Exploiting Multiple Embeddings for Chinese Named Entity Recognition 利用多个嵌入进行中文命名实体识别
代码:ME-CNER
https://arxiv.org/pdf/1908.10657.pdf
识别文本中提到的命名实体将在下游级别丰富许多语义应用程序。 但是,由于在微博中普遍使用口语,因此与在正式中文语料库中执行NER相比,中文微博中的命名实体识别(NER)经历了明显的性能下降。 在本文中,我们提出了一个简单而有效的神经框架,以推导中文文本中NER的字符级嵌入,即ME-CNER。 字符嵌入是从丰富的语义信息派生而来的,这些语义信息在从根部,字符到单词级别的多种粒度下得到利用。 实验结果表明,所提出的方法在微博数据集上实现了较大的性能改进,在MSRA新闻数据集上实现了可比的性能,并且与现有的最新技术相比具有较低的计算成本。
利用偏旁来推断语义
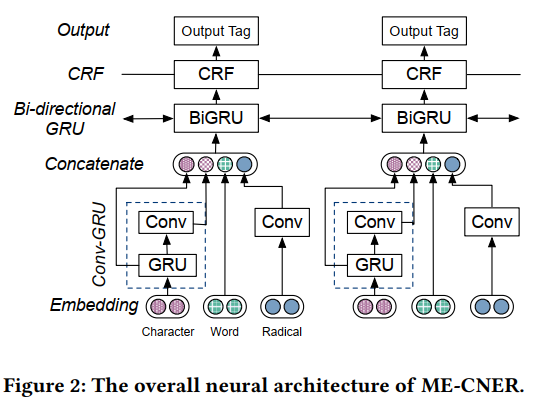
先前的研究将字符级CNN模型用于NER任务。 但是,CNN强调特定窗口内的局部n-char特征,并且无法捕获长期依赖关系。 为了解决这个问题,我们提出了由GRU层和卷积层组成的卷积门控循环单元(Conv-GRU)网络。 首先,将字符嵌入ci馈入GRU层。
然后输出 (mathrm{X}=left[mathrm{x}_{1}, ldots, mathrm{x}_{l} ight]) 被输入到卷积层中,卷积层的长度与输入的长度相同, where (l) 是微博的长度
最后,将卷积层的输出与GRU层的输出连接在一起,以形成每个字符的最终表示形式。
这样,我们可以将本地上下文和长期依赖关系中的语义知识结合在一起。
为了对齐分段的单词和字符,我们将单词嵌入复制为其组成字符,for example,组成字符“班”(班级)和“长”(总统)均与嵌入“班长(班级总裁)”的共享word embedding。 如果单词不在单词嵌入的词汇表中,我们将使用随机值初始化其嵌入。
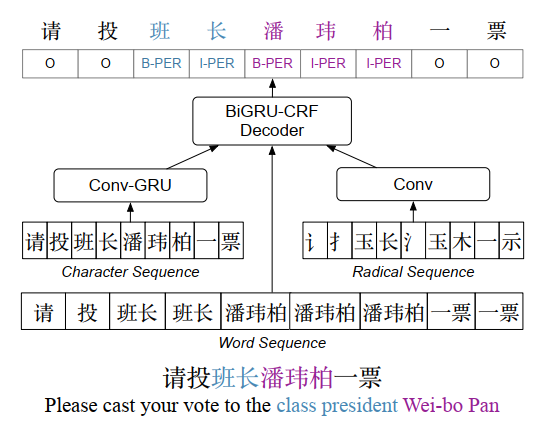
我们将字符嵌入分为部首,字符和单词级别,以形成最终的字符表示形式。 然后,我们利用BiRNN-CRF标记器标记每个句子。 BiGRU-CRF由向前和向后的GRU层以及位于前者之上的CRF层组成。 在这里,我们使用腾讯AI Lab [14](https://ai.tencent.com/ailab/nlp/embedding.com)提供的预先训练的嵌入来初始化单词嵌入和字符嵌入。
html)。
实验
我们利用[11]提供的标准微博NER数据集。
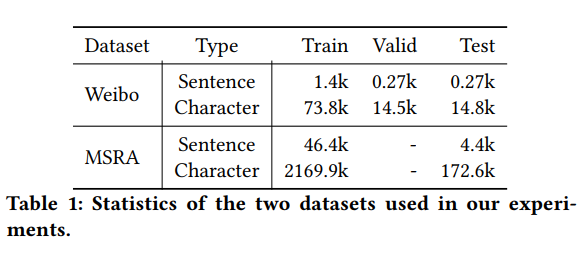
它由命名实体和名词性提及组成。 另外,我们在正式的文本数据集MSRA新闻数据集[8]上进行实验,该数据集仅包含命名实体。 表1显示了我们使用的两个数据集的统计信息。
使用结巴分词。
对于部首和字符级嵌入,我们将卷积层的内核大小设置为3。 在Conv-GRU框架中,GRU的维度设置为150。嵌入大小固定为200。我们添加丢包的概率为0.8。 我们将每个实验运行五次,然后报告平均准确度,召回率和F1分数。 对于BiGRU标记器,使用BIO方案[13]。