上一次记录线上问题还是在2018年【问题记录】,最近线上日活突破巅峰,又炸了。记录下。
线上几天连续活动,活动基本的刺激用户都上线操作某个业务。通过广告,内部通知,App全量推送等方式激活。
晚上7.30左右就开始告警。到8.00其实已经很多用户在排队。2G的带宽直接塞满,mysql,redis,memcache,各个.net core项目相继也出现异常。
前期没有做好充足的准备,其实应该在晚上7点左右就应该重视。告警都没有重视,得过且过。
后面的应对方案:
1.cdn
2.索引碎片优化重组,慢查询日志查看
3.dump内存cpu分析
4.内部带宽优化 部分redis memcache缓存移动到进程内存
5.弹机器
6.运维memcache集群不集中到一台物理机器,进行迁移。增加内部带宽优化
cdn:
kibana上面nginx的日志分析接口的访问量,看到有大量的静态资源没有走cdn,马上改掉。其次有意思的发现钉钉访问我们图片资源的时候会带上参数(钉钉自己的cid等参数),直接导致就算访问cdn服务器资源地址,cdn也会来我们自己的项目索要资源,后续cdn脚本忽略了请求后面的url参数
sqlserver,mysql:
sqlserver看到有部分表的索引碎片达到10%以上,甚至90%。且表里面的数据量十分庞大。立马索引碎片优化。mysql慢查询日志开启,检查sql是否有根据索引进行查询。其次还发现有一句sql对索引字段进行频繁的删除修改(是一个定时的回收任务),后面直接改了表结构解决
dump:
线上cpu满,内存也满。直接dump看。用的是dotnet-dump【以前的记录】
首先是cpu满了问题,dump 分析线程堆栈信息,发现是因为用了lazy去延迟获取一个资源对象,用的是LazyThreadSafetyModel,即当一个线程已经在拿的时候,其他线程等着。在并发很高的情况下,直接卡死(项目在并发很高的情况下重启了)。后面直接改成单例对象。

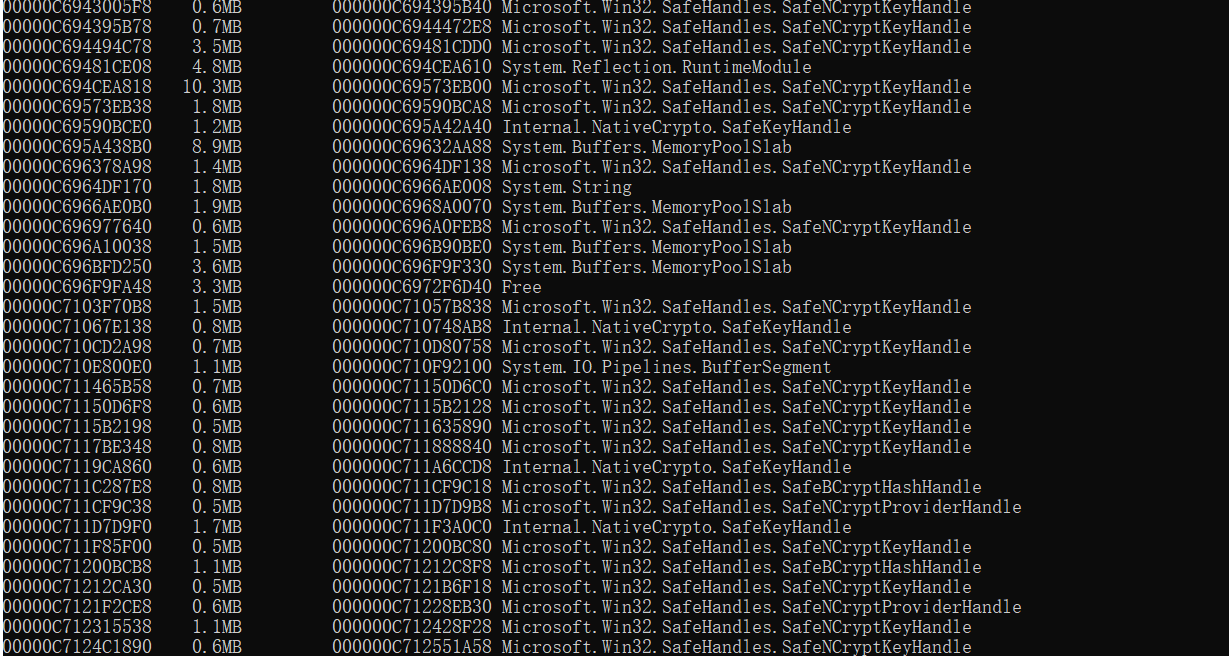
其次是内存问题,发现有大面积的Microsoft.Win32.SafeHanfles.SafeCryptKeyHandle对象。发现是应为我们在使用.net core加解密对象的时候,没有去dispose,也就是每次都是new一下,而且解密异常的时候直接return string.empty。。。。23333。 后面直接加了using解决
部分redis memcache缓存移动到进程内存
线上看到外部带宽塞满,其实内部带宽也满了。 直接导致运维都无法操作。想上个跳板机看一下都难。在grafana看到。redis和memcache占用的很高。原因:我们一开始的思想就是一些相对固定不变的接口返回值都放到redis(例如固定的字符串(角色广告,动态导航路由))。但是这些资源都很大,访问频繁,用户量大高并发下,直接给你撑满带宽。后面部分这种资源用进程缓存去处理了,一开始用自己写的ConcurrentDictionary,发现没这么简单(不仅仅是线程安全,还有回收,面向接口等思想)后面直接用了ASP.NET Core IMemoryCache对象。MemoryCache源码地址,源码里面感觉有点不好就是每次查询都去回收,后续可能改成IhostService去起一个线程定时回收。
其实这点 有好处也有坏处。 也不建议以后啥都往进程内存放,放多了也不好
总结就到这把。希望下次可以不用再写了