Scrapy框架简介
scrapy是基于Twisted的一个第三方爬虫框架,许多功能已经被封装好,方便提取结构性的数据。
其可以应用在数据挖掘,信息处理等方面。提供了许多的爬虫的基类,可更简便使用爬虫。
Twisted有些特殊的地方是它是事件驱动的,并且比较适合异步的代码。
对于会阻塞线程的操作包含访问文件、数据库或者Web、产生新的进程并需要处理新进程的输出(如运行shell命令)、
执行系统层次操作的代码(如等待系统队列),Twisted提供了允许执行上面的操作但不会阻塞代码执行的方法。
Scrapy 的组成部分: 1. 引擎、2.下载器、3. 爬虫、4. 调度器、5. 管道(item和pipeline)
以上五部分 只需要关注 爬虫和管道 即可
- spiders:蜘蛛或爬虫,分析网页的地方,主要的代码写在这里
- 管道: 包括item和pipeline,用于处理数据
- 引擎: 用来处理整个系统的数据流,触发各种事务(框架的核心)
- 下载器: 用于下载网页内容,并且返回给蜘蛛(下载器基于Twisted的高效异步模型)
- 调度器: 用来接收引擎发过来的请求,压入队列中等处理任务
Scrapy框架安装
Mac安装步骤
- 安装依赖库Twisted。 打开终端 pip install twisted
- 安装其框架Scrapy。 pip install scrapy
wid安装步骤
- 在线安装和Mac相同, pip install twisted
- 离线安装 需要在网站http://www.lfd.uci.edu/~gohlke/pythonlibs#twisted下载响应的版本,然后想下载好的文件拖到 pip install 后面
- 安装其框架和Mac相同
- 安装 pip install pywin32
Scrapy工程
工程创建:
- 先在终端: cd到存放的目录下并进入虚拟环境
- 创建项目: scrapy startproject 工程项目名
- cd到项目的根目录 [一个项目一个虚拟环境的创建虚拟环境方式]
- 虚拟环境: mkvirtualenv 虚拟环境名 [建虚拟环境要在项目的根目录下建]
- 进入环境: source 虚拟环境名/bin/activate [虚拟环境目录在此项目的根目录下]
- 建包文件: touch requirements.txt [新建一个txt文件,用来存放安装的工具包名称]
- 进入文件: vim requirements.txt [编辑输入需要的包文件名称,并保存退出]
- 执行文件: pip install -r requirements.txt [执行该文件会安装里面的包文件;可以pip freeze > requirements.txt生成该文件]
- 创建爬虫: scrapy genspider 爬虫名 域名 [爬虫名最好起爬哪一个板块叫哪一个板块名称,不要和项目名同名]
- 打开项目: 用pycharm打开此项目。
- 然后再在: pycharm中打开此项目(空工程)
- 创建爬虫: scrapy genspider 爬虫名 该网站域名 pycharm终端[gyp@localhost ~/pyword/spider05/MyScrapy] $scrapy genspider budejie budejie.com
- 运行爬虫: scrapy crawl 爬虫名 [-o xx.json/xml/csv] scrapy crawl qiubai -o budejie.json
- 代码调试: scrapy shell
- 查看版本: scrapy version
- 具体查看: 查看运行scrapy的python版本:
- which scrapy 找到scrapy文件存储路径 。scrapy文件是一个可执行文件(也可说是一个python文件)
- vim 查找到的路径。打开此可执行文件后的第一行 #!表示执行此可执行文件的解释器(python)的路径
- 此python解释器的路径 -V 即可知道此执行文件scrapy的解释器python的版本号是多少。
工程配置:
- 在spiders里面解析数据 (解析)。spiders目录下budejie.py为主要的爬虫代码,包括了对页面的请求以及页面的处理
- 根据需求编写item (爬取)。 items.py里存放的是要爬取数据的字段信息
- 在管道中处理解析完的数据 (存储)。pipeline主要是对spiders中爬虫的返回的数据的处理,可以写入到数据库,也可以写入到文件。
整体思路:
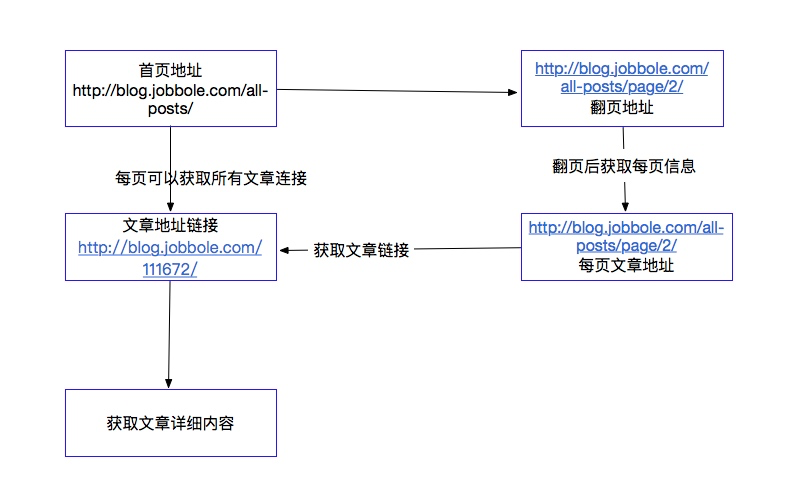
简单体验:
- scrapy genspider lab lab.scrapyd.cn
- lab.py 爬虫文件中
