分布式存储-Redis&常用数据库(Profile)
实际上我们使用Redis的初衷就是为了优化数据库,当我们用户的行为增加了,我们数据库的IO就增加了,Redis的数据是存储在内存中,而我们的传统的数据的数据是存储在磁盘中,就存储在内存这一方面Redis就优化了数据的读取速度。本篇中聊一聊常用的Redis数据结构、不同的存储数据带来的性能提升、常用的数据库优化手段
数据库层面的优化手段
【池化技术】:实现连接资源的复用(本质上是降低资源创建和销毁的开销),当我们去链接数据库的会发送一个TCP请求到数据库上,如果使用池化技术,那就节省了很多时间,提升了性能。
【数据库本身层面的优化】:
【索引】:当没有索引的时候,我们去查询数据,他会去扫描磁盘轨道,有了索引就相当于通过一个点直接进行定位,这样速度就快了很多
【数据量的传输】:我们可以尽量减少数据量的传输,少查询一些不必要的数据,肯定就提高性能。
【数据库的读写分离】:如果没有做读写分离,每个数据在进行事务操作的时候就会加锁,从而影响了查询的速度
常见的数据库类型
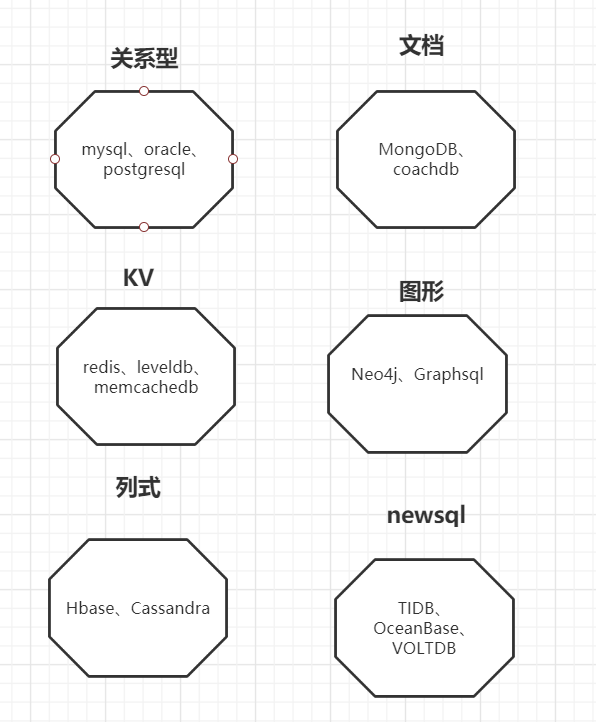
数据库的发展历史是->关系型数据库->NOSQL->NEWSQL
【KV数据库】:
- 键值形式
- 数据存储在内存中(无法支持海量存储)
- 时间复杂度是O(1)
【列式数据库】:比如一些实时报表、监控数据等场景适合
- 统计数据速度快(相同的数据存储在一起)
- 事务处理速度慢(需要在加载不同的存储块中数据进行处理,因为处理的是一条数据中的不用类型)
【 文档型】:把相关的一系列数据存储在一个文档中,平常我们查询用户、文章、用户评论三张表才能得到一个完整的信息,现在把这些都存储在一起,一下就能检索出来。
【NEWSQL】:NOSQL的下一个阶段衍生出来的一种思想;拥有传统的关系型数据库的的核心特性,也拥有NOSQL的特性
