java爬虫入门技术
我们需要用到http协议 从而建立java程序和网页的连接
URL url = new URL("https://www.ivsky.com/tupian/ziranfengguang/"); URLConnection urlConnection = url.openConnection(); urlConnection.connect(); //读取网页的html BufferedReader br = new BufferedReader(new InputStreamReader(urlConnection.getInputStream()));
上面的代码就是建立java程序和网页的连接
我们爬虫首先是将网页的Html代码爬下来
接下来我们需要从这些代码中找到有用的东西,我们发现大部分图片会有一个src资源
如果只是找一张图片我们可以直接用find函数查找,但是我们需要多张图片,此时正则表达式就显示了他的威力
我们直接用正则表达式匹配出来src资源
代码如下:
String line = null;
//正则表达式,解释如下在最少的""里面匹配到子表达式 ?相当于懒惰(匹配尽可能少) Pattern pattern = Pattern.compile("src="(.+?)""); List<String> list = new ArrayList<String>(); while((line = br.readLine()) != null) { Matcher m = pattern.matcher(line); while(m.find()) { //查到之后添加list里面 list.add(m.group()); } }
匹配出来这些字符串我们还需要对他们进行一些处理筛选出来图片的地址
代码如下
//筛选src,找到jpg和png和gif结尾的(设置新格式也就是截取字符串)放到图片集合里面 List<String> imglist = new ArrayList<String>(); for(String xString : list) { if(xString.endsWith(".jpg"") || xString.endsWith(".png"") || xString.endsWith(".gif"")) { //截取字符串的一部分也就是图片的地址 String partString = xString.substring(5,xString.length() - 1);
imglist.add(partString); } }
处理好之后我们就剩下最后一步了(下载)
下载就是将图片读进本地磁盘
代码如下
//开始下载 Date beginDate = new Date(); for(String xString : imglist) { Date partbeginDate = new Date(); URL partUrl; if(!xString.startsWith("http:")) { partUrl = new URL("http:"+xString); if(!("http:"+xString).startsWith("http://")) { continue; } }else { partUrl = new URL(xString); } System.out.println(partUrl); String nameString = xString.substring(xString.lastIndexOf("/") + 1,xString.length()); File file = new File("E:\图片下载\"+nameString); InputStream is = partUrl.openStream(); BufferedInputStream bis = new BufferedInputStream(is); BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(file)); System.out.println("开始下载" + xString); int len = 0; while((len = bis.read()) != -1){ bos.write(len); } System.out.println("下载完成"); Date partendDate = new Date(); double ti = (partendDate.getTime() - partbeginDate.getTime()) / 1000; System.out.println("用时" + String.format("%.8f", ti) + "s"); bis.close(); bos.close(); } Date endDate = new Date(); double ti = (endDate.getTime() - beginDate.getTime() ) / 1000; System.out.println("全部下载完成"); System.out.println("总用时" + String.format("%.8f", ti) + "s");
代码综合如下
