上一篇简单的介绍Beautiful Soup 的基本用法,这一篇写下如何爬取网站上的图片,并保存下来
爬取图片
1.找到一个福利网站:http://www.xiaohuar.com/list-1-1.html
2.通过F12进行定位图片
3.通过下图可以看到标签为img,然后通过width="210"的属性
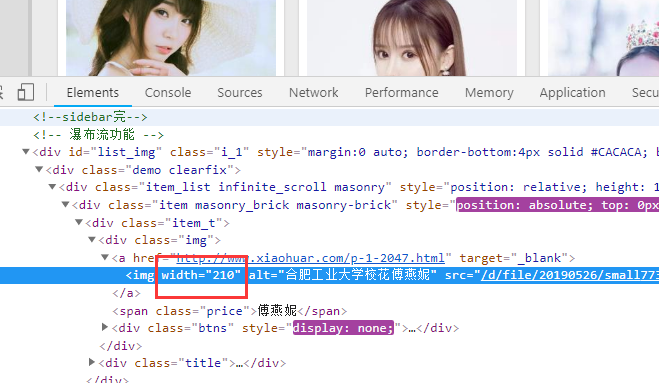
爬取方法
1.通过find_all()的方法进行查找图片位置
2.筛选出图片的URL和图片名称
3.筛选后会发现其中有一些图片URL不完整
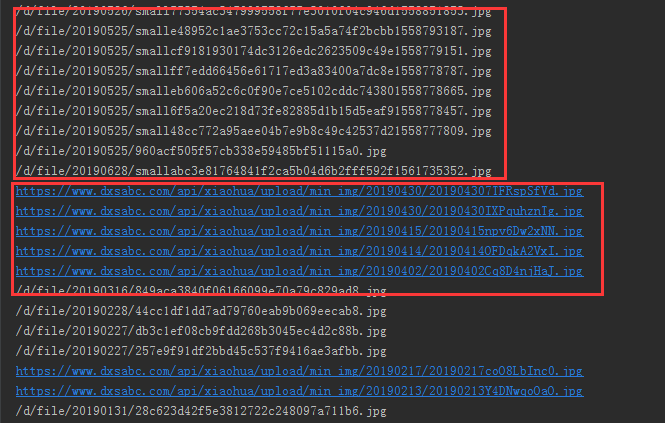
4.这个时候需要在代码中加一个判断,如何URL不完整 我们就给他补充完整
import requests from bs4 import BeautifulSoup import os # 请求地址 url = 'http://www.xiaohuar.com/list-1-1.html' html = requests.get(url).content # BeautifulSoup 实例化 soup = BeautifulSoup(html,'html.parser') jpg_data = soup.find_all('img',width="210") for i in jpg_data: data = i['src'] name = i['alt'] # 判断URL是否完整 if "https://www.dxsabc.com/" not in data: data = 'http://www.xiaohuar.com'+ data
保存图片
1.判断一个文件夹是否存在,不存在就重新创建
2.request模块请求图片的URL
3.通过content返回图片二进制,进行写入文件夹中
# coding:utf-8 import requests from bs4 import BeautifulSoup import os # 创建一个文件夹名称 FileName = 'tupian' if not os.path.exists(os.path.join(os.getcwd(), FileName)): # 新建文件夹 print(u'建了一个名字叫做', FileName, u'的文件夹!') os.mkdir(os.path.join(os.getcwd(),'tupian')) else: print(u'名字叫做', FileName, u'的文件夹已经存在了!') url = 'http://www.xiaohuar.com/list-1-1.html' html = requests.get(url).content # 返回html soup = BeautifulSoup(html,'html.parser') # BeautifulSoup对象 jpg_data = soup.find_all('img',width="210") # 找到图片信息 for i in jpg_data: data = i['src'] # 图片的URL name = i['alt'] # 图片的名称 if "https://www.dxsabc.com/" not in data: data = 'http://www.xiaohuar.com'+data r2 = requests.get(data) fpath = os.path.join(FileName,name) with open(fpath+'.jpg','wb+')as f : # 循环写入图片 f.write(r2.content) print('保存成功,快去查看图片吧!!')
图片就不贴了,喜欢的可以自己动手写一写。