运算符
1、算术运算符
% 取余运算符,返回余数
** 幂运算符
//返回商的整数部分
2、逻辑运算符
and 与运算符 a and b 如果a为False是,表达式为False,如果a为True返回b的布尔值
or 或运算符 a or b ,如果a为True时,表达式为True,如果a为False则返回b的布尔值
not 非运算符,返回当前布尔值的相反值,如果a为False则返回True
逻辑运算符 顺序 not > and >or 真是坑啊
1 ''' 2 逻辑运算符 3 and 同真则真 4 or 同假则假 5 not 取反 6 ''' 7 name = "sunqi" 8 age = 19 9 10 ''' 11 1、判断name == "sunqi"——》True继续进行判断 12 2、判断age == 19 ——》True继续进行判断 13 3、判断name == "sunq"——》False然后接下来是or操作 14 4、判断age==18——》False前后都为False则返回布尔值False 15 ''' 16 a = (name =="sunqi" and age ==19 and name == 'sunq' or age ==18) 17 print(a)
基本数据类型
一、字符串(str)
#定义:在单引号双引号三引号内,由一串字符组成 name='sunqi' #1、按索引取值(正向取+反向取) :只能取 #2、切片(顾头不顾尾,步长) #3、长度len #4、成员运算in和not in #5、移除空白strip #6、切分split #7、循环
基本方法
#1、strip,lstrip,rstrip #2、lower,upper #3、startswith,endswith #4、format的三种方法 #5、split,rsplit #6、join #7、replace #8、isdigit
举个栗子
#strip name='*sunqi**' print(name.strip('*'))#“sunqi” print(name.lstrip('*'))#“sunqi**” print(name.rstrip('*'))#“*sunqi” #lower,upper name='sunqi' print(name.lower())#转换为小写 print(name.upper())#转换为大写 #startswith,endswith name='sunqi_good' print(name.endswith('good'))#以xxx结尾 print(name.startswith('sunqi'))#以xxx开头 #format的三种方法 res='{} {} {}'.format('sunqi',18,'male') res='{0} {1} {2}'.format('sunqi',18,'male') res='{name} {age} {sex}'.format(sex='male',name='sunqi',age=18) #split name='root:x:0:0::/root:/bin/bash' print(name.split(':')) #默认分隔符为空格 name='C:/a/b/c/d.txt' #只想拿到顶级目录 print(name.split('/',1)) name='a|b|c' print(name.rsplit('|',1)) #从右开始切分,没有从左侧开始的方法 #join tag=' ' print(tag.join(['sunqi','say','hello','world'])) #可迭代对象必须都是字符串 #replace name='sunqi say :i have one computer,my name is sunqi' print(name.replace('sunqi','tony',1)) #isdigit:可以判断bytes和unicode类型,是最常用的用于于判断字符是否为"数字"的方法 age=input('>>: ') print(age.isdigit())#判断是否只包含十进制数字,有小数点也不行 #is数字系列 #在python3中 num1=b'4' #bytes num2=u'4' #unicode,python3中无需加u就是unicode num3='四' #中文数字 num4='Ⅳ' #罗马数字 #isdigt:bytes,unicode #判断是否只包含十进制数字,有小数点也不行 print(num1.isdigit()) #True print(num2.isdigit()) #True print(num3.isdigit()) #False print(num4.isdigit()) #False #isdecimal:uncicode 判断是否只含有十进制字符 #bytes类型无isdecimal方法 print(num2.isdecimal()) #True print(num3.isdecimal()) #False print(num4.isdecimal()) #False #isnumberic:unicode,中文数字,罗马数字 #bytes类型无isnumberic方法 print(num2.isnumeric()) #True print(num3.isnumeric()) #True print(num4.isnumeric()) #True #三者不能判断浮点数 num5='4.3' print(num5.isdigit()) #False print(num5.isdecimal()) #False print(num5.isnumeric()) #False #is其他 name='sunqi123' print(name.isalnum()) #字符串由字母或数字组成 print(name.isalpha()) #字符串只由字母组成 print(name.isidentifier())#是否首字母是字母 print(name.islower())#是否是小写 print(name.isupper())#是否是大写 print(name.isspace())#是否只由空格组成。 print(name.istitle())#是否是标题,每个单词首字母都要大写