package worm; import java.io.*; import java.net.MalformedURLException; import java.net.URL; import java.net.URLConnection; import java.util.*; import java.util.regex.Matcher; import java.util.regex.Pattern; import javax.swing.text.html.HTMLDocument.HTMLReader.IsindexAction; public class Main { public static void main(String[] args) throws Exception { /* * 连接网页 */ URL url = new URL("https://www.ivsky.com/tupian/ziranfengguang/"); URLConnection urlConnection = url.openConnection(); urlConnection.connect(); //读取网页的html BufferedReader br = new BufferedReader(new InputStreamReader(urlConnection.getInputStream())); String line = null; //正则表达式,解释如下在最少的""里面匹配到子表达式 ?相当于懒惰(匹配尽可能少) Pattern pattern = Pattern.compile("src="(.+?)""); List<String> list = new ArrayList<String>(); while((line = br.readLine()) != null) { Matcher m = pattern.matcher(line); while(m.find()) { //查到之后添加list里面 list.add(m.group()); } } br.close(); //筛选src,找到jpg和png和gif结尾的(设置新格式也就是截取字符串)放到图片集合里面 List<String> imglist = new ArrayList<String>(); for(String xString : list) { if(xString.endsWith(".jpg"") || xString.endsWith(".png"") || xString.endsWith(".gif"")) { //截取字符串的一部分也就是图片的地址 String partString = xString.substring(5,xString.length() - 1); imglist.add(partString); } } //开始下载 Date beginDate = new Date(); for(String xString : imglist) { Date partbeginDate = new Date(); URL partUrl; if(!xString.startsWith("http:")) { partUrl = new URL("http:"+xString); if(!("http:"+xString).startsWith("http://")) { continue; } }else { partUrl = new URL(xString); } System.out.println(partUrl); String nameString = xString.substring(xString.lastIndexOf("/") + 1,xString.length()); File file = new File("E:\图片下载\"+nameString); InputStream is = partUrl.openStream(); BufferedInputStream bis = new BufferedInputStream(is); BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(file)); System.out.println("开始下载" + xString); int len = 0; while((len = bis.read()) != -1){ bos.write(len); } System.out.println("下载完成"); Date partendDate = new Date(); double ti = (partendDate.getTime() - partbeginDate.getTime()) / 1000; System.out.println("用时" + String.format("%.8f", ti) + "s"); bis.close(); bos.close(); } Date endDate = new Date(); double ti = (endDate.getTime() - beginDate.getTime() ) / 1000; System.out.println("全部下载完成"); System.out.println("总用时" + String.format("%.8f", ti) + "s"); } }
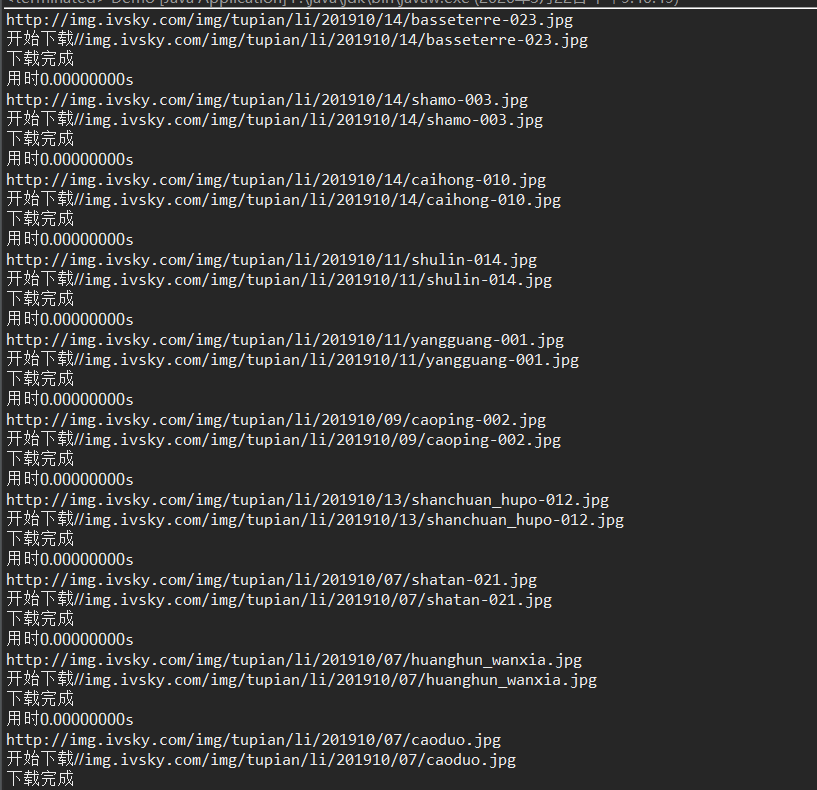
运行截图如下: