一.模块
#这是aa.py文件 print('啦啦啦啦啦啦啦啦') money=1000 def read1(): print('bb->read1->money',money) def read2(): print('bb->read2 calling read1') read1() def change(): global money money=0
这是bb.py文件 # 方式一 """ import aa #只在第一次导入时才执行my_module.py内代码,此处的显式效果是只打印一次'from the my_module.py',当然其他的顶级代码也都被执行了,只不过没有显示效果. import aa import aa import aa # python的优化手段是:第一次导入后就将模块名加载到内存了, # 后续的import语句仅是对已经加载大内存中的模块对象增加了一次引用, # 不会重新执行模块内的语句""" # 方式二 """ #测试一:money与aa.money不冲突 每个模块都是一个独立的名称空间,定义在这个模块中的函数, 把这个模块的名称空间当做全局名称空间,这样我们在编写自己的模块时, 就不用担心我们定义在自己模块 中全局变量会在被导入时,与使用者的全局变量冲突 #bb.py import aa money=10 print(aa.money) ''' 啦啦啦啦啦啦啦啦 1000 ''' """ # 方式三 """ #测试二:read1与aa.read1不冲突 #demo.py import aa def read1(): print('这是本地模块哈哈哈') aa.read1() read1() '''啦啦啦啦啦啦啦啦 bb->read1->money 1000 这是本地模块哈哈哈 ''' """ # 方式四 """ 执行bb.change()操作的全局变量money仍然是aa中的 #demo.py import aa money=1 aa.change() print(aa.money) print(money) ''' 啦啦啦啦啦啦啦啦 0 1 '''""" # 1.为源文件(aa模块)创建新的名称空间,在aa中定义的函数和方法若是使用到了global时访问的就是这个名称空间。 # 2.在新创建的命名空间中执行模块中包含的代码,见初始导入import aa # 方式五 """import aa as c # 给引入aa的模块给aa模块 取一个别名 c print(c.money) """ # 方式六 """ # 导入的函数read1,执行时仍然回到aa.py中寻找全局变量money from aa import read1 money=8222 read1() ''' 啦啦啦啦啦啦啦啦 bb->read1->money 1000 ''' """ # 方式七 """ #测试二:导入的函数read2,执行时需要调用read1(),仍然回到aa.py中找read1() #demo.py from aa import read2 def read1(): print('==========') read2() ''' 啦啦啦啦啦啦啦啦 bb->read2 calling read1 bb->read1->money 1000 ''' """ # 方式八 """ #测试三:导入的函数read1,被当前位置定义的read1覆盖掉了 #demo.py from aa import read1 def read1(): print('==========') read1() ''' 啦啦啦啦啦啦啦啦 ========== ''' """ # 方式九 """# 要特别强调的一点是:python中的变量赋值不是一种存储操作,而只是一种绑定关系 from aa import money,read1 money=100 #将当前位置的名字money绑定到了100 print(money) #打印当前的名字 read1() #读取aa中的名字money,仍然为1000 ''' 啦啦啦啦啦啦啦啦 100 bb->read1->money 1000 ''' """ # 方式十 """ # 多模块导入 from aa import (read1,read2,money) print(money) """ # 方式十一 """ # * 全部导入 from aa import * #将模块my_module中所有的名字都导入到当前名称空间 print(money) print(read1) print(read2) print(change) 啦啦啦啦啦啦啦啦 1000 <function read1 at 0x000001B65DE2BBF8> <function read2 at 0x000001B65DE2BA60> <function change at 0x000001B65DE2BC80> """
自定义模块导入死循环即解决方法
二. 模块搜索文件路径模块的搜索路径指的就是在导入模块时需要检索的文件夹
- 先从内存中已经导入的模块中寻找
- 内置的模块
- 环境变量sys.path中找
1 先从内存中已经导入的模块中寻找
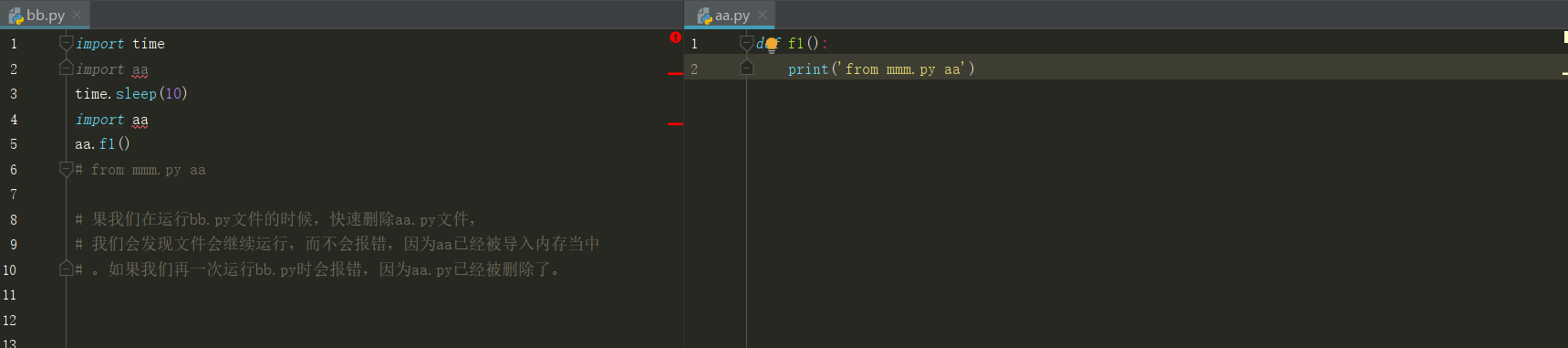 2 内置的模块
2 内置的模块

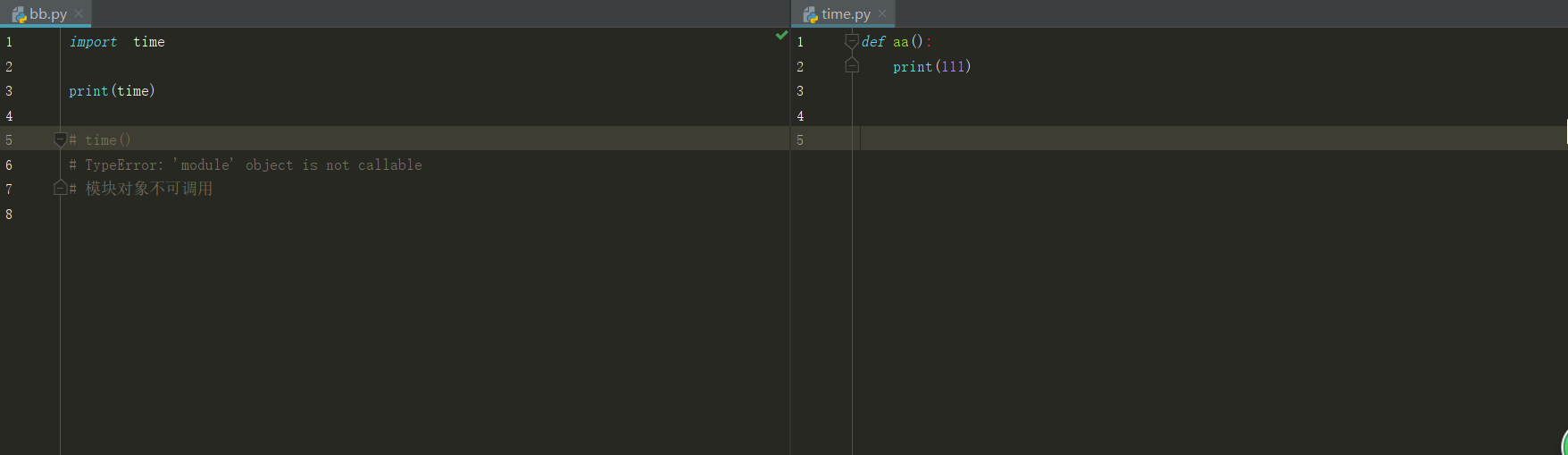
3 环境变量sys.path中找
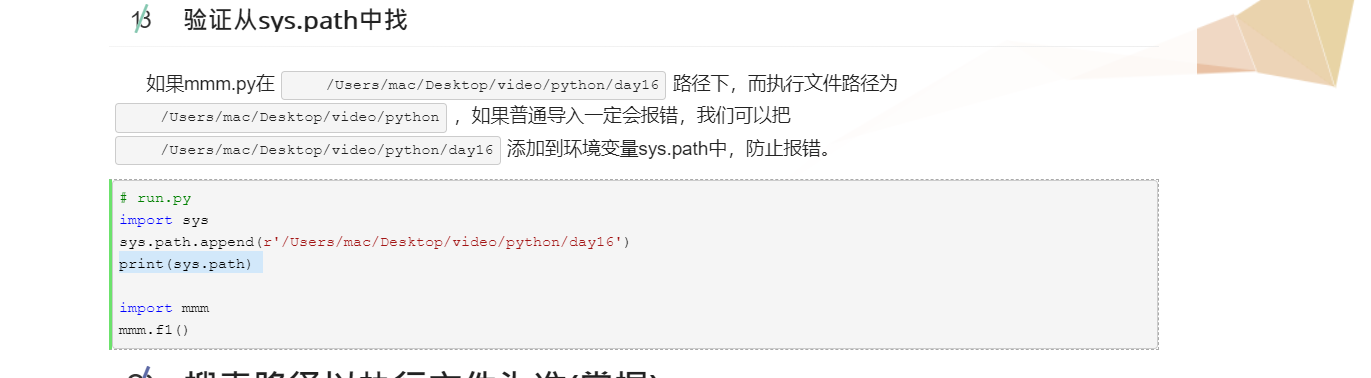
