一、主成分分析简称 PCA(Principal Component Analysis)
非监督
目的:原来的数据集是d维,转换成k维的数据,k<d,新的k维数据尽可能多的包含原来d维数据的信息
1.1 用处:
1.Clustering
把复杂的多维数据点,简化成少量数据点,易于分簇
2.降维(特征工程:数据过于稀疏/数据过少)
降低高维数据,简化计算
降低维度,压缩,去噪
1.2 实例
二维-->一维:寻找一个一维向量的方向,数据在这个向量撒谎给你的投影能最小化损失

n维-->k维:寻找一个k维向量,数据在这个k维空间的投影能最小化损失,最大程度的包含原来的n维数据的信息
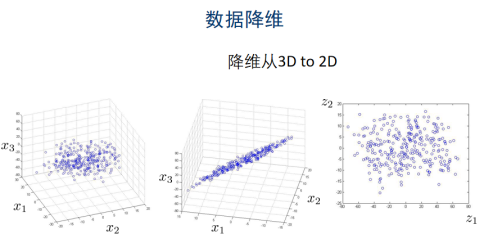
1.3 如何选择投影方向
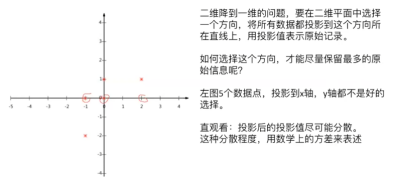
对数据做了均值化处理,再减去均值,方差的u就会变成0:


注释:
数据的集中程度:用均值表示
数据的分散程度:用方差表示
协方差:衡量2个维度之间是否有关系,2个维度之间的线性相关性有多大
1.4 PCA的推导过程
降维的过程中,让数据尽可能的分散,找一个线性变化,让数据投影的方差最大化,假设先找一个线性变化的u1,对xi做线性变化的投影。
先对数据进行均值化处理
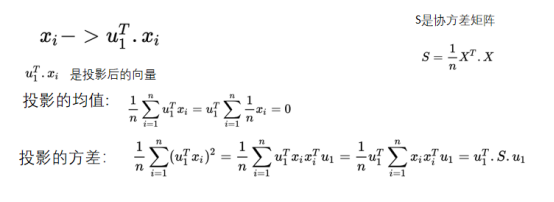
目标:最大化投射后的方差:

至此可证明,我们要找的x 投影后的方差就是协方差矩阵的特征值,而我们想要的最大方差,显然就是协方差矩阵最大的特征值,最佳投影方向就是最大特征值所对应的特征向量
n_components

注释:

1.5 PCA求解的步骤
设有m条n维数据。
1)将原始数据按列组成n行m列矩阵X
2)将X的每一行(代表一个属性字段)进行零均值化,即减去这一行的均值
3)求出协方差矩阵
4)求出协方差矩阵的特征值及对应的特征向量
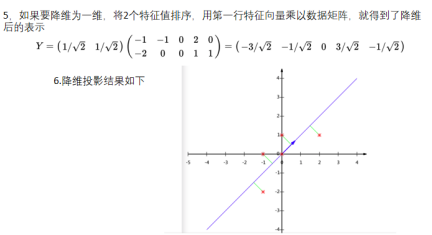
5)将特征向量按对应特征值大小从上到下按行排列成矩阵,取前k行组成矩阵P
6)Y=PX即为降维到k维后的数据

二、LDA
监督式学习
LDA(Linear Discriminant Analysis),中文名为“线性判别分析”。
LDA的中心思想就是最大化类间距离以及最小化类内距离
2.1 图示
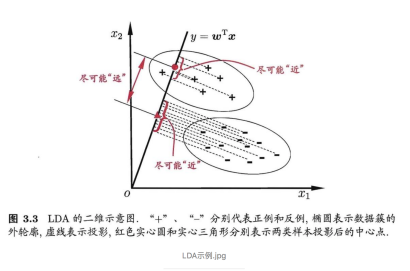
2.2 推导过程及损失函数:




2.3 算法流程

三、PCA和LDA的比较
3.1 相似点:
从过程来看,PCA与LDA有很大的相似性,最后其实都是求某一个矩阵的特征值,投影矩阵即为该特征值对应的特征向量
3.2 差异:
PCA为非监督降维,LDA为有监督降维
PCA希望投影后的数据方差尽可能的大(最大可分性),因为其假设方差越大,则所包含的信息越多;而LDA则希望投影后相同类别的组内方差小,而组间方差大。LDA能合理运用标签信息,使得投影后的维度具有判别性,不同类别的数据尽可能的分开。
有标签就尽可能的利用标签的数据(LDA),而对于纯粹的非监督任务,则还是得用PCA进行数据降维。
参考资料:
Dimensionality Reduction Stanford CSEP 546
PCA的数学原理
https://blog.csdn.net/xiaojidan2011/article/details/11595869
PCA与LDA比较
https://www.jianshu.com/p/982c8f6760de
LDA线性判别原理解析
https://blog.csdn.net/feilong_csdn/article/details/60964027
我觉得这个博客写的不错:https://zhuanlan.zhihu.com/p/55798053?utm_source=qq