github代码链接:github地址
1. spark集群及版本信息
服务器版本:centos7
hadoop版本:2.8.3
spark版本:2.3.3
使用springboot构建rest api远程提交spark任务,将数据库中的表数据存储到hdfs上,任务单独起一个项目,解除与springboot项目的耦合
2. 构建springboot项目
1. pom配置
<properties>
<java.version>1.8</java.version>
<spark.version>2.3.3</spark.version>
<scala.version>2.11</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.46</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-launcher_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.49</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<finalName>spark</finalName>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<mainClass>com.hrong.springbootspark.SpringbootSparkApplication</mainClass>
</configuration>
<executions>
<execution>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
2. 项目结构

3. 编写代码
1. 创建spark任务实体
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.beans.factory.annotation.Value;
import java.util.Map;
/**
* @Author hrong
**/
@Data
@NoArgsConstructor
@AllArgsConstructor
public class SparkApplicationParam {
/**
* 任务的主类
*/
private String mainClass;
/**
* jar包路径
*/
private String jarPath;
@Value("${spark.master:yarn}")
private String master;
@Value("${spark.deploy.mode:cluster}")
private String deployMode;
@Value("${spark.driver.memory:1g}")
private String driverMemory;
@Value("${spark.executor.memory:1g}")
private String executorMemory;
@Value("${spark.executor.cores:1}")
private String executorCores;
/**
* 其他配置:传递给spark job的参数
*/
private Map<String, String> otherConfParams;
/**
* 调用该方法可获取spark任务的设置参数
* @return SparkApplicationParam
*/
public SparkApplicationParam getSparkApplicationParam(){
return new SparkApplicationParam(mainClass, jarPath, master, deployMode, driverMemory, executorMemory, executorCores, otherConfParams);
}
}
2. 任务参数对象
每个任务执行的时候都必须指定运行参数,所以要继承SparkApplicationParam对象
import com.hrong.springbootspark.entity.SparkApplicationParam;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @Author hrong
**/
@Data
@NoArgsConstructor
@AllArgsConstructor
public class DataBaseExtractorVo extends SparkApplicationParam {
/**
* 数据库连接地址
*/
private String url;
/**
* 数据库连接账号
*/
private String userName;
/**
* 数据库密码
*/
private String password;
/**
* 指定的表名
*/
private String table;
/**
* 目标文件类型
*/
private String targetFileType;
/**
* 目标文件保存路径
*/
private String targetFilePath;
}
3. 定义spark提交方法
1. 定义interface
每个spark任务运行时都需要指定运行参数,但是任务内部所需的参数不一样,所以第一个参数为通用的参数对象,第二个参数为可变参数,根据不同的任务来进行传值
import com.hrong.springbootspark.entity.SparkApplicationParam;
import java.io.IOException;
/**
* @Author hrong
* @description spark任务提交service
**/
public interface ISparkSubmitService {
/**
* 提交spark任务入口
* @param sparkAppParams spark任务运行所需参数
* @param otherParams 单独的job所需参数
* @return 结果
* @throws IOException io
* @throws InterruptedException 线程等待中断异常
*/
String submitApplication(SparkApplicationParam sparkAppParams, String... otherParams) throws IOException, InterruptedException;
}
2. 具体实现
import com.alibaba.fastjson.JSONObject;
import com.hrong.springbootspark.entity.SparkApplicationParam;
import com.hrong.springbootspark.service.ISparkSubmitService;
import com.hrong.springbootspark.util.HttpUtil;
import org.apache.spark.launcher.SparkAppHandle;
import org.apache.spark.launcher.SparkLauncher;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.Map;
import java.util.concurrent.CountDownLatch;
/**
* @Author hrong
**/
@Service
public class SparkSubmitServiceImpl implements ISparkSubmitService {
private static Logger log = LoggerFactory.getLogger(SparkSubmitServiceImpl.class);
@Value("${driver.name:n151}")
private String driverName;
@Override
public String submitApplication(SparkApplicationParam sparkAppParams, String... otherParams) throws IOException, InterruptedException {
log.info("spark任务传入参数:{}", sparkAppParams.toString());
CountDownLatch countDownLatch = new CountDownLatch(1);
Map<String, String> confParams = sparkAppParams.getOtherConfParams();
SparkLauncher launcher = new SparkLauncher()
.setAppResource(sparkAppParams.getJarPath())
.setMainClass(sparkAppParams.getMainClass())
.setMaster(sparkAppParams.getMaster())
.setDeployMode(sparkAppParams.getDeployMode())
.setConf("spark.driver.memory", sparkAppParams.getDriverMemory())
.setConf("spark.executor.memory", sparkAppParams.getExecutorMemory())
.setConf("spark.executor.cores", sparkAppParams.getExecutorCores());
if (confParams != null && confParams.size() != 0) {
log.info("开始设置spark job运行参数:{}", JSONObject.toJSONString(confParams));
for (Map.Entry<String, String> conf : confParams.entrySet()) {
log.info("{}:{}", conf.getKey(), conf.getValue());
launcher.setConf(conf.getKey(), conf.getValue());
}
}
if (otherParams.length != 0) {
log.info("开始设置spark job参数:{}", otherParams);
launcher.addAppArgs(otherParams);
}
log.info("参数设置完成,开始提交spark任务");
SparkAppHandle handle = launcher.setVerbose(true).startApplication(new SparkAppHandle.Listener() {
@Override
public void stateChanged(SparkAppHandle sparkAppHandle) {
if (sparkAppHandle.getState().isFinal()) {
countDownLatch.countDown();
}
log.info("stateChanged:{}", sparkAppHandle.getState().toString());
}
@Override
public void infoChanged(SparkAppHandle sparkAppHandle) {
log.info("infoChanged:{}", sparkAppHandle.getState().toString());
}
});
log.info("The task is executing, please wait ....");
//线程等待任务结束
countDownLatch.await();
log.info("The task is finished!");
//通过Spark原生的监测api获取执行结果信息,需要在spark-default.xml、spark-env.sh、yarn-site.xml进行相应的配置
String estUrl = "http://"+driverName+":18080/api/v1/applications/" + handle.getAppId();
return HttpUtil.httpGet(restUrl, null);
}
}
4. Controller写法
controller主要的职责就是接受页面的参数,将参数传递到service层
import com.hrong.springbootspark.service.ISparkSubmitService;
import com.hrong.springbootspark.vo.DataBaseExtractorVo;
import com.hrong.springbootspark.vo.Result;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.ResponseBody;
import javax.annotation.Resource;
import java.io.IOException;
/**
* @Author hrong
**/
@Slf4j
@Controller
public class SparkController {
@Resource
private ISparkSubmitService iSparkSubmitService;
/**
* 调用service进行远程提交spark任务
* @param vo 页面参数
* @return 执行结果
*/
@ResponseBody
@PostMapping("/extract/database")
public Object dbExtractAndLoad2Hdfs(@RequestBody DataBaseExtractorVo vo){
try {
return iSparkSubmitService.submitApplication(vo.getSparkApplicationParam(),
vo.getUrl(),
vo.getTable(),
vo.getUserName(),
vo.getPassword(),
vo.getTargetFileType(),
vo.getTargetFilePath());
} catch (IOException | InterruptedException e) {
e.printStackTrace();
log.error("执行出错:{}", e.getMessage());
return Result.err(500, e.getMessage());
}
}
}
3. 构建Spark任务项目(Maven项目)
1. pom配置
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
<hadoop.version>2.8.3</hadoop.version>
<spark.version>2.3.3</spark.version>
<scala.version>2.11</scala.version>
<scala-library.version>2.11.8</scala-library.version>
<mysql.version>5.1.46</mysql.version>
<oracle.version>11g</oracle.version>
<codehaus.version>3.0.10</codehaus.version>
</properties>
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<!-- 下载好了jar包install到本地的,无法使用maven下载 -->
<dependency>
<groupId>com.oracle.driver</groupId>
<artifactId>jdbc-driver</artifactId>
<version>${oracle.version}</version>
</dependency>
<!--spark相关开始-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.codehaus.janino</groupId>
<artifactId>commons-compiler</artifactId>
<version>${codehaus.version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala-library.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<finalName>spark-job</finalName>
<pluginManagement>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
</plugin>
</plugins>
</pluginManagement>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>scala-test-compile</id>
<phase>process-test-resources</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<executions>
<execution>
<phase>compile</phase>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
2. 项目结构
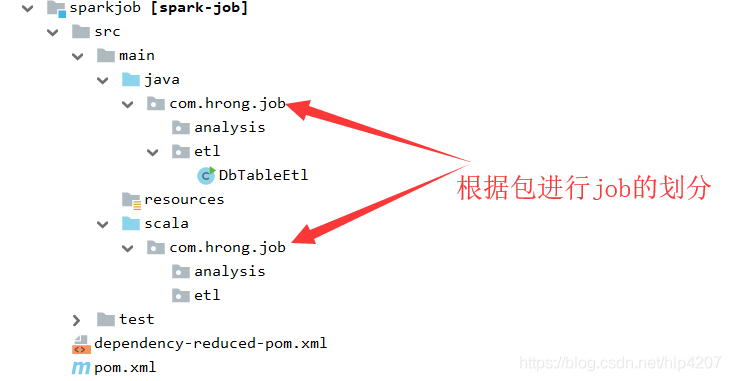
3. spark job代码
获取外部参数,连接数据库,并将指定表中的数据根据指定的格式、目录转存到hdfs上
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* @Author hrong
* @Description 将数据库中的表数据保存到hdfs上
**/
public class DbTableEtl {
private static Logger log = LoggerFactory.getLogger(DbTableEtl.class);
public static void main(String[] args) {
SparkSession spark = SparkSession.builder()
.appName(DbTableEtl.class.getSimpleName())
.getOrCreate();
String url = args[0];
String dbtable = args[1];
String user = args[2];
String password = args[3];
String targetFileType = args[4];
String targetFilePath = args[5];
Dataset<Row> dbData = spark.read()
.format("jdbc")
.option("url", url)
.option("dbtable", dbtable)
.option("user", user)
.option("password", password)
.load();
log.info("展示部分样例数据,即将开始导入到hdfs");
dbData.show(20, false);
dbData.write().mode("overwrite").format(targetFileType).save(targetFilePath);
}
}
3. 项目打包
直接使用IDEA自带打包功能
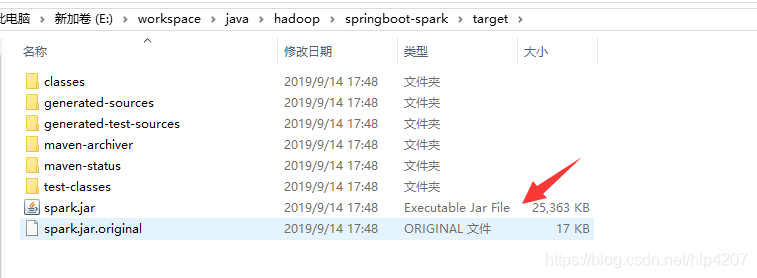
1. springboot项目
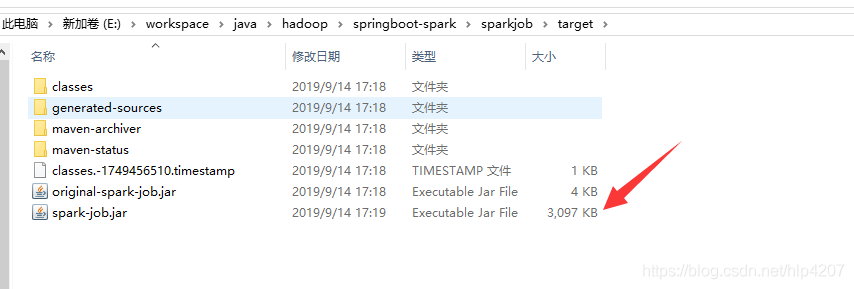
2. Spark job项目
4. 上传至服务器

5. 将spark-job上传至hdfs

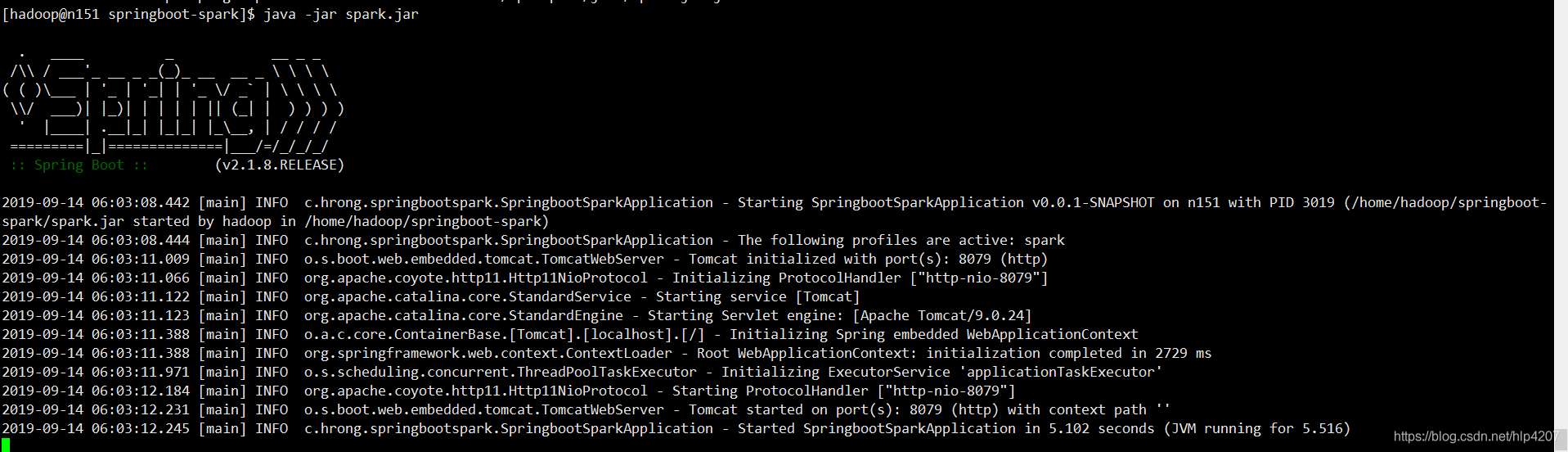
6. 启动springboot项目
7. 使用postman调用接口
指定jarPath、mainClass、deployMode以及任务所需参数
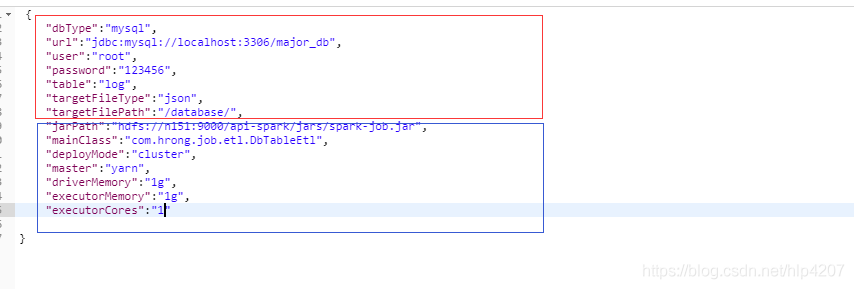
8. 调用结果
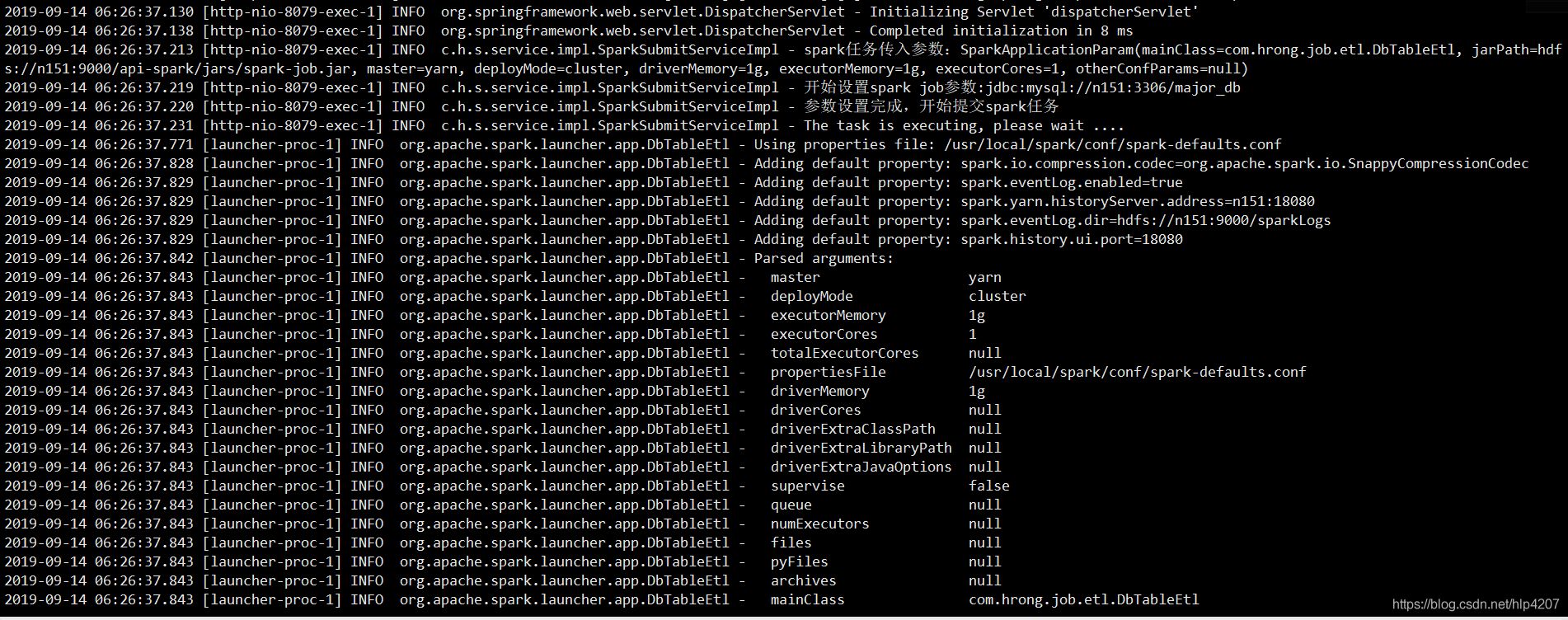
程序开始提交任务
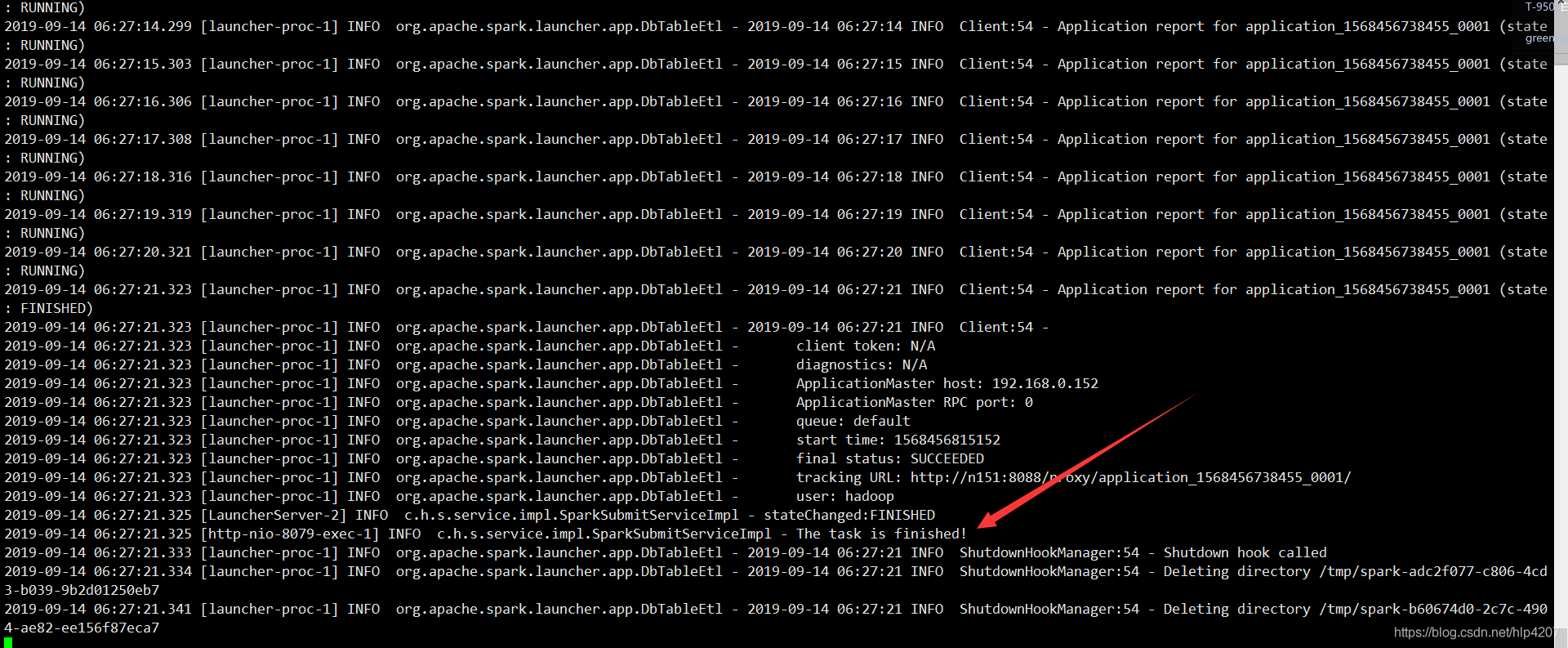
程序执行结束
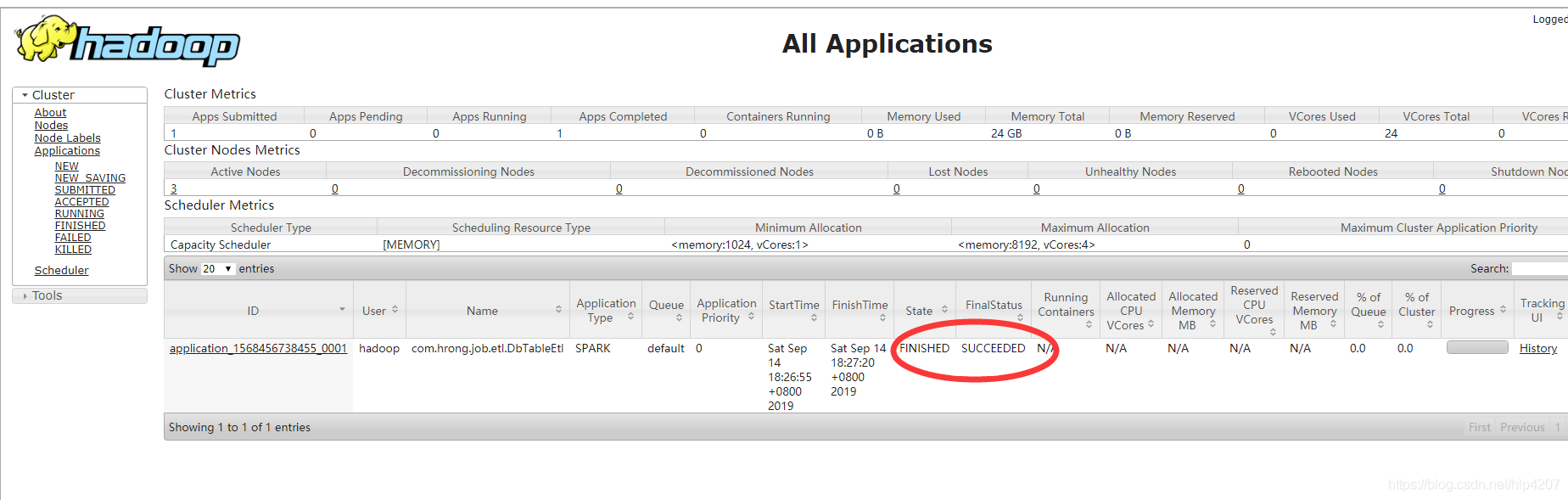
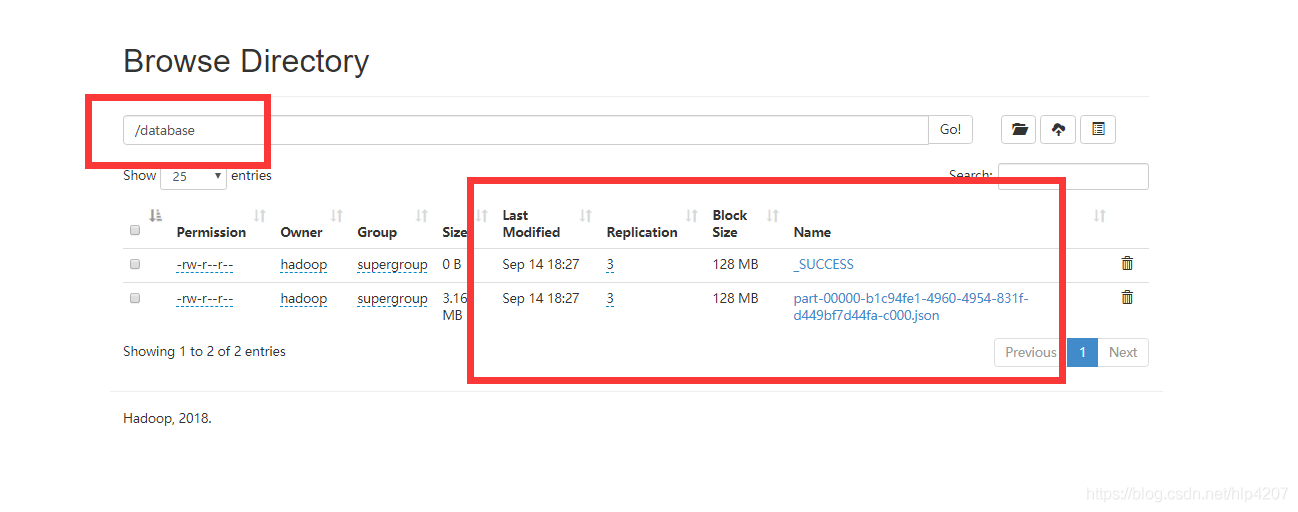
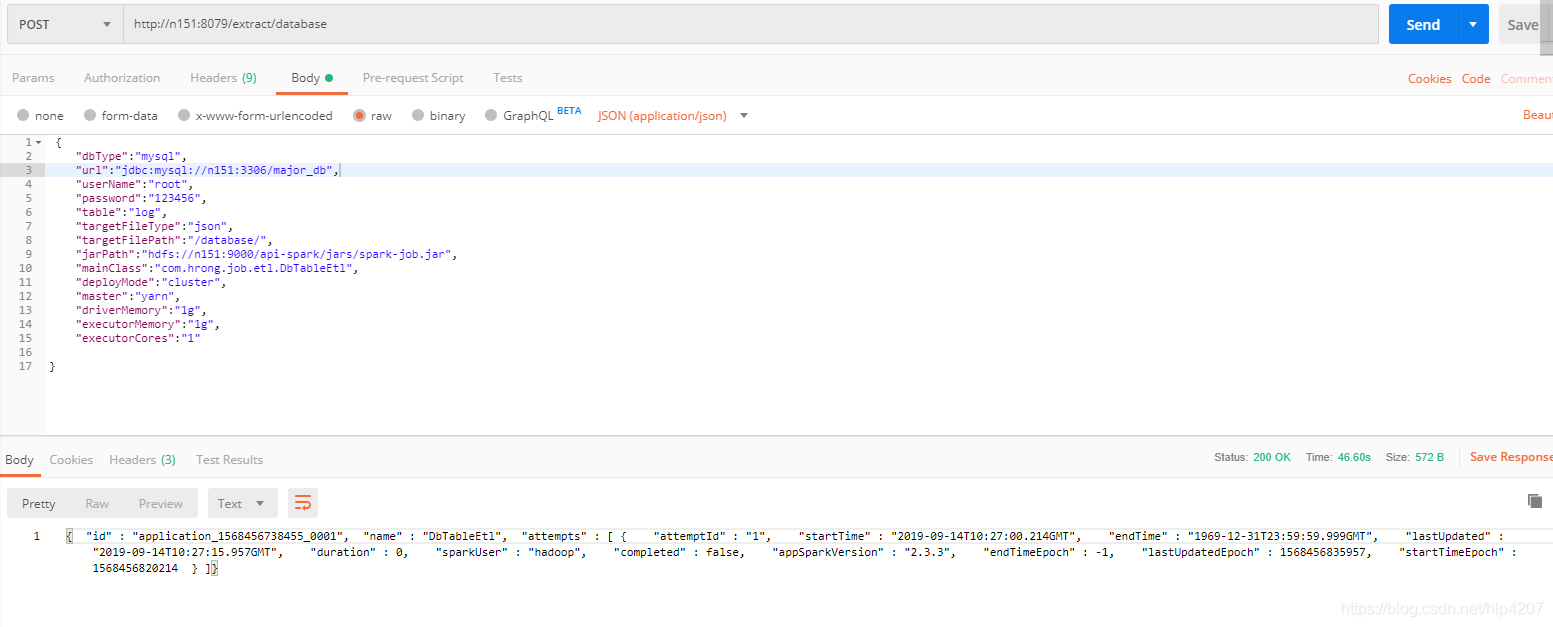
代码放在了github上面,链接:github地址
————————————————
版权声明:本文为CSDN博主「hlp4207」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/hlp4207/article/details/100831384