三 包
,第一是直接作为脚本执行,第二是import到其他的python脚本中被调用(模块重用)执行。
因此if __name__ == 'main': 的作用就是控制这两种情况执行代码的过程,在if __name__ == 'main':
下的代码只有在第一种情况下(即文件作为脚本直接执行)才会被执行,而import到其他脚本中是不会被执行的。
1. __name__=='__main__':
def aa(): print("111111") cc=10000 def lo(): print("222222222222222222222") print(__name__) # __main__ # 当我们执行这个模块的时候 __name__=='__main__' # 当我我们去执行其他模块 在其他模块中引用这个模块的时候 __name__=="模块名字" if __name__=='__main__': lo() aa() print(cc) # 222222222222222222222 # 111111 # 10000
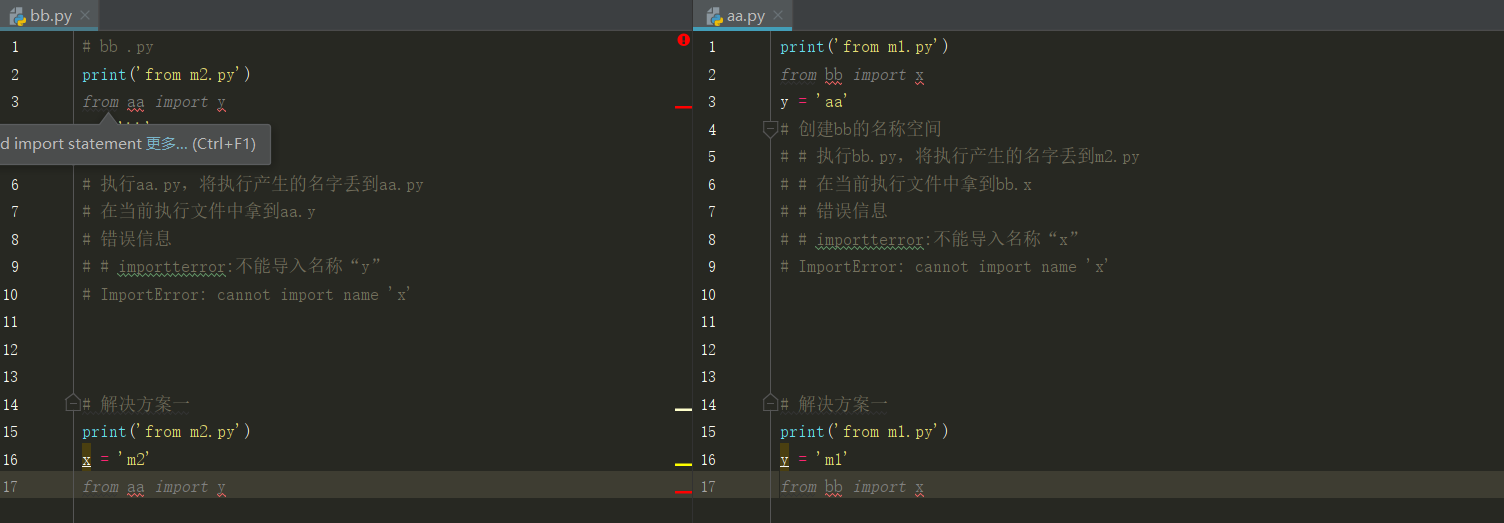
2. module from.....import ... from.....import *
这是module.py文件 # 一个.py就是一个模块 def sayGood(): print("my name is veary good") def sayNice(): print("my name is veary good") def sayHandsome(): print("my name is veary good") t1=1000000000000000
这是执行文件aa.py """ 方法一 import module # 自定义模块 后面不加.py后缀 # 注意 一个模块只会引入一次 不管你执行了 多次 import 防止模块多次引入 # 使用模块中的内容: # 格式: 模块名 函数名/变量 module.sayHandsome() # my name is veary good module.sayGood() # my name is veary good module.sayNice() # my name is veary good print(module.t1) # 1000000000000000 # 引用函数模块 sayHandsome() sayGood() sayNice() """
""" 方法二 from.......import*语句 # 作用:把一个模块中所有的内容导入 当前命名空间 # from module import *#最好不要过多使用 sayGood() """ # 方法三 # from.......import语句 # 作用:从模块中导入一个指定的部分到当前命名空间 # 格式: from module import name[,[name2]] # 意思从modul这个模块里导入那个功能模块 from module import sayGood ,sayNice,sayHandsome # 程序内容的函数可以将模块中的同名函数覆盖 # def sayGood(): # print("*********************") sayGood() # my name is veary good sayNice() # my name is veary good sayHandsome() #my name is veary good
3. __init__.py
思考: 如果不同的人编写的模块同名怎么办
解决: 为了解决模块命名的冲突 引入了按目录来组织模块的方法 这个模块称为包
特点: 引入了包以后 只要顶层的包不与其他人发生冲突 那么模块都不会与别人的发生冲突
Python中的包
包是一个分层次的文件目录结构,它定义了一个由模块及子包,和子包下的子包等组成的 Python 的应用环境。
简单来说,包就是文件夹,但该文件夹下必须存在 __init__.py 文件, 该文件的内容可以为空。__init__.py
用于标识当前文件夹是一个包。
考虑一个在 package_runoob 目录下的 runoob1.py
a目录下的aa.py
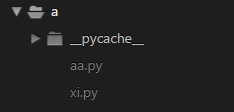
执行文件
# runoob2.py、__init__.py 文件,test.py 为测试调用包的代码,目录结构如下: import a.aa import a.xi a.aa.sayGood() # 333333333333333333333333333330000000 a.xi.bb() b.aa.aa() # 111111111111111111111111111111111111111
4. 相对路径包 这种不能在包里面使用 只能在外面使用
目录结构


api cmd db 目录下 文件
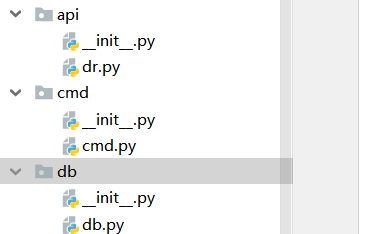



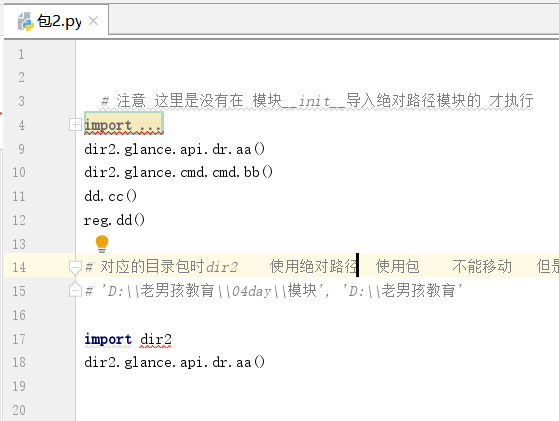
包1.py执行

5. 绝对路径包 优点可以随意移动包 对应的 dir2目录包
api api cmd db log 目录下 文件

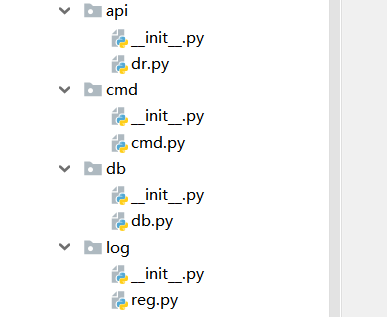




包2.py 执行文件