1.1.1.读取Socket数据
●准备工作
nc -lk 9999
hadoop spark sqoop hadoop spark hive hadoop
●代码演示:
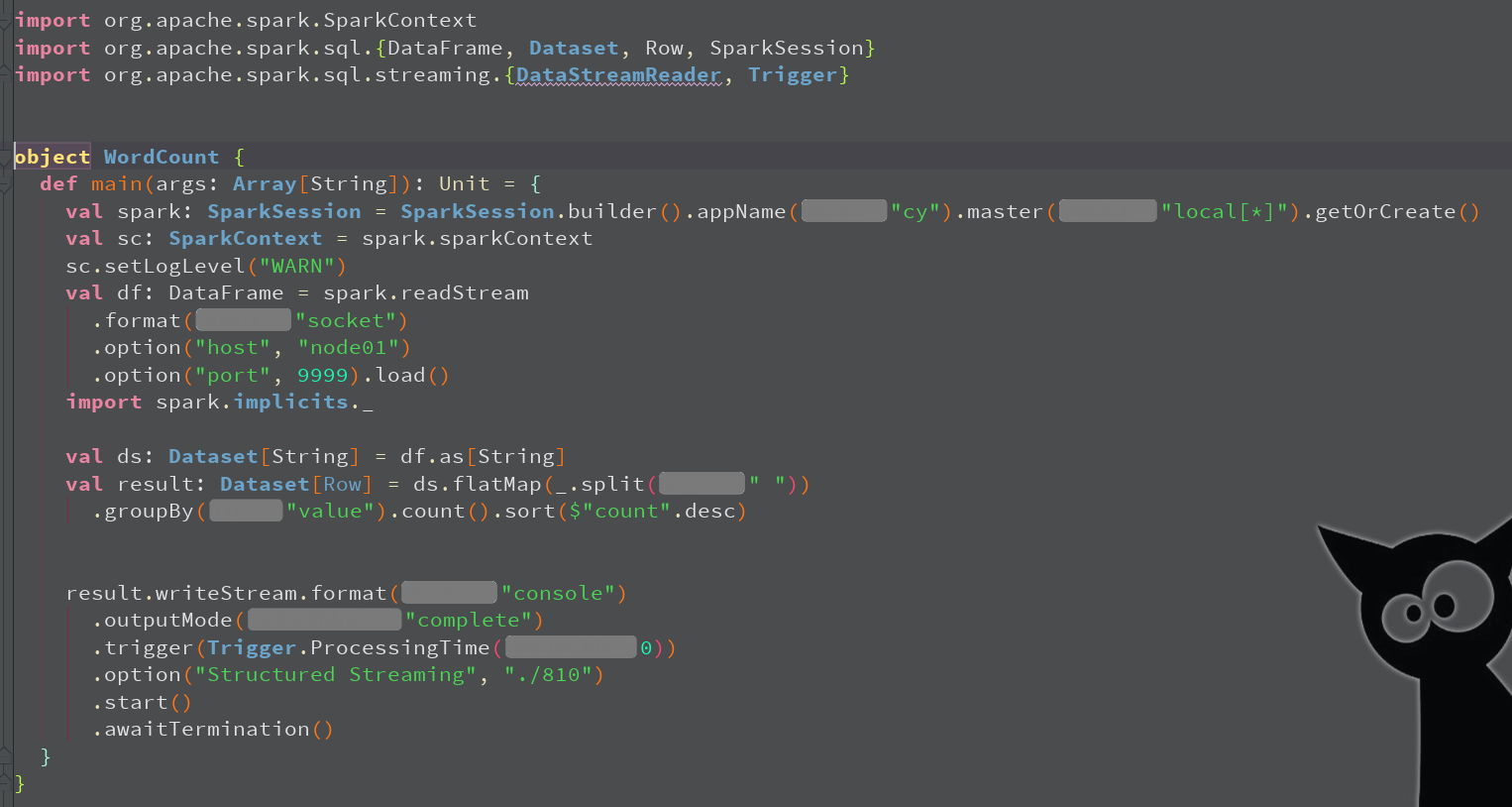
import org.apache.spark.SparkContext
import org.apache.spark.sql.streaming.Trigger
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object WordCount {
def main(args: Array[String]): Unit = {
//1.创建SparkSession,因为StructuredStreaming的数据模型也是DataFrame/DataSet
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.接收数据
val dataDF: DataFrame = spark.readStream
.option("host", "node01")
.option("port", 9999)
.format("socket")
.load()
//3.处理数据
import spark.implicits._
val dataDS: Dataset[String] = dataDF.as[String]
val wordDS: Dataset[String] = dataDS.flatMap(_.split(" "))
val result: Dataset[Row] = wordDS.groupBy("value").count().sort($"count".desc)
//result.show()
//Queries with streaming sources must be executed with writeStream.start();
result.writeStream
.format("console")//往控制台写
.outputMode("complete")//每次将所有的数据写出
.trigger(Trigger.ProcessingTime(0))//触发时间间隔,0表示尽可能的快
.option("checkpointLocation","./810")//设置checkpoint目录,用来做合并
.start()//开启
.awaitTermination()//等待停止
}
}32
1
import org.apache.spark.SparkContext
2
import org.apache.spark.sql.streaming.Trigger
3
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
4
5
object WordCount {
6
def main(args: Array[String]): Unit = {
7
//1.创建SparkSession,因为StructuredStreaming的数据模型也是DataFrame/DataSet
8
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL").getOrCreate()
9
val sc: SparkContext = spark.sparkContext
10
sc.setLogLevel("WARN")
11
//2.接收数据
12
val dataDF: DataFrame = spark.readStream
13
.option("host", "node01")
14
.option("port", 9999)
15
.format("socket")
16
.load()
17
//3.处理数据
18
import spark.implicits._
19
val dataDS: Dataset[String] = dataDF.as[String]
20
val wordDS: Dataset[String] = dataDS.flatMap(_.split(" "))
21
val result: Dataset[Row] = wordDS.groupBy("value").count().sort($"count".desc)
22
//result.show()
23
//Queries with streaming sources must be executed with writeStream.start();
24
result.writeStream
25
.format("console")//往控制台写
26
.outputMode("complete")//每次将所有的数据写出
27
.trigger(Trigger.ProcessingTime(0))//触发时间间隔,0表示尽可能的快
28
.option("checkpointLocation","./810")//设置checkpoint目录,用来做合并
29
.start()//开启
30
.awaitTermination()//等待停止
31
}
32
}
代码截图: