前言
Yara是一个能够帮助恶意软件研究人员识别和分类恶意软件样本的工具(类似正则表达式)。
规则可以通过文本或二进制的模式被创建,并且每个规则均由一组字符串和一个布尔表达式组成。


1 //示例规则 2 rule Test : Trojan 3 { 4 //规则描述 5 meta: 6 author = "Sunset" 7 date = "2020-04-08" 8 description = "Trojan Detection" 9 10 //规则字符串 11 strings: 12 $a = {6A 40 68 00 30 00 00 6A 14 8D 91} 13 $b = {8D 4D B0 2B C1 83 C0 27 99 6A 4E 59 F7 F9} 14 $c = "UVODFRYSIHLNWPEJXQZAKCBGMT" 15 16 //条件表达式 17 condition: 18 $a or $b or $c 19 }
编译下载
项目:https://github.com/virustotal/yara
releases:https://github.com/VirusTotal/yara/releases
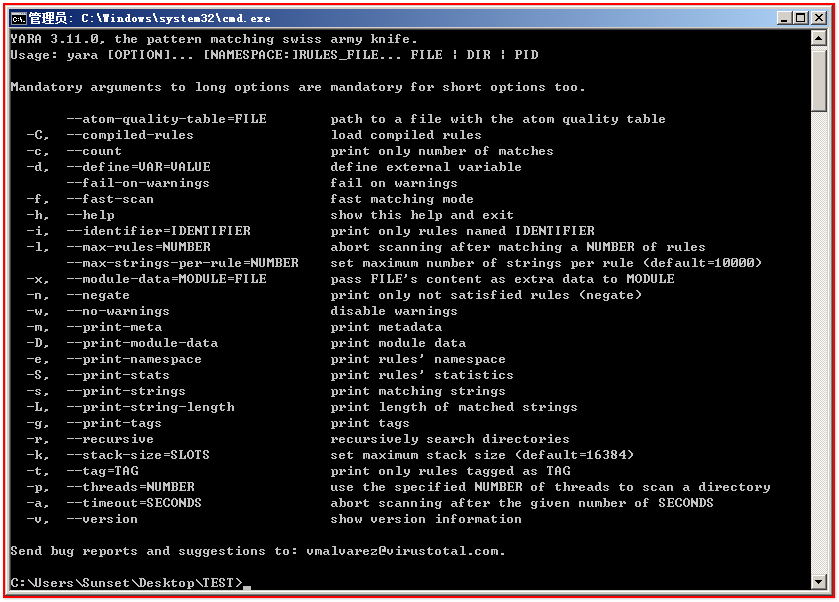
1 --atom - quality - table = FILE // 2 - C, --compiled - rules //加载编译规则 3 - c, --count // 只打印命中的规则数量 4 - d, --define = VAR = VALUE //定义外部变量 5 --fail - on - warnings //失败警告 6 - f, --fast - scan //快速匹配模式 7 - h, --help //显示帮助并退出 8 - i, --identifier = IDENTIFIER // 匹配指定名称的规则(使用指定名称的规则进行匹配) 9 - l, --max - rules = NUMBER //匹配多个规则后中止扫描 10 --max - strings - per - rule = NUMBER //设置每个规则的最大字符串数量(默认 = 10000) 11 - x, --module - data = MODULE = FILE //将文件内容作为额外数据传递给模块 12 - n, --negate // 只打印不匹配的规则 13 - w, --no - warnings //禁用警告 14 - m, --print - meta // 打印元数据(在命中结果中显示:规则元数据) 15 - D, --print - module - data // 打印模块数据(在命中结果中显示:规则名称与样本名称) 16 - e, --print - namespace //打印规则的名称空间 17 - S, --print - stats //打印规则的统计信息 18 - s, --print - strings // 打印匹配的字符串 19 - L, --print - string - length //打印匹配的字符串长度(字符串在文件中的偏移与长度) 20 - g, --print - tags // 打印标签(显示命中规则的标签) 21 - r, --recursive // 递归搜索目录(匹配该目录下的所有样本文件) 22 - k, --stack - size = SLOTS //设置最大堆栈大小(默认值为16384) 23 - t, --tag = TAG // 匹配指定标签的规则(使用指定规则标签进行匹配,标签区分大小写) 24 - p, --threads = NUMBER //指定多少线程数来扫描目录 25 - a, --timeout = SECONDS //指定多少秒后中止扫描 26 - v, --version //显示版本信息
规则编写
Yara规则语法类似于C语言,易于编写和理解,每个规则都以关键字“rule”开头,后面跟着一个规则标识符。
标识符必须遵循与C语言相同的词法约定,它们可以包含任何字母数字和下划线,但第一个字符不能是数字。
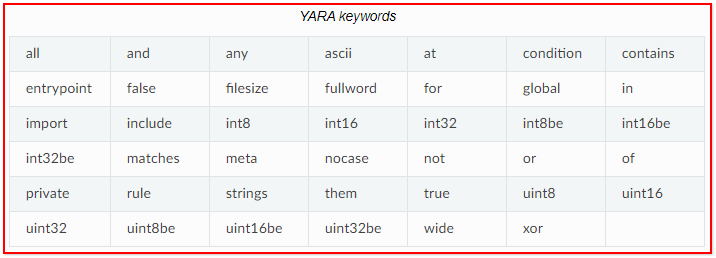
规则标识符区分大小写,并且不能超过128个字符。以下关键字是保留的,不能用作标识:
注释
你可以像编写C语言一样,在Yara规则中添加注释:
1 // 单行注释 2 3 /* 4 多行注释 5 */
字符串
Yara中有三种类型的字符串:
十六进制串:定义原始字节序列
1 //通配符:可以代替某些未知字节,与任何内容匹配 2 rule WildcardExample 3 { 4 strings: 5 //使用‘?’作为通配符 6 $hex_string = { 00 11 ?? 33 4? 55 } 7 8 condition: 9 $hex_string 10 } 11 12 //跳转:可以匹配长度可变的字符串 13 rule JumpExample 14 { 15 strings: 16 //使用‘[]’作为跳转,与任何长度为0-2字节的内容匹配 17 $hex_string1 = { 00 11 [2] 44 55 } 18 $hex_string2 = { 00 11 [0-2] 44 55 } 19 //该写法与string1作用完全相同 20 $hex_string3 = { 00 11 ?? ?? 44 55 } 21 22 condition: 23 $hex_string1 and $hex_string2 24 } 25 26 //也可以使用类似于正则表达式的语法 27 rule AlternativesExample1 28 { 29 strings: 30 $hex_string = { 00 11 ( 22 | 33 44 ) 55 } 31 /* 32 可以匹配以下内容: 33 00 11 22 55 34 00 11 33 44 55 35 */ 36 37 condition: 38 $hex_string 39 } 40 41 //还可以将上面介绍的方法整合在一起用 42 rule AlternativesExample2 43 { 44 strings: 45 $hex_string = { 00 11 ( 33 44 | 55 | 66 ?? 88 ) 99 } 46 47 condition: 48 $hex_string 49 }
