基本数学假设:各个维度上的特征被分类的条件概率之间是相互独立的。所以在特征关联性较强的分类任务上的性能表现不佳。
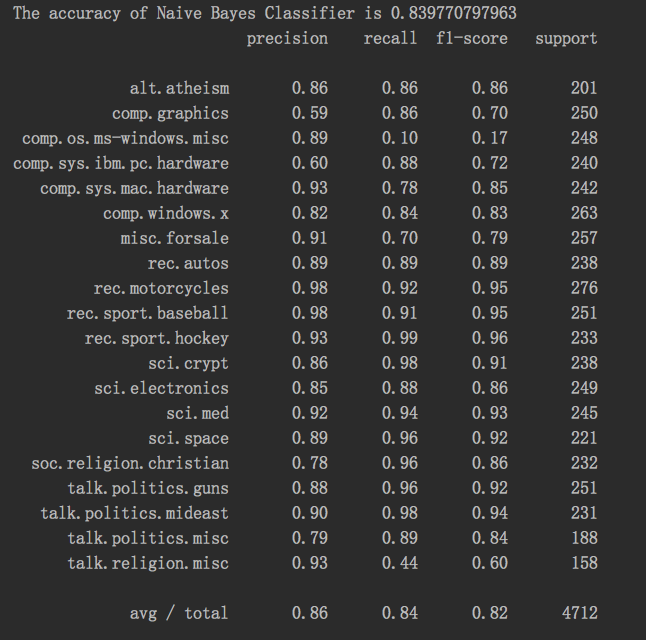
#coding=utf8 # 从sklearn.datasets里导入新闻数据抓取器fetch_20newsgroups。 from sklearn.datasets import fetch_20newsgroups # 从sklearn.model_selection中导入train_test_split用于数据分割。 from sklearn.model_selection import train_test_split # 与之前预存的数据不同,fetch_20newsgroups需要即时从互联网下载数据。 news = fetch_20newsgroups(subset='all') # 随机采样25%的数据样本作为测试集。 X_train, X_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25, random_state=33) # 从sklearn.feature_extraction.text里导入用于文本特征向量转化模块。 from sklearn.feature_extraction.text import CountVectorizer vec = CountVectorizer() X_train = vec.fit_transform(X_train) X_test = vec.transform(X_test) # 从sklearn.naive_bayes里导入朴素贝叶斯模型。 from sklearn.naive_bayes import MultinomialNB # 从使用默认配置初始化朴素贝叶斯模型。 mnb = MultinomialNB() # 利用训练数据对模型参数进行估计。 mnb.fit(X_train, y_train) # 对测试样本进行类别预测,结果存储在变量y_predict中。 y_predict = mnb.predict(X_test) # 从sklearn.metrics里导入classification_report用于详细的分类性能报告。 from sklearn.metrics import classification_report print 'The accuracy of Naive Bayes Classifier is', mnb.score(X_test, y_test) print classification_report(y_test, y_predict, target_names=news.target_names)
结果: