一、 Hadoop集群动态扩容、缩容
随着公司业务的增长,数据量越来越大,原有的datanode节点的容量已经不能满足存储数据的需求,需要在原有集群基础上动态添加新的数据节点。也就是俗称的动态扩容。
有时候旧的服务器需要进行退役更换,暂停服务,可能就需要在当下的集群中停止某些机器上hadoop的服务,俗称动态缩容。
1. 动态扩容
1.1. 基础准备
在基础准备部分,主要是设置hadoop运行的系统环境
修改新机器系统hostname(通过/etc/sysconfig/network进行修改)

修改hosts文件,将集群所有节点hosts配置进去(集群所有节点保持hosts文件统一)

设置NameNode到DataNode的免密码登录(ssh-copy-id命令实现)
修改主节点slaves文件,添加新增节点的ip信息(集群重启时配合一键启动脚本使用)

在新的机器上上传解压一个新的hadoop安装包,从主节点机器上将hadoop的所有配置文件,scp到新的节点上。
1.2. 添加datanode
在namenode所在的机器的
/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop目录下创建dfs.hosts文件
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim dfs.hosts
添加如下主机名称(包含新服役的节点)
node-1
node-2
node-3
node-4
在namenode机器的hdfs-site.xml配置文件中增加dfs.hosts属性
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim hdfs-site.xml
|
<property> <name>dfs.hosts</name> <value>/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/dfs.hosts</value> </property> |
dfs.hosts属性的意义:命名一个文件,其中包含允许连接到namenode的主机列表。必须指定文件的完整路径名。如果该值为空,则允许所有主机。相当于一个白名单,也可以不配置。
在新的机器上单独启动datanode: hadoop-daemon.sh start datanode

刷新页面就可以看到新的节点加入进来了
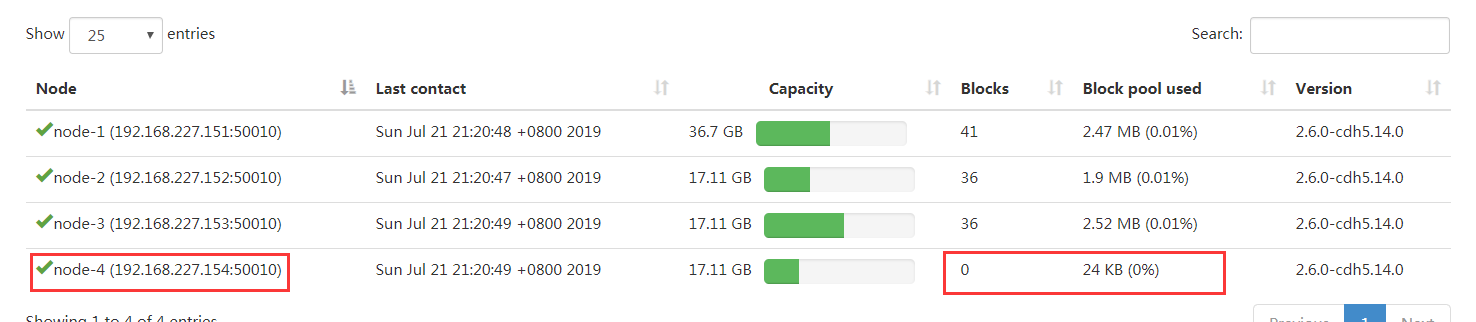
1.3. datanode负载均衡服务
新加入的节点,没有数据块的存储,使得集群整体来看负载还不均衡。因此最后还需要对hdfs负载设置均衡,因为默认的数据传输带宽比较低,可以设置为64M,即hdfs dfsadmin -setBalancerBandwidth 67108864即可
默认balancer的threshold为10%,即各个节点与集群总的存储使用率相差不超过10%,我们可将其设置为5%。然后启动Balancer,
sbin/start-balancer.sh -threshold 5,等待集群自均衡完成即可。
1.4. 添加nodemanager
在新的机器上单独启动nodemanager:
yarn-daemon.sh start nodemanager
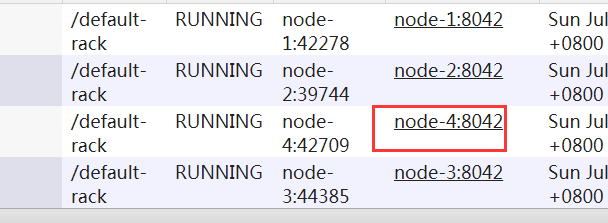
在ResourceManager,通过yarn node -list查看集群情况

