一看这个标题,你就会看见我对搜索的评价是很高的,称之为万能,为什么呢?原因有几点:
1)搜索可以解决很多以前小编不会的题,倘若世界上消失了搜索,我该怎么做这些题呢?
2)自从学了高级数据结构后,小编对树和图表示一脸茫然,怎么存,又怎么找,都是大问题,单说个遍历都是大问题,会了搜索之后,就打开了二维世界的大门,解决各种奇妙的问题。
3)搜索能解决各种题,但并不一定就意味着它不会超时,超时是搜索的一大弊端,这时我们会抛弃它,寻找其他算法。可在比赛时可不是想怎么提交就怎么提交的,不可能像oj上的题目一遍又一遍的重写,怎么办呢?我们往往会用搜索写出的程序与更优的算法写出的程序进行对拍,便可以知道新写的代码是否存在问题。
没错,说了这么多都是搜索的好处,可是究竟搜索是个什么玩意呢?听我细细说来。
什么是搜索?
说到搜索,你会先想到什么呢?我第一反应想到的是百度一下,你就知道,这是人尽皆知的搜索引擎,不会搜索能让我们搜索百度吧,那不就真的太万能了!不,我可以很明确的告诉你,此搜索非彼搜索,信息学奥赛的搜索是一种有目的的查找一个问题所有解的算法,并不能连接网络。搜索主要分为两大类,分别是深度优先搜索和广度优先搜索,深度优先搜索简称深搜,是很容易学会的也好想出来;广度优先搜索的简称就多了,什么广搜、宽搜都是它的别称,欲知详情如何,请听我细细讲解。
深度优先搜索(dfs)
深度优先搜索是我最先学会的,也是两种搜索中最简单的,我对它的评价很简单:一条路走到黑,空口说太费劲了,先举个栗子吧。
【问题引入】 假设现在有一个地图(如图),正好你想要从起点(1,1)到终点(5,5),问你有多少种走法?
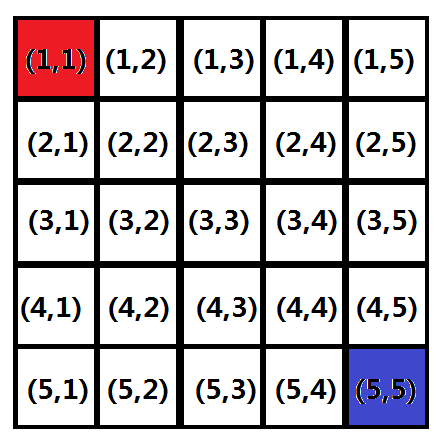
回想一下之前学过的算法,在二维的世界里连立足之地都没有,于是我们不得不请出深度优先搜索。
这个算法正如其名,“深度优先”就是说盲目的沿着一条可能正确的路走下去,如果碰巧对了那就结束算法,否则就退回去重走。简单来描述就是碰运气,这种算法具有盲目性,但是却很好用,好用在什么地方呢?那就是编码量很少,深度优先搜索能够准确的利用极其精简的代码完成大批复杂的重复过程,这正是大家最喜爱它的原因。要学会深度优先搜索,那么你的前置技能是递归,为什么这么说呢?因为递归与递推(可以理解为for循环)的最大区别是一个好想,一个减少空间上的浪费,尽管这样我们更乐于去写递归形式下的深度优先搜索,几乎不会见到用for循环写出的深度优先搜索,与其写递推,还不如写广度优先搜索,因此学深度优先搜索之前至少要回递归。
为了后文您能阅读顺畅,先给个深搜的模板:

转换成佷伪的代码就是这样:

可能这样你还是脑海中有一个大大的问号,那就图解吧:
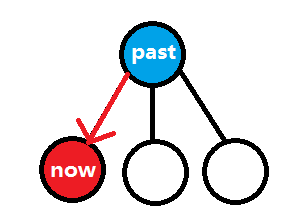
举个栗子,想象是这样的场景,比方说这是你最开始的起点

然后判断它是否到达边界,好的,它没有。于是找到其子状态,随便选一个走,不断这样下去,直到……
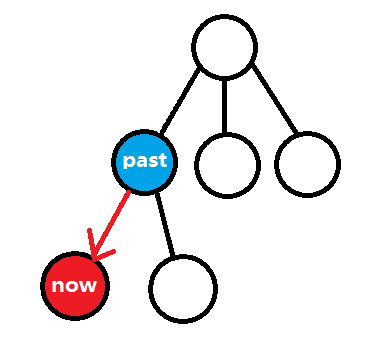
忽然你发现似乎现在的节点拓展不出子状态或达到边界条件,那么就回去重来。
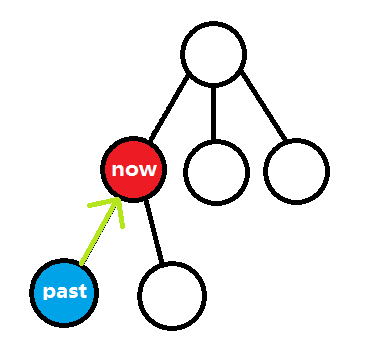
找到之前的下一个子状态,继续搜索下去……
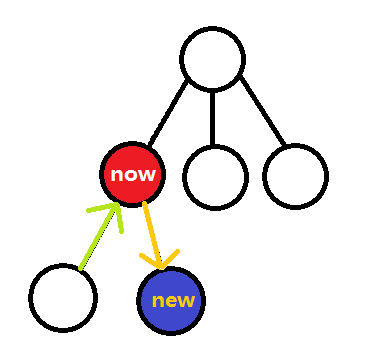
//原谅小编拙劣的画技
这便是深度优先搜索的思路及模板,看不懂也没关系做几道题就好了。
广度优先搜索(bfs)
比起深度优先搜索的一条路走到黑,广搜可是很有目的性的,这就是为什么有些题广搜会更快的缘故,先讲个故事(再次见到了小编拙劣的画技):
有一天一个可爱的火柴人与一个贱兮兮的身泛紫光的火柴人碰面了,不由分说就展开了一场大战,什么大战呢?拿着两个稀饭画质一般的拍子,拍着一个不明飞行物。

but火柴人似乎打输了,于是心情悲伤,通过散步来打发时间,不知不觉就走到了沙漠。

时间一分一秒的过去了,火柴人口渴了,可是它出不去了。

现在这个火柴人没想着怎么出沙漠,一心只想着找到一片绿洲,能找到水源。问题来了,它该怎么办?
难道还要深搜吗?火柴人并不乐意重复地走来走去,它只想尽快喝到水。水源如果越近越好,如果是你,你也一定会这么想,傻子才会沿着一个方向一直走到黑呢!更何况沙漠这么大,如何走到边呢?所以,不要用深搜把火柴人渴死,我们一定会先找一下附件有没有水源。