【图形数据库】:传统数据库中,可能在一个给定实体中有很多关系,比如一个专家评分,牵扯到标书表,招标表、投标表、专家组长表、专家类型表等等,而在图形数据库中这些就抽象成一个个节点,创建相应的关系即可,这些组合成专家评分的数据所需的表只是节点集中的节点。

Redis(K-V 数据库) http://doc.redisfans.com/(常用命令)
Redis已经是一个众所周知的技术了,这里就不讲他的安装以及介绍他的。安装的时候有一个坑的地方就是我们的GCC必须是5.3版本以上,要不安装Redis就会报错。用YUM默认是4.*,使用以下命令可以升级他的版本到9,就可以解决报错的问题
- # 升级到gcc 9.3:
- yum -y install centos-release-scl
- yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
- scl enable devtoolset-9 bash
- # 需要注意的是scl命令启用只是临时的,退出shell或重启就会恢复原系统gcc版本。
- # 如果要长期使用gcc 9.3的话:
- echo -e " source /opt/rh/devtoolset-9/enable" >>/etc/profile
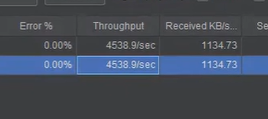
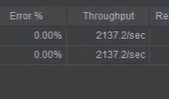
这里用Jemeter压测了两个接口,一个是从数据库直接读取数据的,另外一个是把数据缓存在Redis中然后读取的,我们发现使用Redis查询数据的接口每秒的吞吐量多了一倍。所以这是我们使用他的一个原因。
【数据类型】
String:Redis是用c开发的,C中并没有string类型,所以他的底层实际上是使用了一个动态的sds(因为我们string的长度是不固定的,所以他用了一个动态的结构),在sds的结构中才使用了一个char数组对我们的string进行存储
