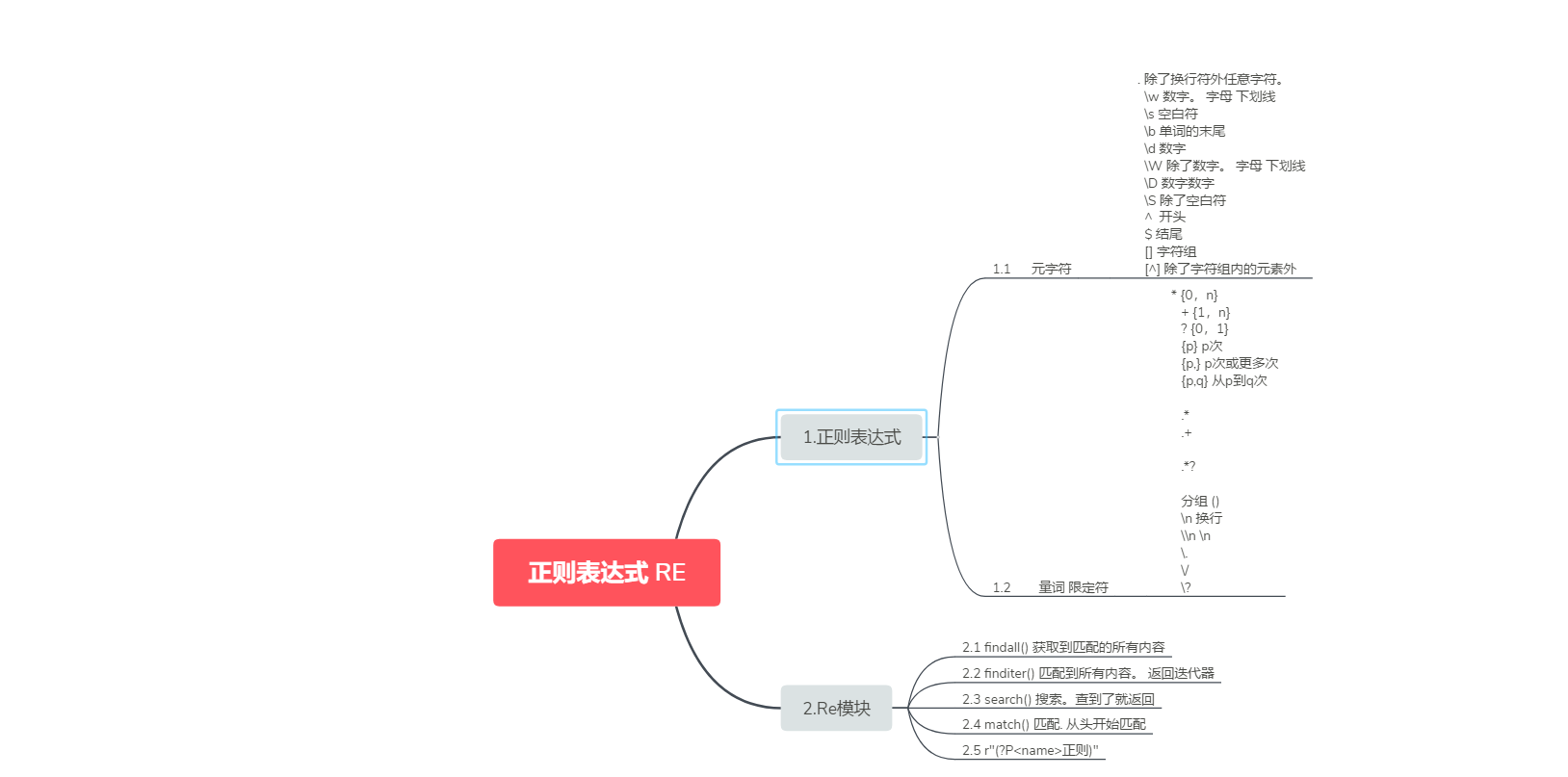
import re # res = re.search("e", "alex and exp") # 搜索. 搜到结果就返回 # print(res.group()) # res = re.match("w+", "alex is not a good man") # 从头匹配. 如果匹配到了。 就返回 # print(res.group()) # lst = re.findall("w+", "alex and exo") # print(lst) # it = re.finditer("w+", "mai le fo leng") # for el in it: # print(el.group()) # # # 这个分组是优先级 # lst = re.findall(r"www.(baidu|oldboy).com", "www.oldboy.com") # print(lst) # # # (?: ) 去掉优先级 # lst = re.findall(r"www.(?:baidu|oldboy).com", "www.oldboy.com") # print(lst) # 加了括号。 split会保留你切的刀 lst = re.split("([ab])", "alex is not a sb, no he is a big sb") # 根据正则表达式进行切割 print(lst) # # # 替换 # res = re.sub(r"d+", "_sb_", "alex333wusir666taibai789ritian020feng") # print(res) # # # 替换。 返回的结果带有次数 # res = re.subn(r"d+", "_sb_", "alex333wusir666taibai789ritian020feng") # print(res) # a = eval("1+3+5+6") # print(a) # code = "for i in range(10):print(i)" # c = compile(code, "", "exec") # 编译代码 # exec(c) # obj = re.compile(r"alex(?P<name>d+)and") # 把正则表达式预加载 # res = obj.search("alex250andwusir38ritian2") # print(res.group()) # print(res.group("name"))
from urllib.request import urlopen import re # url = "https://www.dytt8.net/html/gndy/dyzz/20181114/57791.html" # content = urlopen(url).read().decode("gbk") # # print(content) # # obj = re.compile(r'<div id="Zoom">.*?译 名(?P<yiming>.*?)<br />◎片 名(?P<pianming>.*?)<br />◎年 ' # r'代(?P<nian>.*?)<br />.*?<td style="WORD-WRAP: break-word" bgcolor="#fdfddf"><a href="(?P<url>.*?)">', re.S) # re.S 去掉.的换行 # # res = obj.search(content) # print(res.group("yiming")) # print(res.group("pianming")) # print(res.group("nian")) # print(res.group("url")) obj = re.compile(r'<div class="item">.*?<spanclass="title">(?P<name>.*?)</span>.*?导演: (?P<daoyan>.*?) .*?<span class="rating_num" property="v:average">(?P<fen>.*?)</span>.*?<span>(?P<ren>.*?)人评价</span>', re.S) def getContent(url): content = urlopen(url).read().decode("utf-8") return content def parseContent(content): it = obj.finditer(content) # 把页面中所有匹配的内容进行匹配. 返回迭代器 for el in it: yield { "name":el.group("name"), "daoyan":el.group("daoyan"), "ren":el.group("ren"), "fen":el.group("fen") } for i in range(10): url = "https://movie.douban.com/top250?start=%s&filter=" % i*25 g = parseContent(getContent(url)) f = open("movie.txt", mode="a", encoding="utf-8") for el in g: f.write(str(el)+" ") f.close()