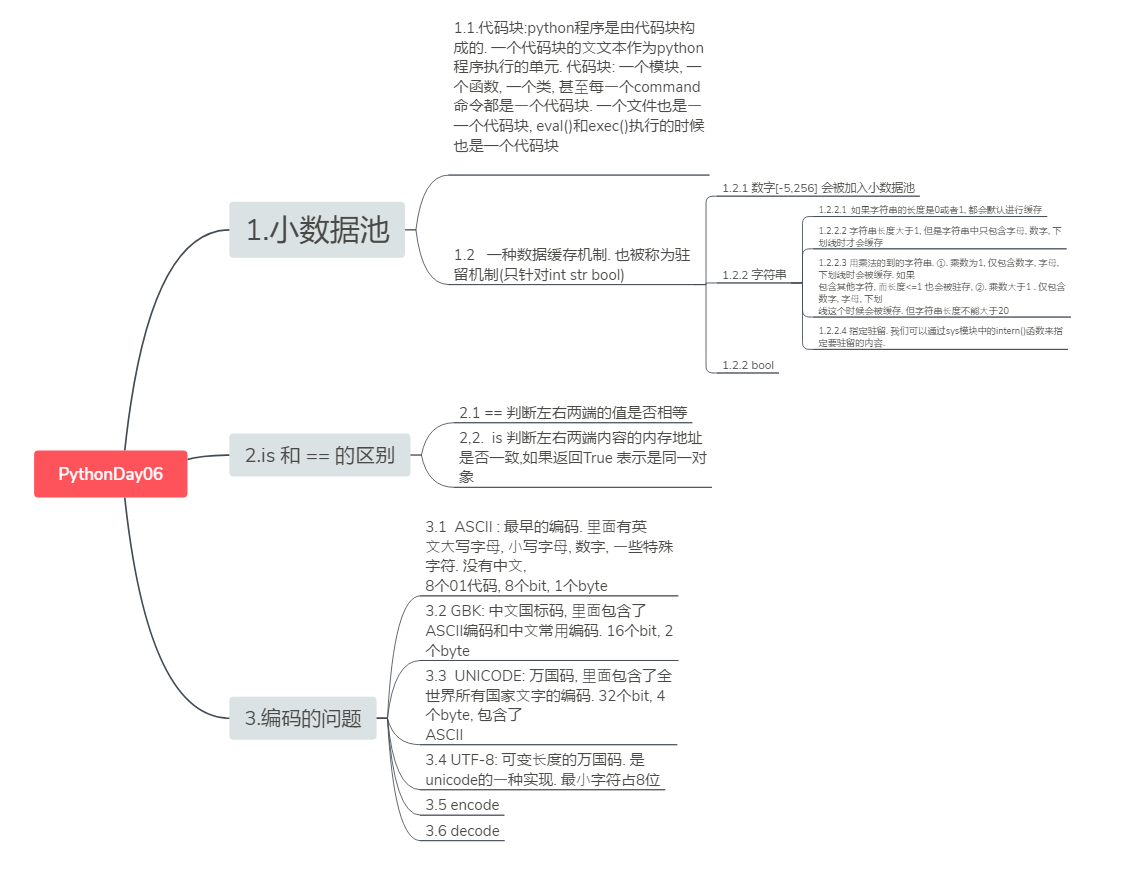
数字
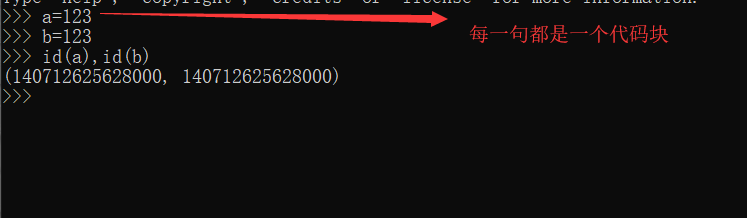
数字[-5,256]存在小数据池处理,如果大于256 如下图
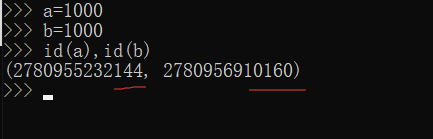
在IDE中呢?如下图
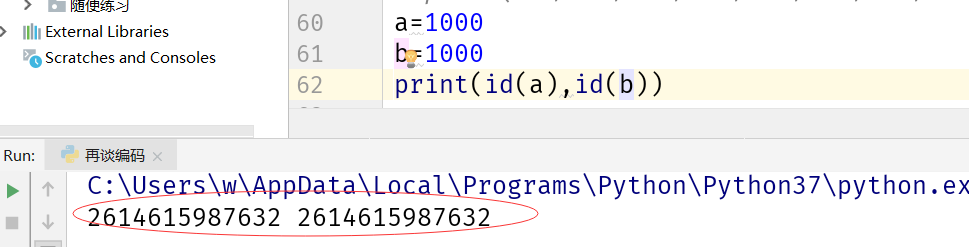
发现大于256后,id依然相同,这是为什么呢,这就要回到之前说的代码块,在cmd中一句命令就是一个代码块,在IDE中,是一个文件就是一个代码块,一个代码块的处理不一样
字符串
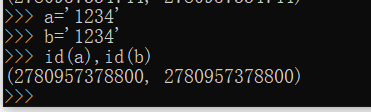
不同版本的python 可能优化各有不同,这里不必深究

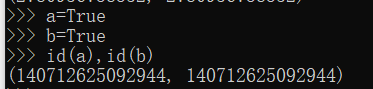
bool
编码
# a='a' # print(a.encode('utf-8')) #b'a' 一个字节 # a='中国' # print(a.encode('gbk')) #b'xd6xd0xb9xfa' 4个字节,一个字 对应2个字节 # print(a.encode('utf-8')) #b'xe4xb8xadxe5x9bxbd' 6个字节,一个字对应3个字节 #解码 # print(b'xe4xb8xadxe5x9bxbd'.decode('utf-8')) #中国 # print(b'xe4xb8xadxe5x9bxbd'.decode('bgk'))#utf-8编码的,gbk解不了 #LookupError: unknown encoding: bgk #b'xe4xb8xadxe5x9bxbd' 如何把utf-8 编码--->gbk编码呢 #1先解码 # bs=b'xe4xb8xadxe5x9bxbd' # s=bs.decode('utf-8') # print(s) #中国 #2在编码 # gbks=s.encode('gbk') # print(gbks) #b'xd6xd0xb9xfa' #实现 b'xe4xb8xadxe5x9bxbd'---->b'xd6xd0xb9xfa' #注,无法直接从utf-8-->gbk 需先解码,在进行编码