并发编程-ConcurrentHashMap(一)
本篇来聊聊1.8的ConcurrentHashMap(CHS),关于它的一些设计思想(高低位扩容、链式寻址法、链表 so on),数据结构,和源码试实现行剖析,本篇会讲到前面的一部分代码分析,包括(延迟初始化、阈值判断扩容、以及高低位扩容)
为什么使用CHS
【HashMap】是非线程安全的,有时候因为没有给使用【HashMap】的代码段加同步锁,在1.7的时候居然导致了死锁,。那我们就使用【Hashtable】,他是可以保证线程安全,但是他只是粗暴的加上了synchronized关键字,这样锁的粒度太粗(性能很低) 。所以当多线程场景下CHS就应运而生。
CHS的使用
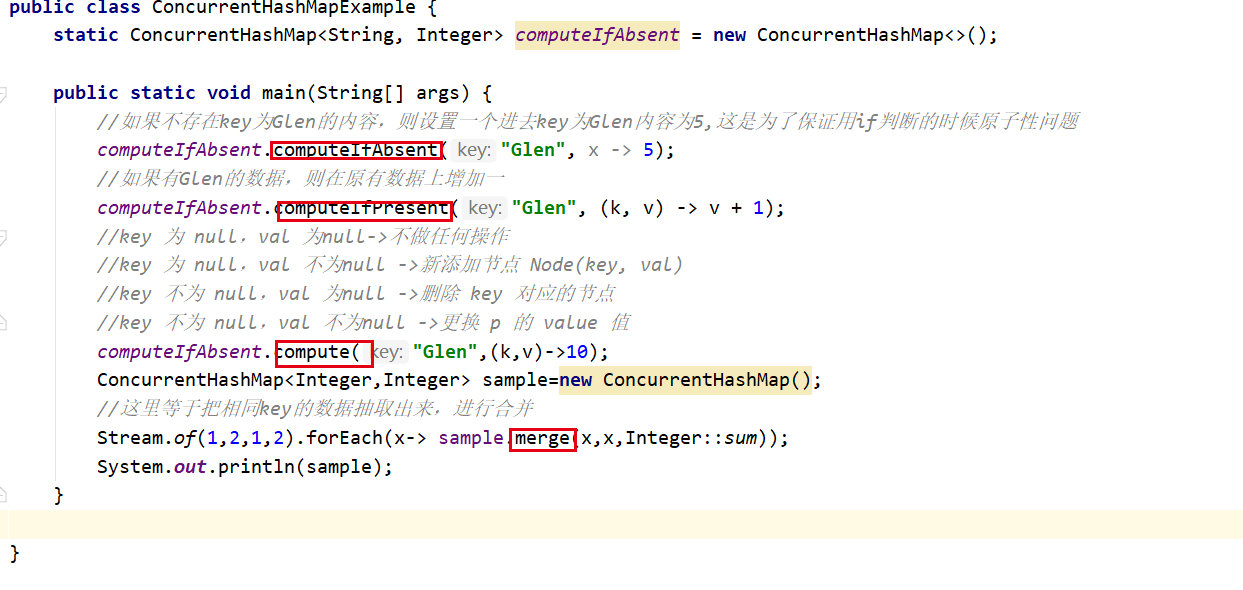
平常的新增,删除等一些操作这里我们不再继续了解,咱们了解一下在1.8后加的一些新的方法【computeIfAbsent 】【computeIfPresent】【computeIfPresent】 【compute】 【merge】我这里分别写了个例子,所以不再赘述
CHS存储和实现
总体来说,他是基于一个数组进行数据的存储,数组中的每个元素都叫做一个节点,并且分为两种方式,
【链表】:是用来解决哈希冲突的,我们在说threadlocal的时候说到过,用的是线性探索进行解决的
【红黑树】:用来解决链表过于长,带来的时间复杂度增加的问题,红黑树使得时间复杂度从【O(n)->O(logn)】
!!!node长度超过64的时候,链表长度超过8的时候,则进行红黑树的转换,当做扩容的时候,红黑树会转换成节点,因为当扩容的时候,数据会进行拉伸,伴随着,数据结构无法达到红黑树的条件,从而转变
总体视角:
- 当我们put一个数据的时候,首先会用你put的key的哈希值计算一个数组下标
- 如果我们put key的哈希数值一样的话,则加入此节点的下面,就变成了一个单项列表。

CHS源码分析
我们发现,在new一个chs的时候没并没有创建一个新的对象,创建对象和赋值的操作都在put方法中实现的,这就是【延迟初始化】
final V putVal(K key, V value, boolean onlyIfAbsent) { if (key == null || value == null) throw new NullPointerException(); //使用你传进来的key去计算一个hash值,后面要用这个计算下标 int hash = spread(key.hashCode()); int binCount = 0; //这里是个自旋,因为是多线程里面肯定牵扯到cas的操作,那cas可能会失败,失败之后肯定要重新把这个数值传进来,所以使用自旋 for (Node<K,V>[] tab = table;;) { Node<K,V> f; int n, i, fh; //如果table为空则去初始化一个Node<K,V>[] table 这是存储的容器; if (tab == null || (n = tab.length) == 0) tab = initTable(); // (n - 1) & hash这里用换算出来的hash值去计算一个下标 else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { //如果当前的算出来的下标处没有数据则创建一个node并且存储数据,这里还是通过cas保障数据安全 if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) break; } else if ((fh = f.hash) == MOVED) tab = helpTransfer(tab, f); //当前位置如果存储数据,则走这里的逻辑 else { V oldVal = null; //锁住当前的node节点避免线程安全问题,这里的锁的粒度很细,因为只是锁住当前的node,意味着其他的节点,都可以在这个时候同时插入数据,这样就提升了性能 synchronized (f) { if (tabAt(tab, i) == f) { //这里是针对链表的操作 if (fh >= 0) { binCount = 1; //f代表的是当前node的头结点,拿到头节点开始向下遍历,binCount实际上是在统计链表的长度 for (Node<K,V> e = f;; ++binCount) { K ek; //判断是否存在相同的key,如果存在则进行覆盖(相同的key后者会覆盖前者) if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; if (!onlyIfAbsent) e.val = value; break; } //如果不存在则把当前的key和value添加到链表中,这里使用的是尾插法( = e.next),直接添加到尾部 Node<K,V> pred = e; if ((e = e.next) == null) { pred.next = new Node<K,V>(hash, key, value, null); break; } } } //这里是针对红黑树的操作 else if (f instanceof TreeBin) { Node<K,V> p; binCount = 2; if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } if (binCount != 0) { //如果链表长度大于等于8,则会根据阈值判断是转化为红黑树还是扩容 if (binCount >= TREEIFY_THRESHOLD) treeifyBin(tab, i); if (oldVal != null) return oldVal; break; } } } addCount(1L, binCount); return null; }initTable(这是进行容器初始化的操作,因为是多线程情况下,所以要加锁,这是使用CAS充当了锁)这里的【sizeCtl 】等于是一个状态机,去标识当前数组扩容的状态
private final Node<K,V>[] initTable() { Node<K,V>[] tab; int sc; //只要容器没有初始化就不断进行初始化 while ((tab = table) == null || tab.length == 0) { if ((sc = sizeCtl) < 0) Thread.yield(); //因为是多线程,所以这里使用cas保证原子性 else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) { try { if ((tab = table) == null || tab.length == 0) { //这里的默认长度是16 int n = (sc > 0) ? sc : DEFAULT_CAPACITY; @SuppressWarnings("unchecked") Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n]; table = tab = nt; //这里保留扩容的阈值(当数组长度到达扩容的阈值的时候,就进行扩容) sc = n - (n >>> 2); } } finally { sizeCtl = sc; } break; } } return tab; }treeifyBin(这里根据阈值判断,是转换红黑树,还是扩容,前面说了数组长度到达64的时候才会转换为红黑树)
private final void treeifyBin(Node<K,V>[] tab, int index) { Node<K,V> b; int n, sc; if (tab != null) { //如果table长度小于64则进行扩容,否则进行红黑树的转换 if ((n = tab.length) < MIN_TREEIFY_CAPACITY) //进行扩容 tryPresize(n << 1); else if ((b = tabAt(tab, index)) != null && b.hash >= 0) { //进行红黑树的转换 synchronized (b) { if (tabAt(tab, index) == b) { TreeNode<K,V> hd = null, tl = null; for (Node<K,V> e = b; e != null; e = e.next) { TreeNode<K,V> p = new TreeNode<K,V>(e.hash, e.key, e.val, null, null); if ((p.prev = tl) == null) hd = p; else tl.next = p; tl = p; } setTabAt(tab, index, new TreeBin<K,V>(hd)); } } } } }tryPresize(对数组进行扩容):这里牵扯到一个【多线程并发扩容】,简而言之,就是允许多个线程对数组协助扩容,
扩容的本质:
- 每次把数组的长度扩大到原来的一倍
- 然后把老的数据迁移到新的数组