1 # -*- coding: utf-8 -*- 2 import scrapy 3 4 class LabSpider(scrapy.Spider): 5 name = 'lab' 6 allowed_domains = ['lab.scrapyd.cn'] 7 start_urls = ['http://lab.scrapyd.cn/'] 8 # response是<class 'scrapy.http.response.html.HtmlResponse'>类型。 9 # HtmlResponse继承自TextResponse;TextResponse继承自Response 10 def parse(self, response): 11 # 将response中的内容打印 12 print(response.text) 13 # scrapy中默认支持xpath和css选择器方式。源码TextResponse有显示 14 # xp = response.xpath('//*[@id="main"]/ol/li[@class="next"]/a/@href') 15 # xp = response.css('.next a::attr(href)') 16 xp = response.xpath('//*[@id="main"]/ul/li/a/@href') 17 print(xp.extract_first()) # 获取第一个 18 print(xp.extract()) # 获取所有,复数在列表中存 19 print(xp.get()) # 获取第一个 20 print(xp.getall()) # 获取所有,复数在列表中存。如果没有返回空列表,不报错建议使用 21 print(xp[0]) # 获取第一个,结果是Selecter对象。如果没有返回None不建议使用 22 23 next = xp.extract_first() 24 # self.logger.warning(next) 25 if next is not None: 26 # scrapy.Request(路由, callback=self.parse回调函数回调自己) 27 yield scrapy.Request(next, callback=self.parse) 28 --------------------------- 分割 代码可直接运行,只是为了整理笔记------------------------------- 29 # 结合使用extract() 30 data = response.xpath('//*[@id="main"]/div/span/text()').extract() 31 for item in data: 32 self.logger.error(item)


1 # 爬虫文件 2 # -*- coding: utf-8 -*- 3 import scrapy 4 5 class JokeSpider(scrapy.Spider): 6 name = 'joke' 7 allowed_domains = ['xiaohua.zol.com.cn'] 8 start_urls = ['http://xiaohua.zol.com.cn/new/'] 9 10 def parse(self, response): 11 joke_list = response.xpath('/html/body/div/div/ul/li') 12 for joke in joke_list: 13 joke_title = joke.xpath('./span[@class="article-title"]/a/text()').extract_first() 14 print(joke_title) 15 16 page_next = response.xpath('//a[@class="page-next"]/@href').extract_first() 17 print(page_next) 18 if page_next: 19 """ 20 结果:page_next = "/new/2.html" 21 要求:page_next = "http://xiaohua.zol.com.cn/new/2.html" 22 response.urljoin进行路径拼接 23 """ 24 page_next = response.urljoin(page_next) 25 yield scrapy.Request(page_next, callback=self.parse)
遗漏补充:
logging组成:
在所有的编程中都存在的,用来打印日志。作用:问题追踪、数据分析
-
-
logger、
-
handler、处理器对象
-
formatter、格式化对象
-
filter、过滤器
- LogRecord、日志对象
-
-
级别
-
debug: 调试
-
info: info信息
-
warning:警告提示
-
error: 错误提示[编写的代码运行错误]
-