分布式协调-Zookeeper(集群&ZAB&一致性)
前面对于zk的一些特性以及如何使用这些特性聊了聊,但是zk作为这样一个重要的中间件,我想瞅瞅他的底层实现原理。并且我们知道每个中间件都必须实现高可用,那我们就有必要去剖析一下他的集群特征。本篇所涉及到的点有:
- 集群搭建
- 节点集群角色
- ZAB协议(崩溃恢复和原子广播)
- ZK一致性(最终一致性)
集群搭建
准备四个节点(一个leader,一个observer,其他两个follower)
- 192.168.43.3
- 192.168.43.4
- 192.168.43.5
- 192.168.43.3 【observer】
在zk中的zoo.cfg(这个文件是zoo_samp的副本)中添加:2888端口是数据同步 ,3888是leader选举
- server.1=192.168.43.3:2888:3888
- server.2=192.168.43.4:2888:3888
- server.3=192.168.43.5:2888:3888
创建myid文件在zoo.cfg的dataDir目录下,里面的内容为:第一个节点就写1,第二个节点就写2,第二个节点就写3。这个1、2、3代表的是我们在上一步配置的server.id
开放端口 2181(访问zk的端口)、2888(进行数据同步的端口)、3888(leader选举的端口)
- firewall-cmd --zone=public --add-port=2181/tcp --permanent
- firewall-cmd --zone=public --add-port=2888/tcp --permanent
- firewall-cmd --zone=public --add-port=3888/tcp --permanent
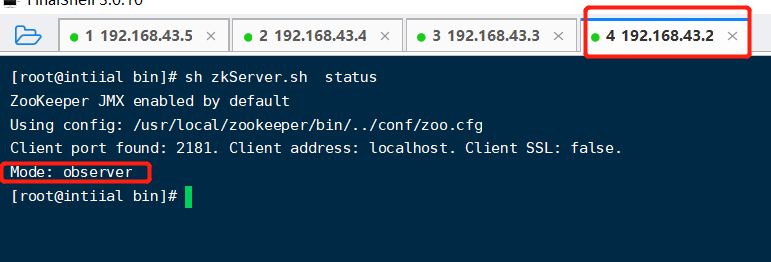
开启zk 【sh zkService.sh start】,然后查看zk状态,两个follower,一个leader节点,至此zk集群搭建成功。
增加一个follower节点:
- 在此节点的zoo.conf中加上:
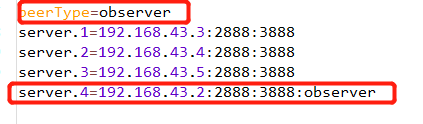
- 【peerType=observer】
- 和这个节点的ip以及server.id,并且之前的每个节点都需要加上这个节点的ip,就是【server.4=192.168.43.2:2888:3888:observer】
- 以及他的myid要是4
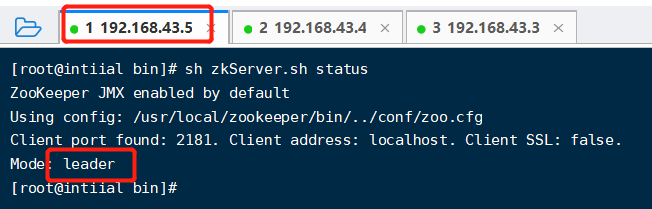
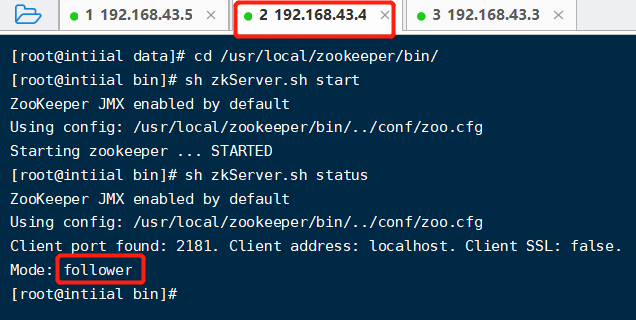
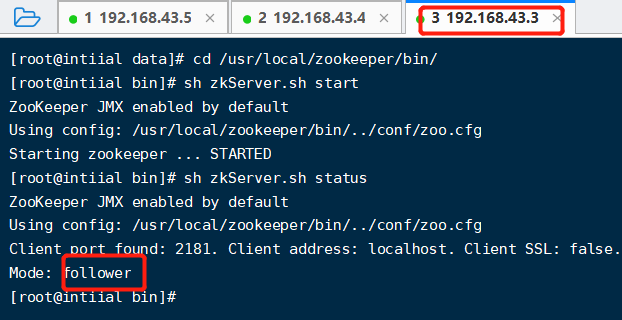
Zookeeper集群节点
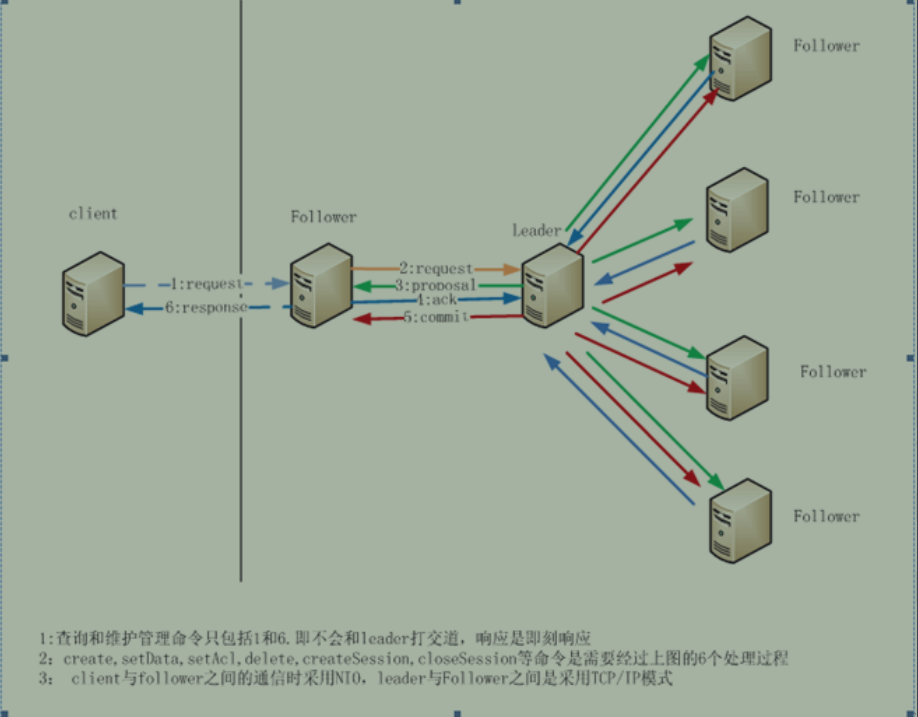
在分布式架构中任何单节点出现都是不允许的,而多节点就存储节点故障问题,常见的解决方法就是主从集群。一个中心节点对应多个从节点,主节点接受事务请求,从节点进行数据同步(因为当主节点挂了之后,从节点可以顶上去)。
