本文主要从字节码和内存占用的角度介绍自动拆箱装箱对运算中性能的影响。
如果要看懂字节码,需要了解JVM的虚拟机栈的结构和代码的执行流程,可参阅《深入理解Java虚拟机》
本文部分参考了如下文章的内容:
Java 性能要点:自动装箱/ 拆箱 (Autoboxing / Unboxing)
最近在做华为2020年的软件挑战赛,其中经常会用List来保存Integer类的数值,在做性能优化的时候想到了装箱/拆箱的性能损失,特意实验了一下。
以下代码从0开始一直加到int类型所能表达的最大值。
long start = System.currentTimeMillis();
Long sum = 0L; // 使用包装类相加
for (long i = 0; i < Integer.MAX_VALUE; i++) {
sum += i;
}
System.out.println(sum);
long end = System.currentTimeMillis();
System.out.println("耗时:"+(end-start)/1000.0);
// 输出:
// 2305843005992468481
// 耗时:15.175
start = System.currentTimeMillis();
long sum = 0L;
for (long i = 0; i < Integer.MAX_VALUE; i++) {
sum += i; // 使用基本数据类型相加
}
System.out.println(sum);
long end = System.currentTimeMillis();
System.out.println("耗时:"+(end-start)/1000.0);
// 输出:
// 2305843005992468481
// 耗时:1.643
两者代码的区别仅仅在于前者的sum为包装类Long,后者的sum为基本类型long
原因分析
简而言之:装箱和拆箱造成的性能损失。装箱会在堆空间中创建包装类,频繁的创建会导致导致堆空间碎片很多
包装类(Wrapper Class): Java是一个面向对象的编程语言,但是Java中的八种基本数据类型却是不面向对象的,为了使用方便和解决这个不足,在设计类时为每个基本数据类型设计了一个对应的类进行代表,这样八种基本数据类型对应的类统称为包装类(Wrapper Class),包装类均位于java.lang包。
装箱(boxing):基本数据类型->包装类型(以Integer为例)
int a = 5;
// 构造函数法
Integer a1 = new Integer(a); // 数值类型转包装类
Integer a2 = new Integer(5);
Integer a3 = new Integer("5"); // 字符串类型转包装类
// Integer.valueOf()
Integer a4 = Integer.valueOf(a);
Integer a5 = Integer.valueOf(5);
此处需要注意的是,包装类的初始化会在堆中申请空间。不管使用new Integer()还是Integer.valueOf()。因为Integer.valueOf()本质上是通过工具类的形式,创建了新的Integer对象,不过是要先查询创建的数值是否在缓存池(-128, 127)中。
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
拆箱(unboxing):包装类->基本数据类型(以Integer为例)
Integer b = new Integer(5); // 假设我们已经有了一个包装类
// 调用xxValue()方法
int b1 = b.intValue(); // 转化为int类型
double b2 = b.doubleValue(); // 转化为double类型
long b3 = b.longValue(); // 转化为long类型
JDK自从1.5版本以后,就引入了自动拆装箱的语法,也就是在进行基本数据类型和对应的包装类转换时,系统将自动进行。
//编译器执行了Integer a = Integer.valueOf(5)
Integer a = 5;
//自动拆箱,实际上执行了 int b = a.intValue()
int b = a;
字节码角度理解包装类+=发生了什么?