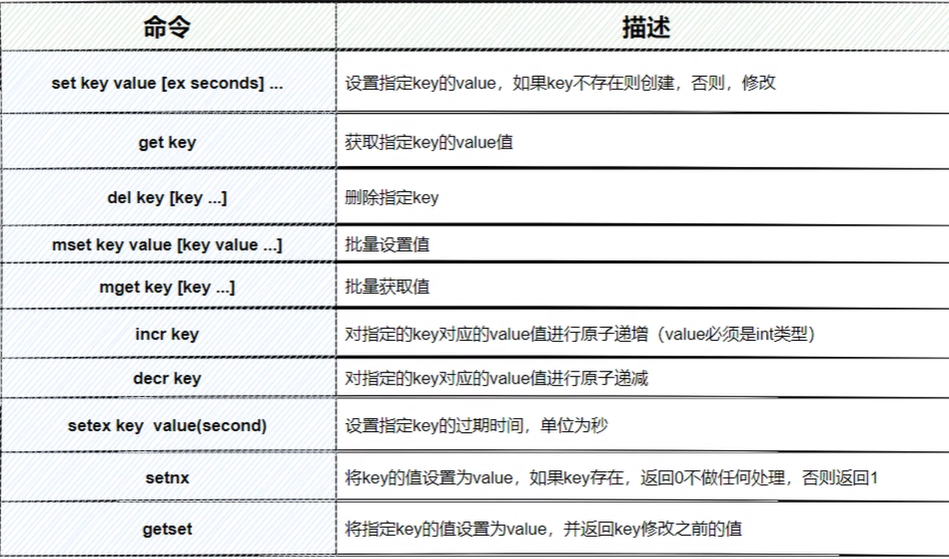
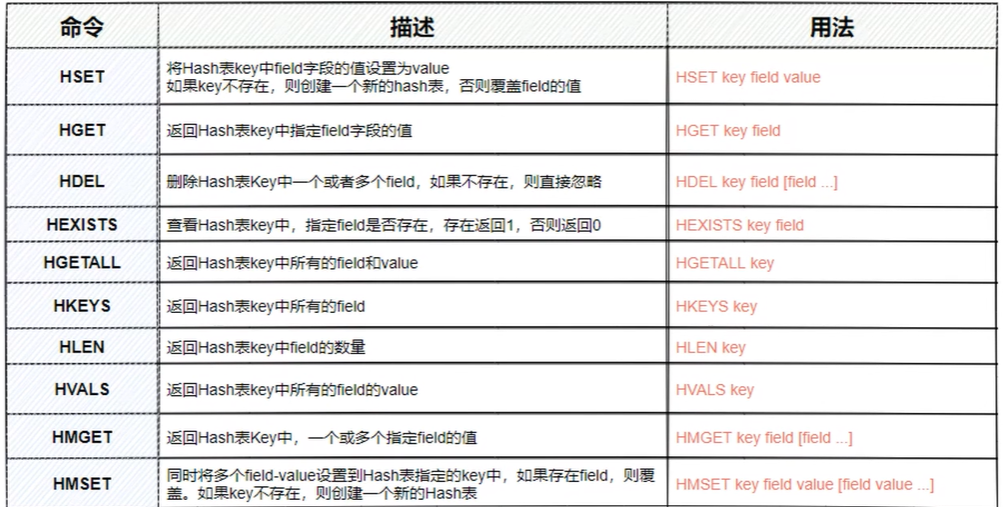
【常见命令】:
这里有一些特殊的命令
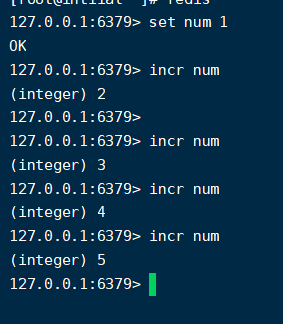
incr 和 decr:这个命令是原子的,他可以保证线程安全的特性。因为Redis是单线程的,所以他可以保证原子性,那我们就可以用这个来做分布式id。
setnx: 我们可以用这个特性做我们的分布式锁,我们知道锁的特性是排他的,那当返回0的时候,则证明有一个数据已经存在了,这样就巧妙的使用了这个功能。
【使用场景】:
【缓存应用】:缓存热点数据
【全局id】:使用incr 进行递增
【限流】:(比如设置一个key为一个用户id,然后value的值的过期时间设置60s(根据自己需要),然后配合incr 进行递增,当value的数值大于我们能接受的数据,我们就关闭访问通道)
【分布式session】:他等于是一个全局的视角,第三方的,所以我们的所有微服务都可以去这里获取数据。
List:是一个有序,且可重复的字符串链表,是一个栈+堆结构,可以支持非or阻塞的FIFO/LIFO,
简而言之:他是一个Quicklist结构(就是个双向链表,每个节点中存储的是一个ziplist(压缩列表,前面的线程篇章我们讲了cpu的做高速缓存的时候一次读取的一个缓存行的数据,为了防止伪共享,如果当前的位置不是满的,则自动补0,压缩列表就是让每个位置都存储有效的数据,而不是用0代替,这就让性能大大提升,让cpu每次读取的都是有效的数据,并且节省内存))
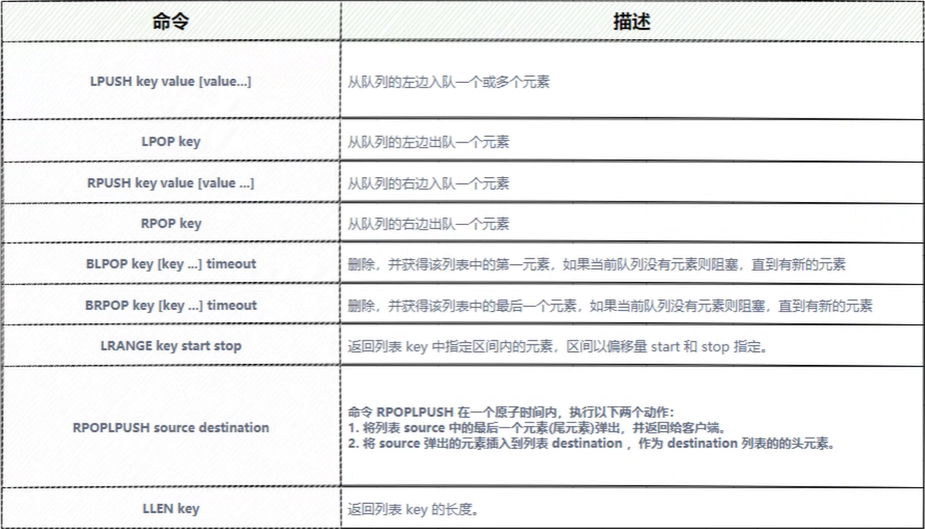
【常见命令】
【使用场景】:
【消息队列】:我们使用lpush入队一个数据,用rpop从右边出队一个数据
【发送红包场景】:我们在发送前面计算好红包的个数和金额,用lpush入队,然后抽取红包的时候使用rpop出队。其实秒杀也行,我们把库存数据直接放在Redis中,然后还是相同的操作