在zk中的节点有:
主节点叫做【leader】: 对事务进行处理,并且当一个数据过来的时候,他需要把数据同步到多个从节点。我们跨节点的数据一致性通常是通过分布式事务来解决,底层是2pc协议,下面会说到。
从节点叫做【follower】进行非事务请求,以及请求的转发。(因为客户端不清楚那个节点是leader,所以可能会把请求发送到follower节点,那follower就把这个请求转发到leader上。)
【observer】节点:我们知道增加一个从节点,就会增加投票的开销,那就意味着客户端收到的响应可能会越来越慢。但是我们还是想在读多写少的情况下去缓解我们读节点的压力,所以我们就增加一个observer节点,那他就不参与投票,以及leader选举,也就意味着他永远成为不了leader,只是一个读取数据的节点。
ZAB协议
ZAB协议(Zookeeper Atomic Broadcas)包含两个问题:崩溃恢复和原子广播
【崩溃恢复(leader挂了,需要选举新的leader)】:当整个集群启动的时候,或者当leader出现崩溃的时候,zab就会进入恢复模式并选出新的leader,当leader被选举出来的时候,并且集群中有过半的节点和被选举出来的leader完成数据通讯后,zab就会退出这个崩溃回复状态。
- 【选举leader的前提是满足(后面会对源码进行分析)】:
- 【已经被提交的消息不能被丢弃】:就是leader确定了集群中有一半已经发送了ack给了自己。然后他把第二阶段的提交发送给follower之后就挂了,那这个消息必须在所有服务器上都执行成功。否则就会出现数据不一致的问题。
- 【被丢弃的消息不能再次出现】:当leader收到了一个其他节点转发过来的消息后,然后要准备第一阶段提交的时候,他就挂了,那么新的leader上就不需要有这个消息。老的leader重启之后变成follower之后就要把这个消息删除。
- 【具体做法】:需要先引出两个概念
【流程】
- 【zxid】:因为在数据同步的时候,leader会发送zxid给各个follower。他是一个64位的数字,高32位是epoch,低32位用于递增计数。
那么整个集群将无法对外提供服务
:当集群中的leader服务器出现宕机或者不可用的情况时,
,而是进入新一轮的Leader选举,服务器运行期间的Leader选举和启动时期的Leader选举基本过程是一致的,都是下面的的这个流程。
- 当启动的时候,每个节点都把自己的zxid,myid,epoch发送给别的节点。
- 然后按照规则,比较epoch->zxid->myid。
- 如果a节点发现b和c的某个节点上的epoch比自己的大,那就把自己的票据变成比自己大的那个票据,然后再次发送。
- 而节点b和a节点比较发现自己就是最大的,他就不修改,再次把自己的票发送出去。
【原子广播(数据同步)】:当集群中已经有过半的Follower节点完成了和Leader状态同步以后,那么整个集群就进入了消息广播模式。这个时候,在Leader节点正常工作时,启动一台新的服务器加入到集群,那这个服务器会直接进入数据恢复模式,和leader节点进行数据同步。