以一段简单的代码为例:
Integer a = 5;
a+=1;
其字节码内容为(字节码的行号不一定连续):
0 iconst_5
1 invokestatic #16 <java/lang/Integer.valueOf>
4 astore_1
5 aload_1
6 invokevirtual #22 <java/lang/Integer.intValue>
9 iconst_1
10 iadd
11 invokestatic #16 <java/lang/Integer.valueOf>
14 astore_1
我们可以看出:
Integer a = 5对应字节码的0,1,4:把常量5压入栈中->隐式调用了Integer,valueOf()->存储新的包装类的地址值到变量a
a+=1对应了6-14行:加载变量a -> 拆箱为int基本类型(调用intValue)-> 把常量1压入栈中 -> 弹出1和拆箱后的a的int类型的值并相加,将相加后的值压回到栈中(还是int)->调用Integer.valueOf(),将结果装箱-> 存储新的包装类的地址值到变量a
小结:我们可以看出对包装类进行运算,则需要先拆箱,后装箱。这一过程还需要向堆中申请空间。相比而言,基本类型的运算则高效很多
int a = 5;
a += 1;
其字节码为:
0 iconst_5
1 istore_1
2 iinc 1 by 1
基本数据类型的运算,都是在栈中进行。
从内存占用的角度理解包装类的+=
使用JDK自带的Jconsole工具,来查看前面两段代码的内存占用。
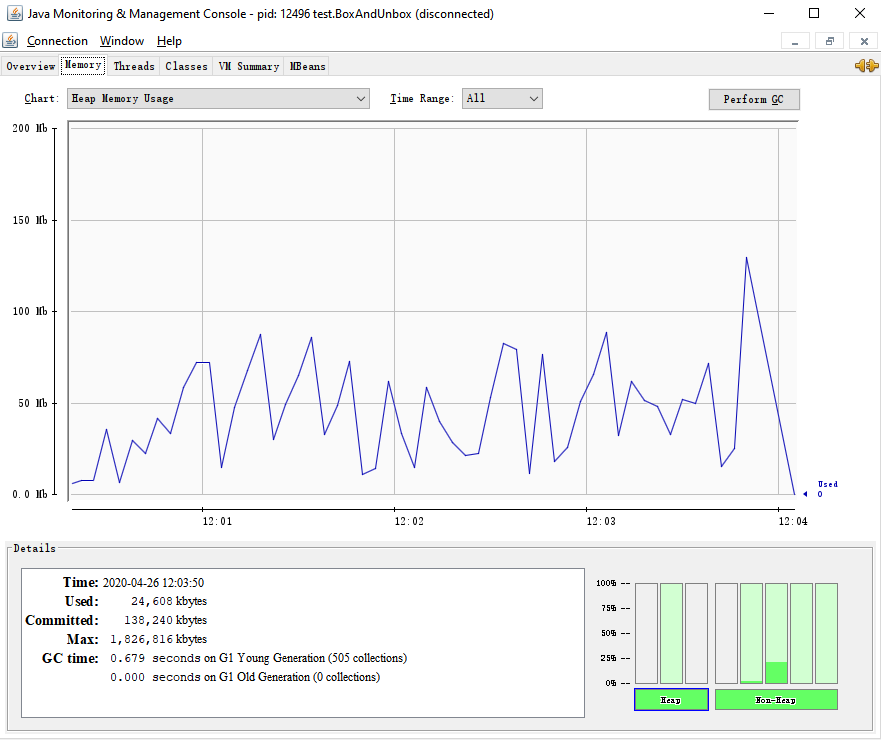
Long(包装类)的内存占用情况
基本数据类型的内存占用情况
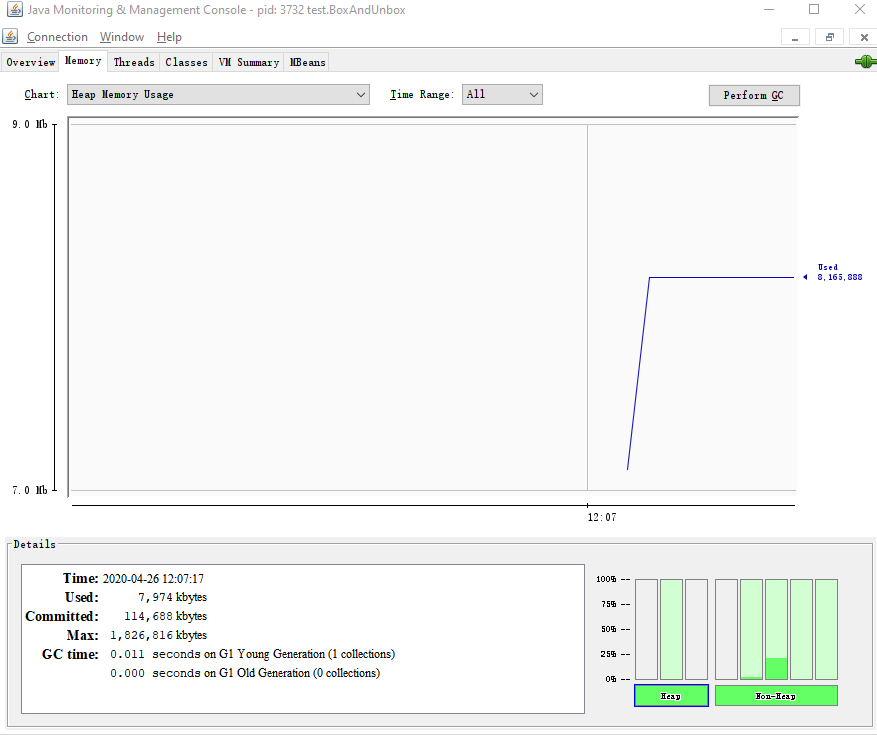
程序刚开始执行时,仅占用8M左右的内存。使用包装类存储运算结果,会导致内存占用高达80M,峰值达到138M,并且年轻代进行了505次垃圾回收;使用基本数据类型时,内存占用始终保持在8M左右,并且没有垃圾回收。
因此,我们可以得出:对包装类进行频繁的运算会占用很多内存空间,导致执行效率不高。
增强型foreach循环遍历包装类的集合
我们知道了包装类进行运算会使得效率低下,那么在遍历的时候,我们要怎么做呢?哪种写法会好些呢?
例如下面这几种相加的方法有何区别呢?
// 使用流生成0到40000000的List
List<Long> arr = LongStream.rangeClosed(0, 40000000).boxed().collect(Collectors.toList());
// ①在for中取取变量时为基本类型, 结果存放为基本类型
