将糗事百科主页的段子标题和作者数据爬取下来,然后进行持久化存储
流程:
1.爬虫文件爬取到数据后,需要将数据封装到items对象中。 2.使用yield关键字将items对象提交给pipelines管道进行持久化操作。 3.在管道文件中的process_item方法中接收爬虫文件提交过来的item对象,然后编写持久化存储的代码将item对象中存储的数据进行持久化存储 4.settings.py配置文件中开启管道。 5.注:可能出错的地方
- 爬虫文件:qiubai.py

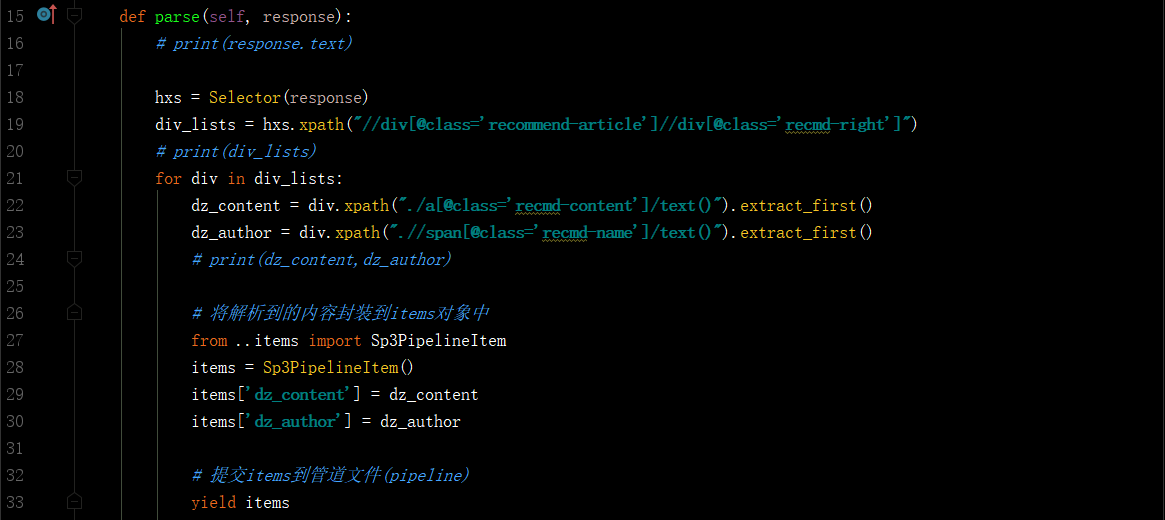
- items文件:items.py
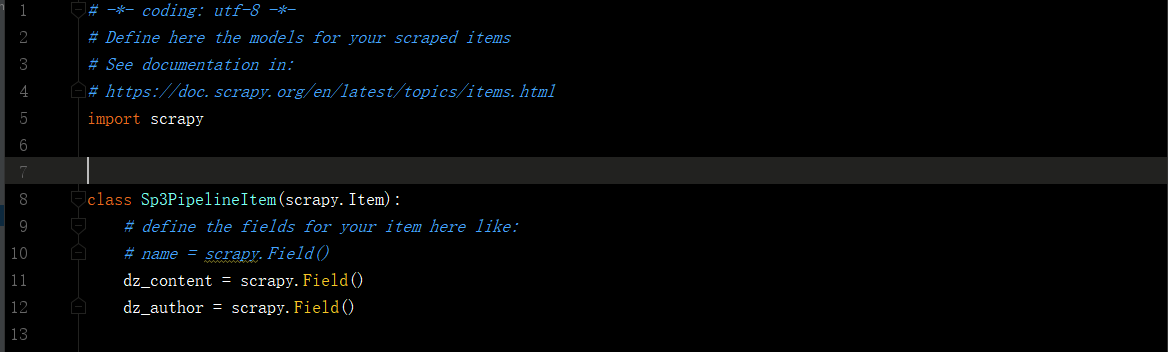
- pipelines.py
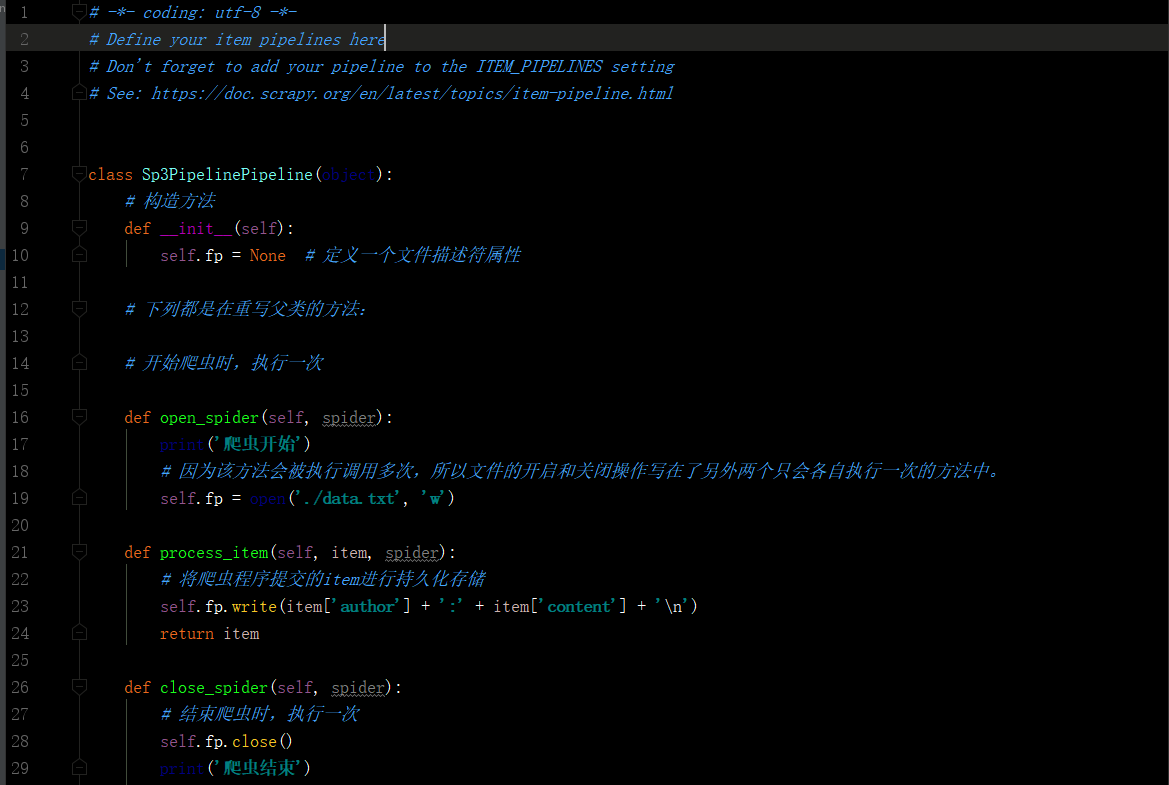
- settings.py