- 【具体做法】:
- leader收到事务请求之后,维护一个zxid,并且为每一个follower准备了一个FIFO的队列。
- 然后将带有zxid的消息发送给所有的follower。
- 当follower收到这个消息后,把消息写入磁盘,写入成功后,给leader返回一个成功的ack.
- leader收到过半节点的ack后,leader发送执行命令给follower,并且在本地执行消息(创建节点)
- follower收到leader的执行消息后,在自己的本地执行。
- 至此,数据同步完毕。
- 这个其实有2pc的影子
2pc:
- 第一个阶段发起事务提议:
- leader向所有参与节点发送一个事务内容,比如创建一个节点。然后所有的参与节点会把这个事务写到事务日志中(这个日志并没有提交,这个时候内容是不可见的)。然后发送一个消息给leader。
- 第二个阶段发起提交或者回滚:
- 所有节点都返回消息的时候,leader就发起一个commit去让这些参与节点提交事务,这个节点就执行事务,然后新创建的节点就是对客户端可见的。
然而,在zk中使用的是过半提交(就是如果有3个节点,有两个节点返回成功,那就执行这个事务)
Zk的一致性
上面说到zk在数据同步的时候是采用过半的策略,那也就是说,当客户端去访问的zk的时候,可能自动路由到某个除了leader之外的节点的话,就会获取不到准确的数据。但是zk官网给的解释说zk是一个【最终一致性】中间件,也就是说他最终的数据会达成一致。
所以zk不保证在每个实例中,两个不同的客户端一定会读取到相同的数据,由于网络延迟等因素,一个客户端可能会在另外一个客户端收到更改通知之前执行更新,如果客户端A和B要读取必须要读取到相同的值,那么client B在读取操作之前执行sync方法。 zooKeeper.sync();
但是!如果一个客户端连接到了zk上的一个最新的数据节点,当这个客户端再次连接zk的时候,zk可以保证这个客户端不会读取到老的数据,这是因为zk中使用zxid进行了处理,流程为:客户端会记录自己已经读取到的最大的zxid,如果客户端重连到zk上的节点发现zk上节点的zxid比自己大,连接会失败。
常见问题:
上面说了,过半节点返回票据就可以进行数据同步了,那剩下的没有返回票据的节点怎么办?
他会不断的去拿自己的zxid去和leader对比,如果自己的不一样,则进行数据拉取。
他的节点数据存储在哪里?
默认的目录是在/tmp/zookeeper下,该路径可以通过zoo.cfg文件来修改
- # 内存数据库快照存放地址
- dataDir=/data/zookeeper-3.4.6/data
- # 事务日志存储
- dataLogDir=/data/zookeeper-3.4.6/data/log
在Zab协议中我们知道每当有接收到客户端的事务请求后Leader与Follower都会将把该事务日志存入磁盘日志文件中,该日志文件就是上面配置中的事务日志。其中文件的命名是 log.zxid, 其中zxid表示当前日志文件中开始记录的第一条数据的zxid。