long start = System.currentTimeMillis();
long sum = 0;
for(long l:arr) { // 临时变量l在栈中创建,直接将arr中的元素转化为LongValue
sum += l;
}
System.out.println(sum);
long end = System.currentTimeMillis();
System.out.println("耗时:"+(end-start)/1000.0);
// ② 在for中取取变量时为包装类型,结果存放为基本类型
start = System.currentTimeMillis();
long Sum = 0L;
for(Long l:arr) { // 临时变量l在堆中创建
Sum += l; // 相加时转时调用l.longValue()
}
System.out.println(Sum);
end = System.currentTimeMillis();
System.out.println("耗时:"+(end-start)/1000.0);
// ③ 在for中取取变量时为包装类型,结果存放为包装类
start = System.currentTimeMillis();
Long SUM = 0L;
for(Long l:arr) {// 临时变量l在堆中创建
SUM += l; // l和SUM都调用longValue(),完成相加后再装箱
}
System.out.println(SUM);
end = System.currentTimeMillis();
System.out.println("耗时:"+(end-start)/1000.0);
// 输出:
//800000020000000
//①耗时:0.269
//800000020000000
//②耗时:0.326
//800000020000000
//③耗时:1.089
字节码文件此处就不贴了,带上循环显得有些繁琐。变量重复使用还需要局部变量表。
第一种方式的速度最快,其局部变量l为基本类型,仅需要在栈中申请空间;其结果Sum也保存在栈中;拆箱发生在元素取出时。
第二种方式比第一种略慢,其局部变量l为包装类,需要在堆中申请空间;但其结果也保存在栈中;拆箱发生在两数相加时。
第三种方式最慢,其局部变量l为包装类,需要在堆中申请空间;其结果SUM也需要在堆中申请空间;要命的是,两数相加时均发生拆箱操作,相加之后又要创建新的包装类。
总结
-
包装类在进行计算时(包装类与包装类/包装类与基本类型)都会自动拆箱。
-
其结果如果仍然用包装类存储,则会再次发生装箱。
-
频繁的拆箱装箱会导致内存碎片过多,引发频繁的垃圾回收,影响性能。