动态缩容
添加退役节点
在namenode所在服务器的hadoop配置目录etc/hadoop下创建dfs.hosts.exclude文件,并添加需要退役的主机名称。
注意:该文件当中一定要写真正的主机名或者ip地址都行,不能写node-4
node04.hadoop.com
在namenode机器的hdfs-site.xml配置文件中增加dfs.hosts.exclude属性
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim hdfs-site.xml
|
<property> <name>dfs.hosts.exclude</name> <value>/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/dfs.hosts.exclude</value> </property> |
dfs.hosts.exclude属性的意义:命名一个文件,其中包含不允许连接到namenode的主机列表。必须指定文件的完整路径名。如果值为空,则不排除任何主机。
2.2. 刷新集群
在namenode所在的机器执行以下命令,刷新namenode,刷新resourceManager。
hdfs dfsadmin -refreshNodes
yarn rmadmin –refreshNodes
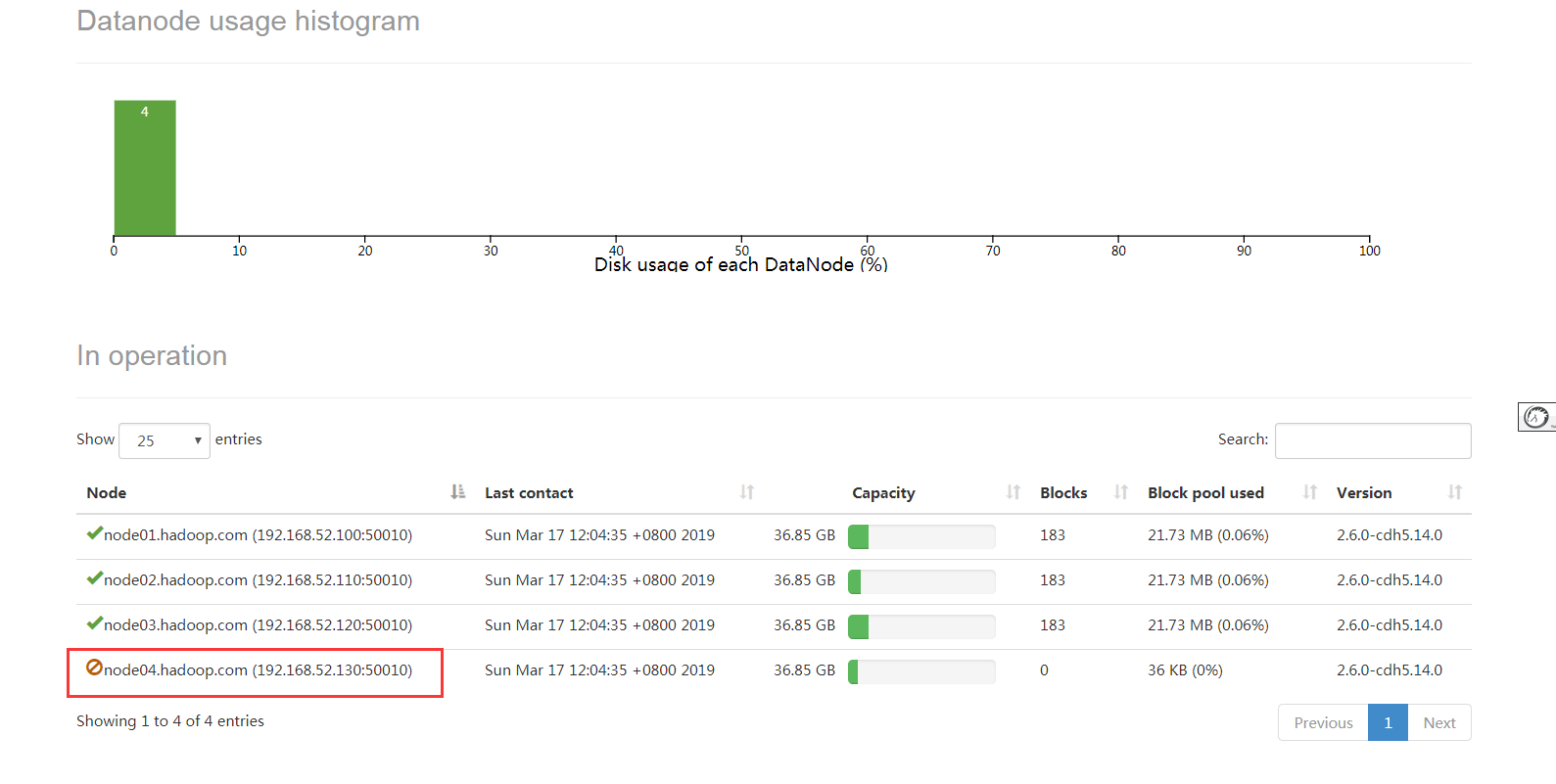
等待退役节点状态为decommissioned(所有块已经复制完成),停止该节点及节点资源管理器。注意:如果副本数是3,服役的节点小于等于3,是不能退役成功的,需要修改副本数后才能退役。
node-4执行以下命令,停止该节点进程
cd /export/servers/hadoop-2.6.0-cdh5.14.0
sbin/hadoop-daemon.sh stop datanode
sbin/yarn-daemon.sh stop nodemanager
namenode所在节点执行以下命令刷新namenode和resourceManager
hdfs dfsadmin –refreshNodes
yarn rmadmin –refreshNodes
namenode所在节点执行以下命令进行均衡负载
cd /export/servers/hadoop-2.6.0-cdh5.14.0/
sbin/start-balancer.sh
总结:
-
- 原理:增加、删除那些角色?
node-4: datanode |nodemanager11node-4: datanode |nodemanager - 扩容的基本步骤
- 新服务器基础环境
ip 主机名 hsots映射 防火墙 免密登录 jdk版本 时间同步111ip 主机名 hsots映射 防火墙 免密登录 jdk版本 时间同步 - 在新服务器解压一份新的hadoop安装包
- 把已有集群的hadoop的配置文件scp一份到新服务器安装包中
- 手动启动新的进程