private final void tryPresize(int size) { //用于判断扩容的目标大小 int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY : tableSizeFor(size + (size >>> 1) + 1);//这里就是为了满足2m³,如果是15那就给你转化成16(转换成最近的2m³) int sc; //说明要做数组的初始化,因为这个方法在别的地方也有使用,所以要进行判断 while ((sc = sizeCtl) >= 0) { Node<K,V>[] tab = table; int n; //这里进行数组的初始化 if (tab == null || (n = tab.length) == 0) { //这里数组容量是通过对比的计算出来的,初始容量(我们可以自定义chm的大小)和扩容容量,谁的数字大就选择谁作为数组的默认长度 n = (sc > c) ? sc : c; if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) { try { if (table == tab) { @SuppressWarnings("unchecked") Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n]; table = nt; sc = n - (n >>> 2); } } finally { sizeCtl = sc; } } } //已经是最大的容量,则不进行扩容了,直接返回 else if (c <= sc || n >= MAXIMUM_CAPACITY) break; else if (tab == table) { //这里生成一个扩容戳,这是为了保证当前扩容范围的唯一性(使用多线程来执行分段扩容),我们在下面聊聊这个东西,他挺有意思的
int rs = resizeStamp(n); //第一次扩容的时候,不会走这一段逻辑,因为sc不小于1 if (sc < 0) { Node<K,V>[] nt; //表示扩容结束 if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || sc == rs + MAX_RESIZERS || (nt = nextTable) == null || transferIndex <= 0) break; //表示没有结束,所以每次增加一个线程进行扩容,则在【低位】加一,当扩容结束后低位就开始递减,证明线程一个个开始释放,最终低位全部都是0,则说明扩容完毕 if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
//这里实现数组的数据转移 transfer(tab, nt); }
//第一次走这个逻辑,他会把我们上面算出的rs左移16位 就会变成(换算的结果看下面的resizeStamp分析)-> 1000 0000 0001 1011 0000 0000 0000 0000
//算出来的戳的 【高16位】标识当前的额扩容标记,【低16位】标识当前扩容的线程数量
//然后对换算出来的结果加2 (2的二进制是10)
//于是就变成了 1000 000 0001 1011 0000 0000 0000 0010 (上面讲高位标识扩容标记,低位表示扩容的线程数量,那这里就是一个线程在参加扩容) else if (U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2)) transfer(tab, null); } } }因为是多线程共同参与数据的迁移,那我肯定要有一个地方记录参与这个任务的线程数量
【numberOfLeadingZeros】:这个方法会【返回这个数据的二进制串中从最左边算起连续的“0”的总数量】,
- 例如 一个int类型的长度是32 【0000 0000 0000 0000 0000 0000 0000 0000】 现在在17位这里有一个1,那就在前面有16个0这个时候这个方法就会返回16 【0000 0000 0000 0000 1000 0000 0000 0000】
static final int resizeStamp(int n) {
//把前面计算出来的二进制的第16位变成1,比如说现在key计算出来的是16 那转换出来的二进制就是10000 因为int是32位所以给他前面补充0就变成了
//0000 0000 0000 0000 0000 0000 0001 0000 ->那他最高位数前面的数字就有27个0就返回27
// 27换算出来的二进制是 【11011】 给前面补充0之后就变成了 0000 0000 0000 0000 0000 0000 000 1 1011
// 给他的第16位变成1那就变成->0000 0000 0000 0000 1000 0000 0001 1011return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1)); }
