一、解决问题
- 如何将特征融合与知识蒸馏结合起来,提高模型性能
二、创新点
- 支持多子网络分支的在线互学习
- 子网络可以是相同结构也可以是不同结构
- 应用特征拼接、depthwise+pointwise,将特征融合和知识蒸馏结合起来
三、实验方法和理论
1.Motivation
DML (Deep Mutual Learning)
- 算法思想:
用两个子网络(可以是不同的网络结构)进行在线互学习,得到比单独训练性能更好的网络
- 损失函数:
传统监督损失函数:
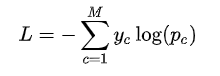
模仿性的损失函数:

单个网络的损失函数:
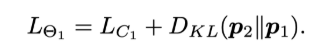
ONE (On-the-FlyNative Ensemble)

- 算法思想:
通过在网络深层次构造多分支结构,每个分支作为学生网络,融合logit分布,生成更强的教师网络,进而通过学生/教师网络的共同在线学习,互相蒸馏,训练得性能优越的单分支或多分支融合模型。
-
logit融合 (Gate Module:FC、BN、ReLU、Softmax):
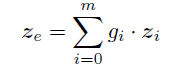
-
损失函数:

DualNet

- 算法思想:
通过融合两个互补parallel networks生成的特征,使得融合后的性能比单独训练的性能更好
-
损失函数:
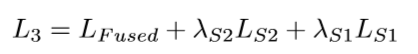
-
启发:结合DML、ONE和DualNet的思想,构造一个支持(相同或者不同的)多个子网络分支进行特征融合的网络结构,进而让融合分类器和分类器进行在线互学习,互蒸馏的方式,从而提高网络的性能。
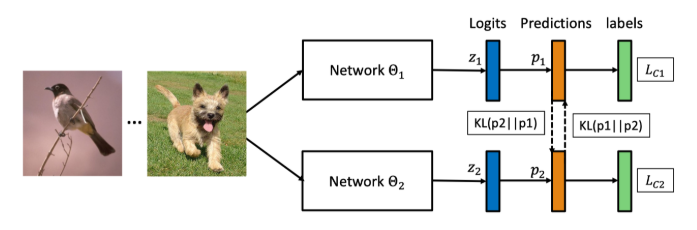
2.Network Architecture

- Fusion Module
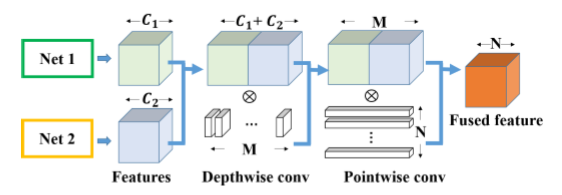
- Fusion Module 将Net1 和Net2 的到的特征张量进行拼接,然后通过Depthwise conv 得到一个通道数为M的特征张量,经过 Pointwise conv 后生成一个通道数为N的特征张量,即为融合后的特征。
- 子网络和融合网络同时训练,将子网络最后一层得到的特征,通过一个Fusion Module进行特征融合,得到融合分类器的概率分布。
3.训练过程
- 软分布概率:

其中,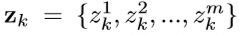
- 集成logit概率分布计算:

- 交叉熵损失函数:
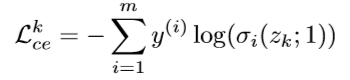
- KL散度损失函数:

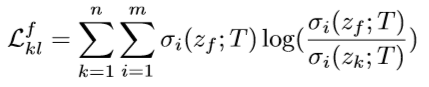
这里有两个KL散度损失函数,分别对应从 Ensemble Classifier 到 Fused Classifier 的知识蒸馏和从 Fused Classifer 到 Sub-network Classifier 的知识蒸馏的损失函数。
- 总的损失函数:
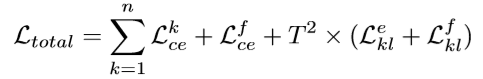
四、实验结果
数据集
- CIFAR-10
- 50k 训练集,10k 测试集
- 10种图像类别,每类 6k 张图片
- CIFAR-100
- 50k 训练集,10k 测试集
- 100种图像类别,每类600张图片
- ImageNet LSVRC2015
- 1.2M 训练集,50k 验证集
- 1000种图像类别
特征融合对比(FFL vs DualNet):
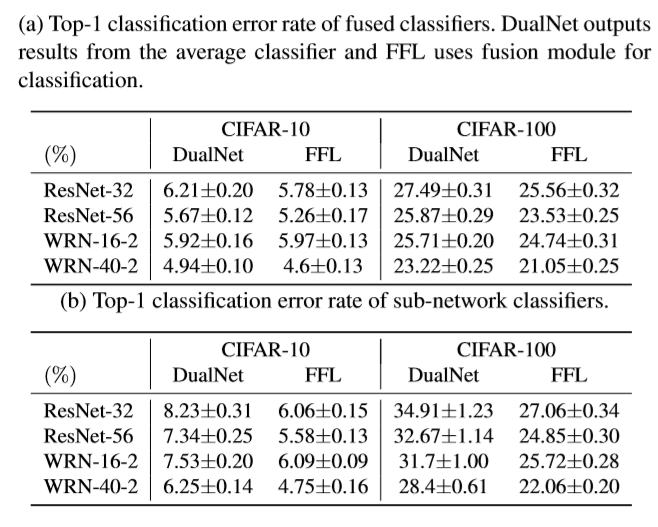
- FFL融合后的性能略比DualNet好
- FFL得到的子网络性能明显比DualNet好
消融实验
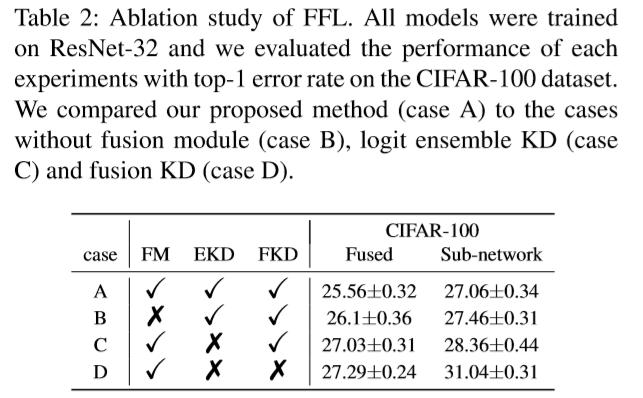
- 缺少任何一个模块都会导致融合分类器和子分类的效果下降,尤其当缺少FKD时,子网络性能下降很多。
在线蒸馏对比(FFL vs ONE):
由于FFL比ONE多了一个Fusion Module为了参数大小公平起见,ONE在Gate模块前多叠加几个残差模块
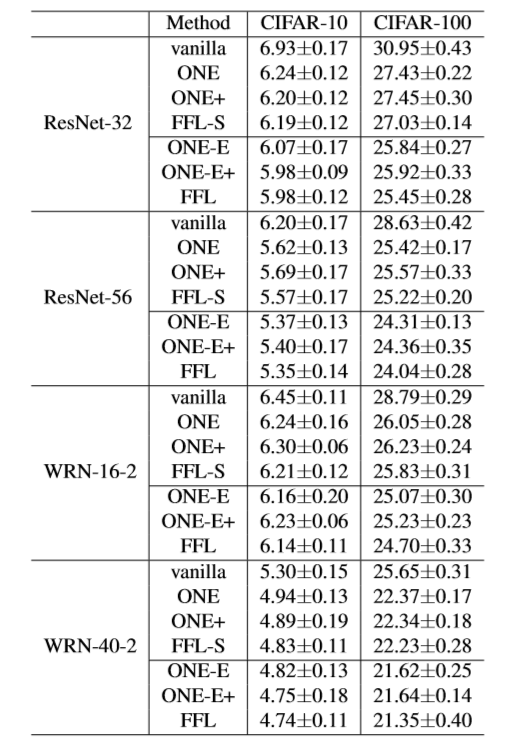
- vanilla 表示单独训练的结果,ONE表示两个子网络的平均结果,ONE-E表示融合后的结果,ONE-E+表示参数与FFL大小一样融合后的结果,FFL-S表示子网络的平均结果,FFL表示融合后的结果
- 即便增加ONE的残差模块,从ONE-E和ONE-E+的对比来看,性能并没有多大提升,甚至有所下降(例如CIFAR-100)
- 从表格发现,FFL比ONE的效果略有提升

分支拓展:
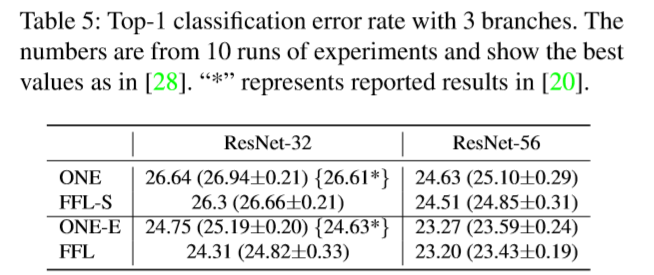
- 随着分支数增多,性能也略有提升。
ImageNet:

- ONE 和 FFL性能相似,FFL效果略好一些。
- 这说明了本文方法一样适用于大规模的数据集
互学习性能对比(FFL vs DML):
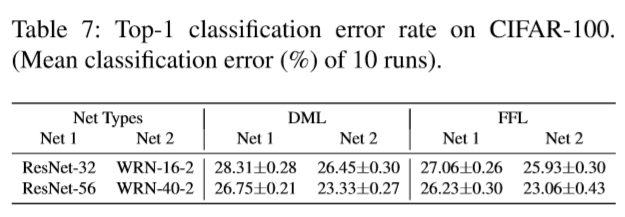
- 虽然参数量FFL比DML多4%,但性能优于DML,也说明了FFL适用于不同子网络结构。
定性分析

- 1-2列,分类都是正确,但FFL关注的特征区域比单独训练的ResNet-34好,且置信度更高
- 3-6列,FFL分类正确,而单独训练的ResNet-34分类错误
- 7-9列,两者分类都是错误的,但是FFL关注的特征区域属于正确类别的关注区域。
- 同时我们发现Subnet的特征热区一直在拟合Fusion的结果,这也验证了互蒸馏的有效性,即的确学习到软概率分布中含有的丰富的错误类别的相关概率信息。
五、 总结
-
结合预训练模型,该方法可以适用于图像检测(RPN特征),图像分割(dense feature),风格迁移等任务。
-
同时兼顾子网络和融合网络的性能,根据实际需要,选择子网络或者融合网络
-
Fusion Module 可以得到更为丰富的图像特征,从而提高整体性能。
-
子网络的选择限制低,可以选择多个相同或者不同的网络构成
-
能够将多个方法的优点结合起来得到更好的方法,实验充分
-
不足:参数量略多一些,以及子网络结构选取的不确定性