- 如果在执行的过程中出现这种错误:

这种情况就是该网站坐了反爬,解决办法就是修改headers头,下面我们就通过修改中间件来修改headers。
- middlewares.py
在该py文件中加入这个类
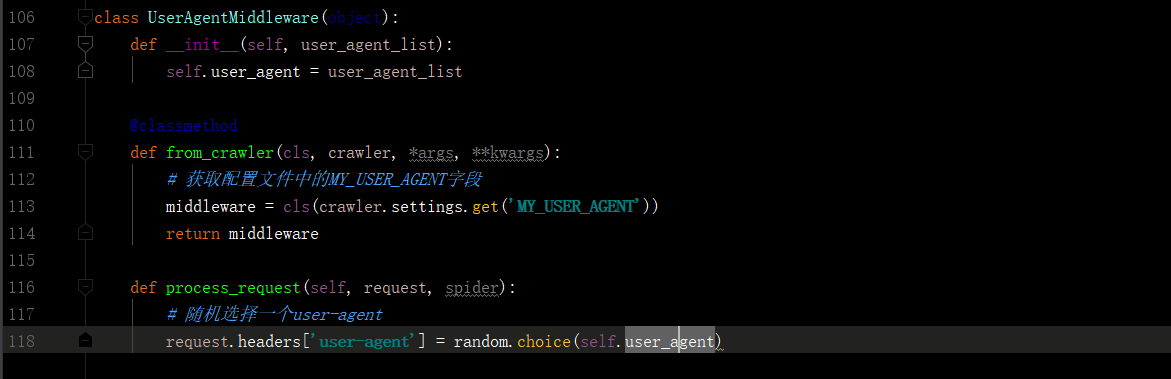
-settings.py