然后再远一些找……
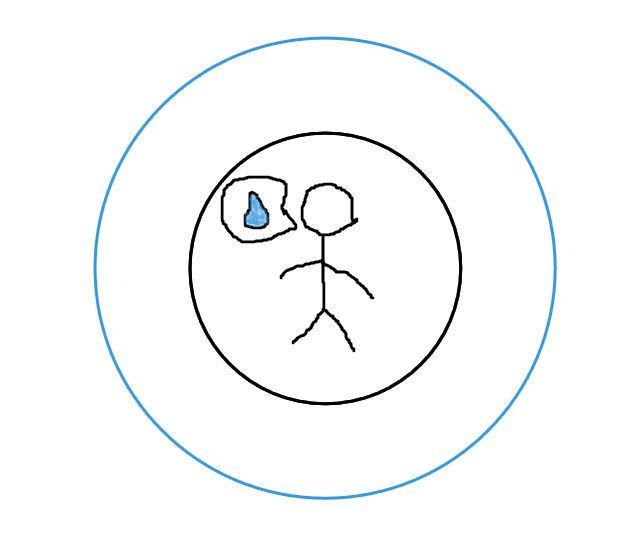
然后再远……
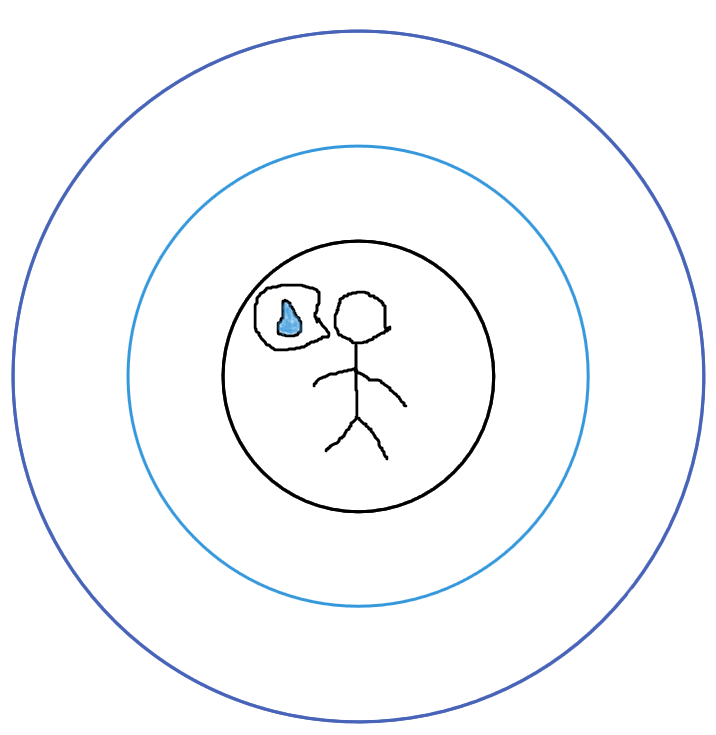
这样的方法比起深搜在很多情况下明智了很多,正如其名,以搜索的广度优先。先寻找较近的,再寻找较远的,因此就深搜和广搜就形成了差异,具体差异在什么地方呢?就举一个栗子吧。
众所周知,树/图是常见的高级数据结构,为了方便的看出,那就以树的遍历为栗吧:
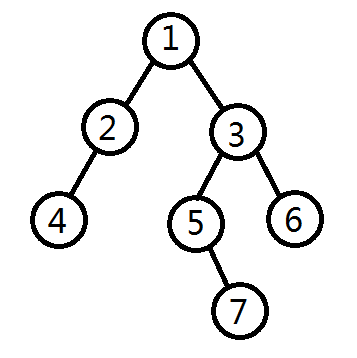
如图,这是一个很普通的树,为了叫法的容易,全部编上了号,看到这里我想你心中一定已经有了答案,深搜与广搜的遍历顺序到底哪里不一样呢?
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
answer:
1.深搜
1)先遍历根节点。
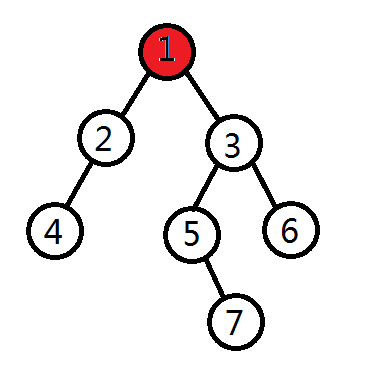
2)遍历左子树
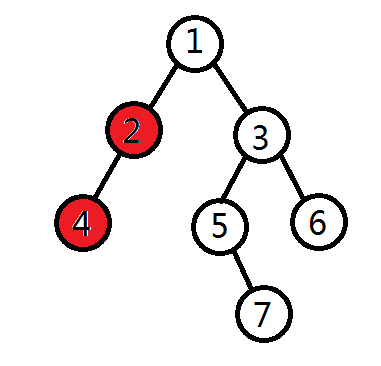
3)遍历右子树
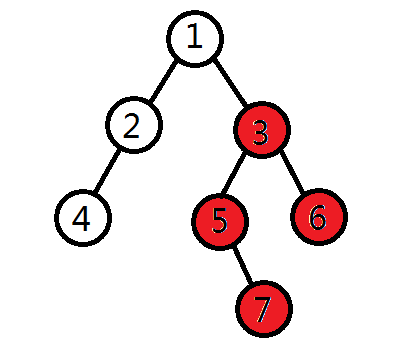
4)最终的遍历顺序为:1,2,4,3,5,7,6。
2.广搜
广搜就不太一样了,他的遍历顺序可以理解为按层来遍历,如图所示:
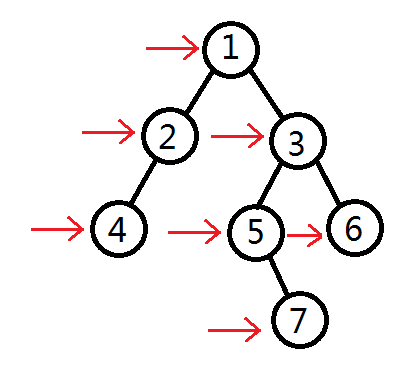
所以最终的顺序为:1,2,3,4,5,6,7。
至于广度优先搜索特别在那里,还是看度娘吧,按照我理解,深搜更像栈,广搜更像队列,具体就是枚举当前状态下所有可能的子状态,并加入队列,不断重复,直到队列为空,具体到底怎么写,还要看一看例题。

例题精讲
一.深度优先搜索
1.P1219 八皇后
测评网站:P1219 八皇后
题解网站:P1219 八皇后
2.P1562 还是N皇后
测评网站:P1562 还是N皇后
题解网站:P1562 还是N皇后
3.P1025 数的划分
测评网站:P1025 数的划分
题解网站:P1025 数的划分
二.广度优先搜索
//请经常关注小编的博客,小编会陆续使这一模块充实起来