文本字符串:定义可读文本的部分
1 //转义符: 2 \" 双引号 3 \\ 反斜杠 4 \t 制表符 5 \n 换行符 6 \xdd 十六进制的任何字节 7 8 //修饰符: 9 nocase: 不区分大小写 10 wide: 匹配2字节的宽字符 11 ascii: 匹配1字节的ascii字符 12 xor: 匹配异或后的字符串 13 fullword:匹配完整单词 14 private: 定义私有字符串 15 16 rule CaseInsensitiveTextExample 17 { 18 strings: 19 //不区分大小写 20 $text_string = "foobar" nocase 21 //匹配宽字符串 22 $wide_string = "Borland" wide 23 //同时匹配2种类型的字符串 24 $wide_and_ascii_string = "Borland" wide ascii 25 //匹配所有可能的异或后字符串 26 $xor_string = "This program cannot" xor 27 //匹配所有可能的异或后wide ascii字符串 28 $xor_string = "This program cannot" xor wide ascii 29 //限定异或范围 30 $xor_string = "This program cannot" xor(0x01-0xff) 31 //全词匹配(匹配:www.domain.com 匹配:www.my-domain.com 不匹配:www.mydomain.com) 32 $wide_string = "domain" fullword 33 //私有字符串可以正常匹配规则,但是永远不会在输出中显示 34 $text_string = "foobar" private 35 36 condition: 37 $text_string 38 }
正则表达式:定义可读文本的部分
条件表达式
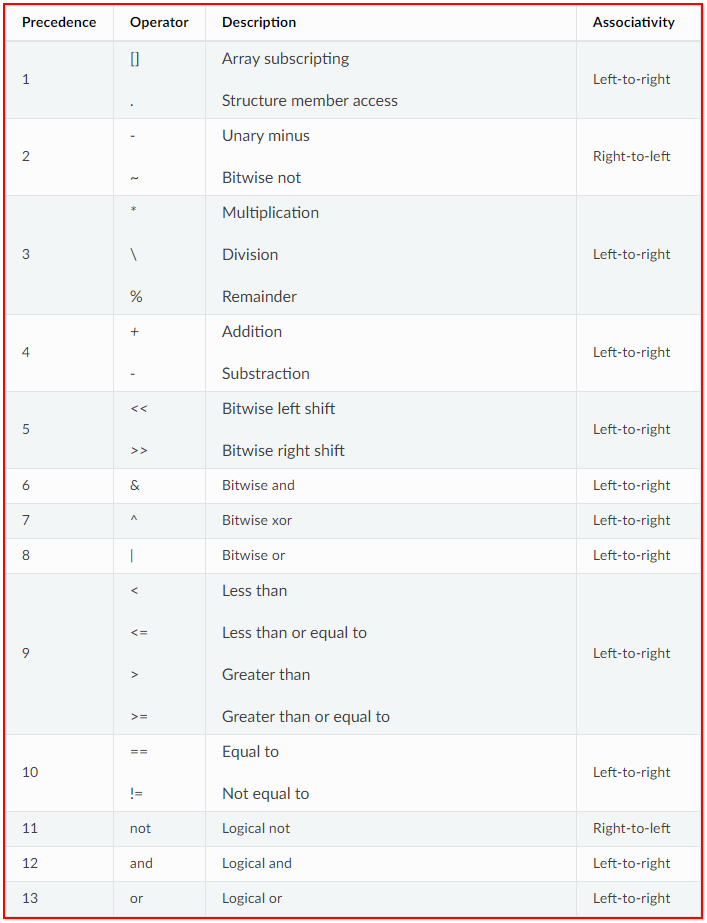
你可以在条件表达中使用如下运算符:
all any them
1 all of them // 匹配规则中的所有字符串 2 any of them // 匹配规则中的任意字符串 3 all of ($a*) // 匹配标识符以$a开头的所有字符串 4 any of ($a,$b,$c) // 匹配a, b,c中的任意一个字符串 5 1 of ($*) // 匹配规则中的任意一个字符串
#
1 //===匹配字符串在文件或内存中出现的次数 2 rule CountExample 3 { 4 strings: 5 $a = "dummy1" 6 $b = "dummy2" 7 8 condition: 9 //a字符串出现6次,b字符串大于10次 10 #a == 6 and #b > 10 11 }
@
1 //可以使用@a[i],获取字符串$a在文件或内存中,第i次出现的偏移或虚拟地址 2 //小标索引从1开始,并非0 3 //如果i大于字符串出现的次数,结果为NaN(not a number 非数值)
!
1 //可以使用!a[i],获取字符串$a在文件或内存中,第i次出现时的字符串长度 2 //下标索引同@一样都是从1开始 3 //!a 是 !a[1]的简写
at
1 //===匹配字符串在文件或内存中的偏移 2 rule AtExample 3 { 4 strings: 5 $a = "dummy1" 6 $b = "dummy2" 7 8 condition: 9 //a和b字符串出现在文件或内存的100和200偏移处 10 $a at 100 and $b at 200 11 }
in
1 //===在文件或内存的某个地址范围内匹配字符串 2 rule InExample 3 { 4 strings: 5 $a = "dummy1" 6 $b = "dummy2" 7 8 condition: 9 $a in (0..100) and $b in (100..filesize) 10 }
filesize
1 //===使用关键字匹配文件大小 2 rule FileSizeExample 3 { 4 condition: 5 //filesize只在文件时才有用,对进程无效 6 //KB MB后缀只能与十进制大小一起使用 7 filesize > 200KB 8 }
entrypoint
1 //===匹配PE或ELF文件入口点(高版本请使用PE模块的pe.entry_point代替) 2 rule EntryPointExample1 3 { 4 strings: 5 $a = { E8 00 00 00 00 } 6 7 condition: 8 $a at entrypoint 9 } 10 11 rule EntryPointExample2 12 { 13 strings: 14 $a = { 9C 50 66 A1 ?? ?? ?? 00 66 A9 ?? ?? 58 0F 85 } 15 16 condition: 17 $a in (entrypoint..entrypoint + 10) 18 }
intxxx uintxxx
1 //===从指定的文件或内存偏移处读取数据 2 //小端: 有符号整数 3 int8(<offset or virtual address>) 4 int16(<offset or virtual address>) 5 int32(<offset or virtual address>) 6 7 //小端: 无符号整数 8 uint8(<offset or virtual address>) 9 uint16(<offset or virtual address>) 10 uint32(<offset or virtual address>)
intxxxbe uintXXXbe
1 //大端: 有符号整数 2 int8be(<offset or virtual address>) 3 int16be(<offset or virtual address>) 4 int32be(<offset or virtual address>) 5 6 //大端: 无符号整数 7 uint8be(<offset or virtual address>) 8 uint16be(<offset or virtual address>) 9 uint32be(<offset or virtual address>) 10 11 //应用示例 12 rule IsPE 13 { 14 condition: 15 //判断是否PE文件 16 uint16(0) == 0x5A4D and 17 uint32(uint32(0x3C)) == 0x00004550 18 }
of
1 //===匹配多个字符串中的某几个 2 rule OfExample1 3 { 4 strings: 5 $a = "dummy1" 6 $b = "dummy2" 7 $c = "dummy3" 8 9 condition: 10 //3个字符串只需匹配任意2个 11 2 of ($a,$b,$c) 12 }
for xxx of xxx :(xxx)
1 //功能: 2 对多个字符串匹配相同的条件 3 //格式: 4 for AAA of BBB : ( CCC ) 5 //含义: 6 在BBB字符串集合中,至少有AAA个字符串,满足了CCC的条件表达式,才算匹配成功。 7 在CCC条件表达式中,可以使用'$'依次代替BBB字符串集合中的每一个字符串。 8 9 //for..of其实就是of的特别版,所以下面2个例子作用相同 10 any of ($a,$b,$c) 11 for any of ($a,$b,$c) : ( $ ) 12 13 //在abc3个字符串集合中,至少有1个字符串,必须满足字符串内容与entrypoint相同的条件 14 for 1 of ($a,$b,$c) : ( $ at entrypoint ) 15 for any of ($a,$b,$c) : ( $ at entrypoint ) 16 17 //所有字符串,在文件或内存中出现的次数必须大于3,才算匹配成功。 18 for all of them : ( # > 3 ) 19 20 //所有以$a开头的字符串,在文件或内存中第2次出现的位置必须小于9 21 for all of ($a*) : (@[2] < 0x9)
