20172319 2018.12.07
哈夫曼编码
课程名称:《程序设计与数据结构》
学生班级:1723班
学生姓名:唐才铭
学生学号:20172319
实验教师:王志强老师
课程助教:张师瑜学姐、张之睿学长
实验时间:2018年12月07日
必修/选修:必修
目录
实践内容
设有字符集:S={a,b,c,d,e,f,g,h,i,j,k,l,m,n.o.p.q,r,s,t,u,v,w,x,y,z}。
给定一个包含26个英文字母的文件,统计每个字符出现的概率,根据计算的概率构造一颗哈夫曼树。
并完成对英文文件的编码和解码。
要求:
(1)准备一个包含26个英文字母的英文文件(可以不包含标点符号等),统计各个字符的概率
(2)构造哈夫曼树
(3)对英文文件进行编码,输出一个编码后的文件
(4)对编码文件进行解码,输出一个解码后的文件
(5)撰写博客记录实验的设计和实现过程,并将源代码传到码云
(6)把实验结果截图上传到云班课
满分:6分。
酌情打分。
实践要求
- 完成蓝墨云上哈夫曼编码测试相关的活动,及时提交代码运行截图和码云Git链接,截图要有学号水印,否则会扣分。
- 完成实验、撰写实验报告,实验报告以博客方式发表在博客园,注意实验报告重点是运行结果,遇到的问题(工具查找,安装,使用,程序的编辑,调试,运行等)、解决办法(空洞的方法如“查网络”、“问同学”、“看书”等一律得0分)以及分析(从中可以得到什么启示,有什么收获,教训等)。报告可以参考范飞龙老师的指导。
- 严禁抄袭,有该行为者实验成绩归零,并附加其他惩罚措施。
实践步骤
设有字符集:S={a,b,c,d,e,f,g,h,i,j,k,l,m,n.o.p.q,r,s,t,u,v,w,x,y,z}。
给定一个包含26个英文字母的文件,统计每个字符出现的概率,根据计算的概率构造一颗哈夫曼树。
并完成对英文文件的编码和解码。
要求:
(1)准备一个包含26个英文字母的英文文件(可以不包含标点符号等),统计各个字符的概率
(2)构造哈夫曼树
(3)对英文文件进行编码,输出一个编码后的文件
(4)对编码文件进行解码,输出一个解码后的文件
(5)撰写博客记录实验的设计和实现过程,并将源代码传到码云
(6)把实验结果截图上传到云班课
满分:6分。
酌情打分。
前期准备:
- 预先下载安装好IDEA 。
需求分析:
- 需要了解、理解哈夫曼编码的相关知识
代码实现及解释
(1)准备一个包含26个英文字母的英文文件(可以不包含标点符号等),统计各个字符的概率
- 在src目录下右键,新建文件,输入文件名,文本文件,之后将自己所需内容放入即可。
- 读取文件内容:
File fromFile = new File("English-text");
// 创建字符输入流
Reader reader = null;
String data = "";
List temp = new LinkedList();
try {
reader = new FileReader(fromFile);
// 循环读取(打印)
int content = reader.read();
while (content != -1) {
System.out.print((char) content);
temp.add(content);
data += (char) content;
content = reader.read();
}
System.out.println();
-
文件中可能有些字符如: 之类的,可以使用replace方法将其替换成“”字符。
-
实现截图如下:

-
统计各个字符出现的概率:
public static void printStr(String str, int[] Probabilities, String[] Data ) {
if (str == null || "".equals(str)) {
System.out.println("字符串不能为空!");
return;
}
Map<String, Integer> pMap = new HashMap<String, Integer>();
String[] split = str.split("");
for (int i = 0; i < split.length; i++) {
if (!"".equals(split[i]) && pMap.containsKey(split[i])) {
pMap.put(split[i], pMap.get(split[i]) + 1);
} else if (!"".equals(split[i])) {
pMap.put(split[i], 1);
}
}
Set<String> keySet = pMap.keySet();
int total = 0;
int i = 0;
for (String string : keySet) {
total += pMap.get(string);
}
for (String string : keySet) {
Probabilities[i] =pMap.get(string) ;
Data[i] = string;
System.out.println(string + "出现的概率:" + "分数: " + pMap.get(string) + "/" + total
+ " " + "小数:" + (double) pMap.get(string) / total);
i++;
}
}
- 实现截图如下:
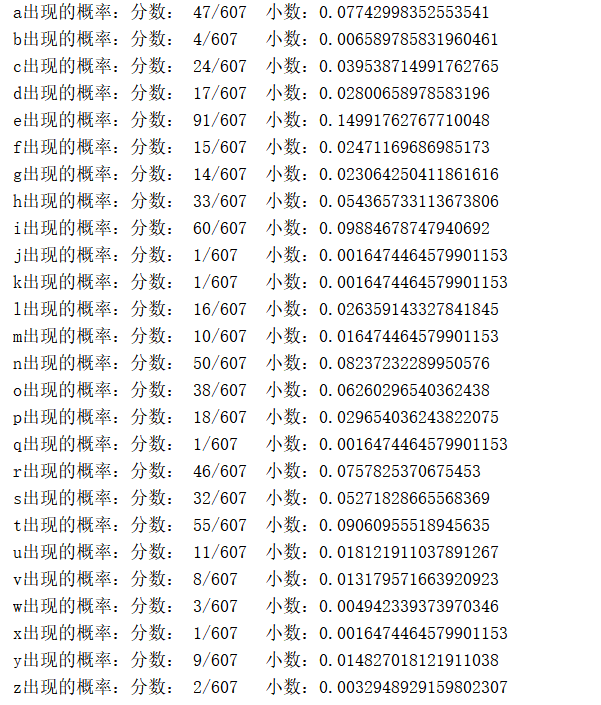
(2)构造哈夫曼树
public static <T> HuffmanNode<T> CreatTree(List<HuffmanNode<T>> HuffmanNode) {
while (HuffmanNode.size() > 1) {
Collections.sort(HuffmanNode);
HuffmanNode<T> left = HuffmanNode.get(HuffmanNode.size() - 1);
HuffmanNode<T> right = HuffmanNode.get(HuffmanNode.size() - 2);
HuffmanNode<T> parent = new HuffmanNode<T>(null,left.getWeight()
+ right.getWeight());
parent.setLeftChild(left);
parent.setRightChild(right);
HuffmanNode.remove(left);
HuffmanNode.remove(right);
HuffmanNode.add(parent);
}
return HuffmanNode.get(0);
}
public static <T> List<HuffmanNode<T>> breadth(HuffmanNode<T> Root) {
List<HuffmanNode<T>> list = new ArrayList<HuffmanNode<T>>();
Queue<HuffmanNode<T>> queue = new ArrayDeque<HuffmanNode<T>>();
if (Root != null) {
queue.offer(Root);
}
while (!queue.isEmpty()) {
list.add(queue.peek());
HuffmanNode<T> node = queue.poll();
if (node.getLeftChild() != null) {
queue.offer(node.getLeftChild());
}
if (node.getRightChild() != null) {
queue.offer(node.getRightChild());
}
}
return list;
}
}
- 实现截图如下:


(3)对英文文件进行编码,输出一个编码后的文件
public String toHufmCode(String str) {
for (int i = 0; i < str.length(); i++) {
String c = str.charAt(i) + "";
search(root, c);
}
return hfmCodeStr;
}
private void search(HNode root, String c) {
if (root.lChild == null && root.rChild == null) {
if (c.equals(root.data)) {
hfmCodeStr += root.code;
}
}
if (root.lChild != null) {
search(root.lChild, c);
}
if (root.rChild != null) {
search(root.rChild, c);
}
}
- 实现截图如下:

(4)对编码文件进行解码,输出一个解码后的文件
public String CodeToString(String codeStr) {
int start = 0;
int end = 1;
while(end <= codeStr.length()){
target = false;
String s = codeStr.substring(start, end);
matchCode(root, s);
if(target){
start = end;
}
end++;
}
return result;
}
private void matchCode(HNode root, String code){
if (root.lChild == null && root.rChild == null) {
if (code.equals(root.code)) {
result += root.data;
target = true;
}
}
if (root.lChild != null) {
matchCode(root.lChild, code);
}
if (root.rChild != null) {
matchCode(root.rChild, code);
}
}
}
- 实现截图如下:

测试过程及遇到的问题
- 问题1: 无任何记录。
- 解决: