问题:
假设在test.xlsx的“Sheet1”工作表中,A1:D3区域的值如下:

要求给定指定的行、列以及对应的工作表作为参数,能够正确解析合并单元格,获取指定单元格的值。
如果直接根据行列获取对应单元格的值,则合并单元格非左上角的其他单元格都会获取到None值,如下:
if __name__ == "__main__": wb = xl.load_workbook("test.xlsx") sheet_ = wb["Sheet1"] print(sheet_["A1"].value) # 1 print(sheet_["A2"].value) # None print(sheet_["D1"].value) # 8 print(sheet_["D2"].value) # None print(sheet_["D3"].value) # None
解决思路:
获取到对应单元格后,判断该单元格是否为合并单元格,如果是,则找到该合并区域并获取左上角的值返回。
通过 sheet.merged_cell_ranges属性,可以获取当前工作表所有的合并区域列表:
测试代码:
if __name__ == "__main__": wb = xl.load_workbook("test.xlsx") sheet_ = wb["Sheet1"] merged_ranges = sheet_.merged_cell_ranges # 获取当前工作表的所有合并区域列表 for merged_range in merged_ranges: print(type(merged_range)) # 打印区域对象类型 print(merged_range) # 打印区域
结果如下:
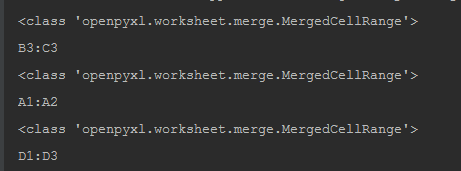
我们巡着openpyxl.worksheet.merge.MergedCellRange查找其源码,发现定义了in操作,可以直接通过in确认某个坐标是否位于区域内

这时候我们已经基本具备获取合并单元格的条件了。
完整代码如下:
import openpyxl as xl from openpyxl.worksheet.worksheet import Worksheet from openpyxl.cell import MergedCell def parser_merged_cell(sheet: Worksheet, row, col): """ 检查是否为合并单元格并获取对应行列单元格的值。 如果是合并单元格,则取合并区域左上角单元格的值作为当前单元格的值,否则直接返回该单元格的值 :param sheet: 当前工作表对象 :param row: 需要获取的单元格所在行 :param col: 需要获取的单元格所在列 :return: """ cell = sheet.cell(row=row, column=col) if isinstance(cell, MergedCell): # 判断该单元格是否为合并单元格 for merged_range in sheet.merged_cell_ranges: # 循环查找该单元格所属的合并区域 if cell.coordinate in merged_range: # 获取合并区域左上角的单元格作为该单元格的值返回 cell = sheet.cell(row=merged_range.min_row, column=merged_range.min_col) break return cell if __name__ == "__main__": wb = xl.load_workbook("test.xlsx") sheet_ = wb["Sheet1"] for row_index in range(1, 4): for col_index in range(1, 5): cell_ = parser_merged_cell(sheet_, row_index, col_index) print("第%s行第%s列:%s" % (row_index, col_index, cell_.value))
结果如下:
第1行第1列:1 第1行第2列:2 第1行第3列:3 第1行第4列:8 第2行第1列:1 第2行第2列:4 第2行第3列:5 第2行第4列:8 第3行第1列:6 第3行第2列:7 第3行第3列:7 第3行第4列:8