sys/module/md_mod/parameters/new_array
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
# mdadm -D /dev/md5 备份的磁盘 e 显示 spare 状态。
设置备份:# mdadm /dev/md5 -f /dev/sdd (模拟 sdd 盘损坏)
查看: # mdadm -D /dev/md5 (sde 替代sdd 的位置) 数据开始备份。
第三步:格式化为ext4
[root@ken ~]# mkfs.ext4 /dev/md0
mke2fs 1.42.9 (28-Dec-2013)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=128 blocks, Stripe width=256 blocks
2621440 inodes, 10477056 blocks
523852 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=2157969408
320 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624
Allocating group tables: done
Writing inode tables: done
Creating journal (32768 blocks): done
Writing superblocks and filesystem accounting information: done
第四步:挂载
[root@ken ~]# mount /dev/md0 /raid5 [root@ken ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/mapper/centos-root 17G 1.2G 16G 7% / devtmpfs 476M 0 476M 0% /dev tmpfs 488M 0 488M 0% /dev/shm tmpfs 488M 7.7M 480M 2% /run tmpfs 488M 0 488M 0% /sys/fs/cgroup /dev/sda1 1014M 130M 885M 13% /boot tmpfs 98M 0 98M 0% /run/user/0 /dev/md0 40G 49M 38G 1% /raid5
第五步:查看阵列信息
可以发现有一个备份盘/dev/sde
[root@ken ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Thu Feb 28 19:35:10 2019
Raid Level : raid5
Array Size : 41908224 (39.97 GiB 42.91 GB)
Used Dev Size : 20954112 (19.98 GiB 21.46 GB)
Raid Devices : 3
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Thu Feb 28 19:37:11 2019
State : active
Active Devices : 3
Working Devices : 4
Failed Devices : 0
Spare Devices : 1
Layout : left-symmetric
Chunk Size : 512K
Consistency Policy : resync
Name : ken:0 (local to host ken)
UUID : b693fe72:4452bd3f:4d995779:ee33bc77
Events : 76
Number Major Minor RaidDevice State
0 8 16 0 active sync /dev/sdb
1 8 32 1 active sync /dev/sdc
4 8 48 2 active sync /dev/sdd
3 8 64 - spare /dev/sde
第六步:模拟/dev/sdb磁盘损坏
可以发现/dev/sde备份盘立即开始构建
[root@ken ~]# mdadm /dev/md0 -f /dev/sdb
mdadm: set /dev/sdb faulty in /dev/md0
[root@ken ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Thu Feb 28 19:35:10 2019
Raid Level : raid5
Array Size : 41908224 (39.97 GiB 42.91 GB)
Used Dev Size : 20954112 (19.98 GiB 21.46 GB)
Raid Devices : 3