for xxx i in (xxx) :(xxx)
1 //格式: 2 for AAA BBB in (CCC) : (DDD) 3 //含义: 4 作用与for of类似,只是增加了下标变量与下标范围,具体看示例 5 6 //$b在文件或内存中出现的前3次偏移,必须与$a在文件或内存中出现的前3次偏移+10相同 7 for all i in (1,2,3) : ( @a[i] + 10 == @b[i] ) 8 for all i in (1..3) : ( @a[i] + 10 == @b[i] ) 9 10 //$a每次在文件或内存中出现位置,都必须都小于100 11 for all i in (1..#a) : ( @a[i] < 100 ) 12 13 //其它示例 14 for any i in (1..#a) : ( @a[i] < 100 ) 15 for 2 i in (1..#a) : ( @a[i] < 100 )
引用其它规则
1 rule Rule1 2 { 3 strings: 4 $a = "dummy1" 5 6 condition: 7 $a 8 } 9 10 rule Rule2 11 { 12 strings: 13 $a = "dummy2" 14 15 condition: 16 $a and Rule1 17 }
全局规则
1 //全局规则(global rule)可以在匹配其他规则前优先筛选, 2 //比如在匹配目标文件之前需要先筛选出小于2MB的文件,在匹配其他规则 3 global rule SizeLimit 4 { 5 condition: 6 filesize < 2MB 7 }
私有规则
1 //私有规则(private rule)可以避免规则匹配结果的混乱, 2 //比如使用私有规则进行匹配时,YARA不会输出任何匹配到的私有规则信息 3 //私有规则单独使用意义不大,一般可以配合"引用其它规则"的功能一起使用 4 //私有规则也可以和全局规则一起使用,只要添加“Private”、“global”关键字即可 5 private rule PrivateRuleExample 6 { 7 ... 8 }
规则标签
1 //规则标签,可以让你在YARA输出的时候只显示你感兴趣的规则,而过滤掉其它规则的输出信息 2 //你可以为规则添加多个标签 3 rule TagsExample1 : Foo Bar Baz 4 { 5 ... 6 } 7 8 rule TagsExample2 : Bar 9 { 10 ... 11 }
导入模块
1 //使用“import”导入模块 2 //你可以自己编写模块,也可以使用官方或其它第三方模块 3 //导入模块后,就可以开始使用模块导出的变量或函数 4 import "pe" 5 import "cuckoo" 6 7 pe.entry_point == 0x1000 8 cuckoo.http_request(/someregexp/)
外部变量
1 //外部变量允许你在使用YARA -d命令时指定一个自定义数据, 2 //该数据可以是整数、字符串、布尔变量,具体看以下示例 3 4 //使用布尔变量和一个整数变量作为判断条件 5 rule ExternalVariableExample2 6 { 7 condition: 8 bool_ext_var or filesize < int_ext_var 9 } 10 11 //字符串变量可以与以下运算符一起使用: 12 contains:如果字符串包含指定的子字符串,返回True 13 matches: 如果字符串匹配给定的正则表达式时,返回True 14 15 rule ExternalVariableExample3 16 { 17 condition: 18 string_ext_var contains "text" 19 } 20 21 rule ExternalVariableExample4 22 { 23 condition: 24 string_ext_var matches /[a-z]+/ 25 }
文件包含
1 //作用于C语言一样,可以包含其它规则到当前文件中 2 include "other.yar" 3 4 //相对路径 5 include "./includes/other.yar" 6 include "../includes/other.yar" 7 8 //全路径 9 include "/home/plusvic/yara/includes/other.yar"
参考资料
https://github.com/virustotal/yara
https://github.com/Yara-Rules/rules
https://yara.readthedocs.io/en/stable/
https://github.com/InQuest/awesome-yara
https://bbs.pediy.com/thread-226011.htm