hadoop-daemon.sh start datanode yarn-daemon.sh start nodemanager221hadoop-daemon.sh start datanode2yarn-daemon.sh start nodemanager - 因为新加入的节点没有数据 和已有节点间会产生负载不均衡的现象 所以需要平衡数据
首先调整网络传输数据的带宽 默认是64M hdfs dfsadmin -setBalancerBandwidth 67108864 然后负载均衡的服务 设置负载均衡的差异值 默认10% start-balancer.sh -threshold 5 等待其自动负载均衡完毕x51首先调整网络传输数据的带宽 默认是64M2hdfs dfsadmin -setBalancerBandwidth 6710886434然后负载均衡的服务 设置负载均衡的差异值 默认10%5start-balancer.sh -threshold 5 等待其自动负载均衡完毕
- 新服务器基础环境
- 缩容的基本步骤
- 在主节点所在的机器配置退役节点的黑名单机制
dfs.hosts.exclude 指定的文件就是所需要退役下线的节点 注意:该文件的中必须是正常的ip或者主机名221dfs.hosts.exclude 指定的文件就是所需要退役下线的节点2注意:该文件的中必须是正常的ip或者主机名 - 配置好之后 刷新节点信息
hdfs dfsadmin -refreshNodes yarn rmadmin –refreshNodes221hdfs dfsadmin -refreshNodes2yarn rmadmin –refreshNodes - 在hdfs页面观察节点状态
等待退役节点状态为 decommissioned 这就意味着该下线节点已经把数据复制给其他的节点。221等待退役节点状态为 decommissioned2这就意味着该下线节点已经把数据复制给其他的节点。 - 关闭退役节点的进程
hadoop-daemon.sh stop datanode yarn-daemon.sh stop nodemanager221hadoop-daemon.sh stop datanode2yarn-daemon.sh stop nodemanager - 最后如果有需要 还可以针对集群再次进行负载均衡
首先调整网络传输数据的带宽 默认是64M hdfs dfsadmin -setBalancerBandwidth 67108864 然后负载均衡的服务 设置负载均衡的差异值 默认10% start-balancer.sh -threshold 5 等待其自动负载均衡完毕551首先调整网络传输数据的带宽 默认是64M2hdfs dfsadmin -setBalancerBandwidth 6710886434然后负载均衡的服务 设置负载均衡的差异值 默认10%5start-balancer.sh -threshold 5 等待其自动负载均衡完毕
- 在主节点所在的机器配置退役节点的黑名单机制
- 原理:增加、删除那些角色?