hash:当hash个数小于512的时候,以及所有的数值都小于64个字节的时候,默认情况下会通过ziplist存储多个数据元素,因为数据量小的时候,使用ziplist去存储可以节省内存空间,并且检索不会太慢,但是超过这个阈值的时候,他就会采用hashtable进行存储,因为hashtable的读写时间复杂度是o(1)
【常见命令】
【使用场景】:
购物车、商品详情数据、用户信息、计数器、so on
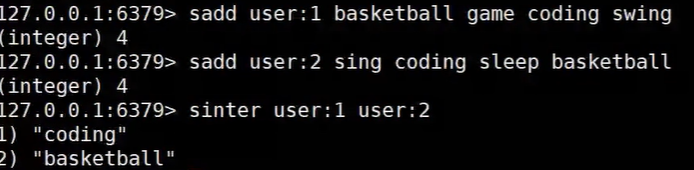
Set:是一个无序,并且唯一的集合 (https://www.cnblogs.com/xinhuaxuan/p/9256738.html) 如果set中存储的都会整形他都会使用intset进行存储,否则用hashtable进行存储
【使用场景】:
用户画像、标签管理
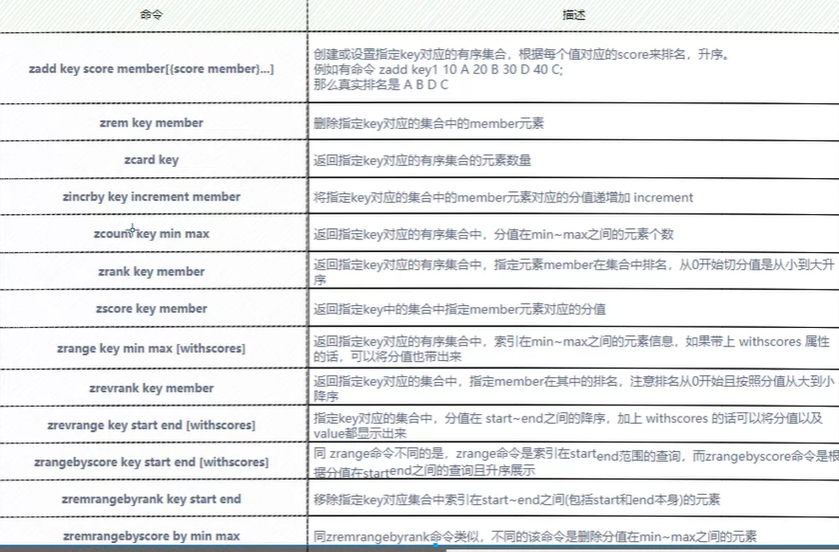
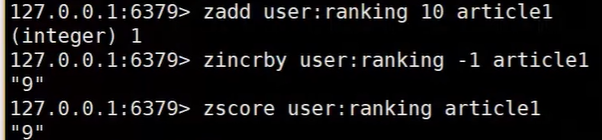
zset:他是一个有序的的集合,在每个value前面维护了一个score,基于每个score进行排序。看下面的命令我们发现,可以通过key和score进行检索数据,他的底层实际上是使用了hashtable和跳表进行存储的,如果我想通过key去检索数据,那就使用hashtable进行检索(他的时间复杂度是0(1)),而当我们使用score去检索的话,那就使用跳表进行检索(我们知道跳表有等级,当我们要检索某个数据的时候,他不在某个等级的话,就会跳到下一个等级去进行检索,他的时间复杂度是o(log)),实际上不管使用跳表还是hashtable他们都是一个指针指向原数据,这样就可以防止内存浪费
【常见命令】
【使用场景】:
用户点赞排行、热点话题排行,因为每个数据中都有score,用score我们就可以计算出排行