参考:https://blog.csdn.net/weixin_36279318/article/details/79475388
要找到目标元素,通过浏览器检查的方式或者按F12键,找到该控件元素,通过其ID、class等属性,能够唯一定位到该元素。
Selenium提供了8种定位方式。
- id
- name
- class name
- tag name
- link text
- partial link text
- xpath
- css selector
这8种定位方式在Python selenium中所对应的方法为:
- find_element_by_id()
- find_element_by_name()
- find_element_by_class_name()
- find_element_by_tag_name()
- find_element_by_link_text()
- find_element_by_partial_link_text()
- find_element_by_xpath()
- find_element_by_css_selector()
---------------------------------------------------------------------------------------
wd = webdriver.Chrome(r'd:webdriverschromedriver.exe')
wd.find_element_by_id('kw') --根据ID属性定位元素
wd.find_elements_by_class_name('animal') --根据class属性定位元素
我们要选择 所有的 动物,注意element后面多了个s
find_elements_by_class_name 方法返回的是找到的符合条件的 所有 元素 (这里有3个元素), 放在一个 列表 中返回。
而如果我们使用 find_element_by_class_name (注意少了一个s) 方法, 就只会返回 第一个 元素。
wd.find_elements_by_tag_name('div') --根据tag定位
element.send_keys('黑羽魔巫宗 ') --发送内容
element.click() --点击方法
# 等待 2 秒,等浏览器加载完成
from time import sleep
sleep(2)
Selenium 的 Webdriver 对象 有个方法叫 implicitly_wait
wd.implicitly_wait(10)
如果找不到元素, 每隔 半秒钟 再去界面上查看一次, 直到找到该元素, 或者 过了10秒 最大时长。
element与elements的区别:
elements = wd.find_elements_by_class_name('animal')
for element in elements: --把所有的元素打印,用循环
print(element.text)
会输出所有的class_name为animal的文本值,即列表: 狮子 老虎 山羊
通过 WebElement 对象的 text属性 可以获取所有元素的文本内容。如无符合条件的,则返回空列表。用elements的对象不能为列表,需要是唯一的,即不能多个animal对象。
若elements = wd.find_element_by_class_name('animal')
print(elements.text) 则只得到第一个值,即狮子。如无符合条件,则抛出异常。
元素也可以有 多个class类型 ,多个class类型的值之间用 空格 隔开,比如
<span class="chinese student">张三</span>
注意,这里 span元素 有两个class属性,分别 是 chinese 和 student, 而不是一个 名为 chinese student 的属性。
tag为标签,即<后面的那个,如<div,则div为我们要的tag_name。
elements = wd.find_elements_by_tag_name('div')
---------------------------------------------------------------------------------------
通过WebElement对象选择元素
不仅 WebDriver对象有 选择元素 的方法, WebElement对象 也有选择元素的方法。
WebElement对象 也可以调用 find_elements_by_xxx, find_element_by_xxx 之类的8种方法
wd = webdriver.Chrome(r'd:webdriverschromedriver.exe')
wd.get('http://cdn1.python3.vip/files/selenium/sample1.html')
element = wd.find_element_by_id('container')
# 限制 选择元素的范围是 id 为 container 元素的内部。
spans = element.find_elements_by_tag_name('span')
for span in spans:
print(span.text)
输出结果就只有
内层11
内层12
内层21链接定位元素
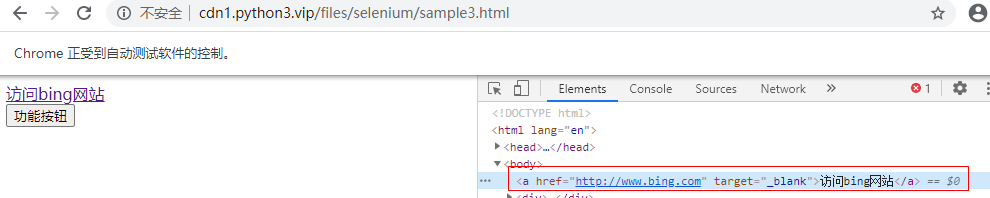
wd.find_element_by_link_text("访问bing网站").click()
#wd.find_element_by_link_text("hao123")
wd.find_element_by_partial_link_text("访问").click()
wd.find_element_by_partial_link_text("bing").click()
wd.find_element_by_partial_link_text("网站").click()

成功找到对应的链接位置,且点击成功打开新页面。