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Thu Feb 28 19:38:41 2019
State : active, degraded, recovering
Active Devices : 2
Working Devices : 3
Failed Devices : 1
Spare Devices : 1
Layout : left-symmetric
Chunk Size : 512K
Consistency Policy : resync
Rebuild Status : 2% complete
Name : ken:0 (local to host ken)
UUID : b693fe72:4452bd3f:4d995779:ee33bc77
Events : 91
Number Major Minor RaidDevice State
3 8 64 0 spare rebuilding /dev/sde
1 8 32 1 active sync /dev/sdc
4 8 48 2 active sync /dev/sdd
0 8 16 - faulty /dev/sdb
centos7系统启动过程及相关配置文件
应对面试
1.uefi或BIOS初始化,开始post(power on self test)开机自检内存、磁盘、CPU等。(UEFI更高级,但常用BIOS)
2.加载MBR(512字节)到内存,Boot sequence 选择引导顺序。(光盘启动、硬盘启动、网络启动、U盘启动等,已在BIOS中设定好第一启动项),
在虚拟机中,关机状态下,电源--打开电源时进入固件--Boot--选择第一启动项,F10,,其中,由光盘启动可进入救援模式(root密码忘记可进入修改)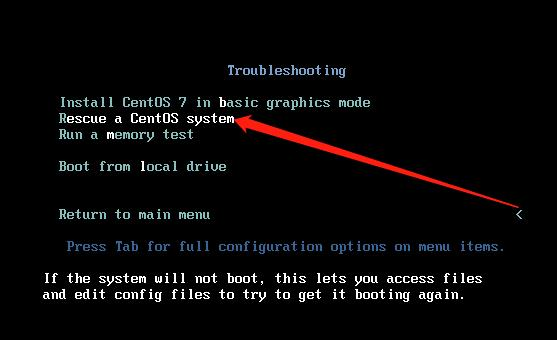
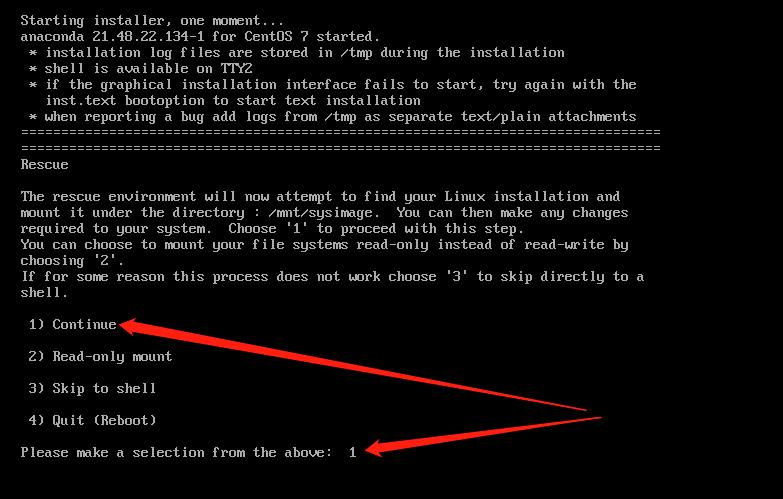
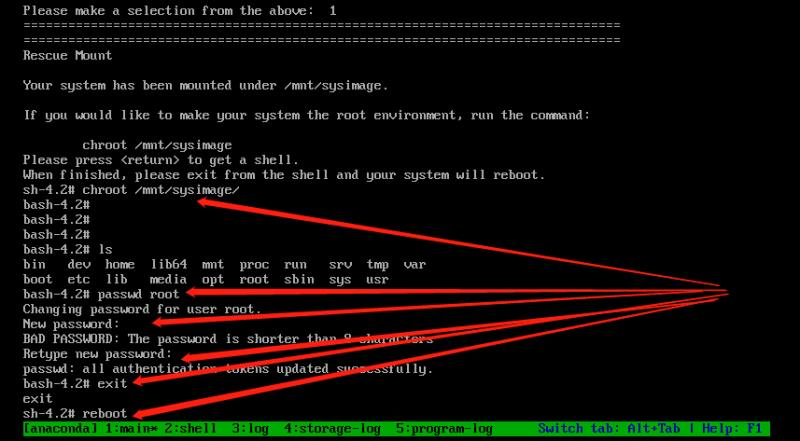
3.GRUB阶段,Bootloader(446字节) :引导加载器。引导用户选择要启动的系统或不同的内核版本。
4.加载内核和initramfs模块,KERNEL开始初始化,探测可识别的硬件设备,加载硬件启动程序。
5.内核开始初始化,在centOS7上使用systemd来代替centos6以前的init程序
(1)执行initrd.target
包括挂载/etc/fstab文件中的系统,此时挂载后,就可以切换到根目录了
(2)从initramfs根文件系统切换到磁盘根目录
(3)systemd执行默认target配置
centos7表面是有“运行级别”这个概念,实际上是为了兼容以前的系统,每个所谓的“运行级别”都有对应的软连接指向,默认的启动级别时/etc/systemd/system/default.target,根据它的指向可以找到系统要进入哪个模式
模式:
0 ==> runlevel0.target, poweroff.target(关机)
1 ==> runlevel1.target, rescue.target(单用户救援模式)
2 ==> runlevel2.target, multi-user.target(多用户无网络)
3 ==> runlevel3.target, multi-user.target(命令行界面)
4 ==> runlevel4.target, multi-user.target(保留级别)
5 ==> runlevel5.target, graphical.target(图形化)
6 ==> runlevel6.target, reboot.target(重启)
(4)systemd执行sysinit.target
有没有很眼熟?是的,在CentOS6上是被叫做rc.sysint程序,初始化系统及basic.target准备操作系统
(5)systemd启动multi-user.target下的本机与服务器服务
(6)systemd执行multi-user.target下的/etc/rc.d/rc.local
6.Systemd执行multi-user.target下的getty.target及登录服务
getty.target我们也眼熟,它是启动终端的systemd对象。如果到此步骤,系统没有被指定启动图形桌面,到此就可以结束了,如果要启动图形界面,需要在此基础上启动桌面程序
7.systemd执行graphical需要的服务
CentOS6,7启动区别
系统启动和服务器守护进程管理器,它不同于centos5的Sysv init,centos6的Upstart(Ubuntu制作出来),systemd是由Redhat的一个员工首先提出来的,它在内核启动后,服务什么的全都被systemd接管,kernel只是用来管理硬件资源,相当于内核被架空了,因此linus很不满意Redhat这种做法。
!!!https://www.cnblogs.com/kenken2018/p/10449938.html