字符串作业:
1、实现整型加法计算器:例如:5+9,5 + 9, 5+9。
1 x = input(">>:") 2 v = x.split("+") 3 sum = 0 4 for i in v: 5 sum = int(i.strip()) + sum 6 print(sum)
2、计算用户输入的内容有多少个十进制数字,有多少个字母。
1 x = input(">>:") 2 d_count = 0 3 l_count = 0 4 for i in x: 5 if i.isdecimal(): 6 d_count = d_count + 1 7 elif i.isalpha(): 8 l_count = l_count + 1 9 else: 10 pass 11 print("十进制数字的个数为:",d_count) 12 print("字母的个数为:",l_count)
二、列表
列表是实例化list类创建的数据类型
1 li = list({11,22,33,44}) 2 li_1 = [11,22,33,44] 3 print("li->",li) 4 print("li_1->",li_1)
列表元素的嵌套:字符串,数字,列表,还有接下来的元组,字典,……
1 li_1 = [11,"22",[55,66,88,[99,10,"qeqwre"]]]
通过索引查找到列表的元素,也正因此列表是有序的
列表也可以通过元素查找索引值,如果元素不存在就会报错
1 li = [1,2,3,"sunqi","tony"] 2 # print(li.index("sun")) 3 try: 4 print(li.index("tony")) 5 print(li.index("suq")) 6 except Exception as e: 7 print("未找到") 8 9 10 11 4 12 未找到
li_1[0] = 11
li_1[1][1] = "2"
li_1[2][3][1] = 10
可以通过列表的索引对列表的元素进行修改
1 li_1 = [11,"22",[55,66,88,[99,10,"qeqwre"]]] 2 li_1[2][3][1] = 1011 3 4 5 li_1-> [11, '22', [55, 66, 88, [99, 1011, 'qeqwre']]]
列表支持索引切片替换
1 li_1 = [11,"22",[55,66,88,[99,10,"qeqwre"]]] 2 li_1[0:2] = [99,20] 3 4 print("li_1->",li_1) 5 6 li_1-> [99, 20, [55, 66, 88, [99, 10, 'qeqwre']]]
支持切片删除(del)
li_1 = [11,"22",[55,66,88,[99,10,"qeqwre"]]] del li_1[0:2] print(li_1) [[55, 66, 88, [99, 10, 'qeqwre']]]
列表反转
li_1[ : : -1]
支持成员运算符in,但是in 只能查询一层的而不能查询嵌套的。
做嵌套成员查询时需要指定索引
li_1 = [11,"22",[55,66,88,[99,10,"qeqwre"]]] print(11 in li_1) print(55 in li_1) print(55 in li_1[2]) True False True
如何将字符串转换成列表?
v= list("abcdefg")
被list转换的对象要求是可迭代的,最简单的理解就是支持for循环的
列表如何转换为字符串?
(1)如果列表为纯字符串列表,则可以使用字符串的 join 方法
"".join(list)
(2)如果列表既含有数字,又含有字符串,则需要手动编写for循环
列表常用方法:
1 li = [11,22,33,44] 2 li.append(“55”)追加到最后,返回值为none,直接将传入的参数作为一个整体加入列表 3 li.clear()清空列表 4 b = li.copy()浅拷贝只拷贝一层 5 li.count("22")统计规定元素的个数 6 li.extend(iterable)扩展原来的列表,必须传递可迭代对象的参数li.extend([9898,"不得了"]) 7 li.index("22")获取当前值的索引 8 li.insert(位置,值)指定位置插入指定值 9 li.pop(0)删除指定的位置的值并返回删除的值,如果不指定位置则是最后一个并返回删除的值 10 li.remove("11")删除指定的值,若有多个则删除第一个,也就是左边优先 11 li.reverse()反转列表 12 li.sort()排序:默认从小到大, reverse = True从大到小
三、元组
元组是实例化tuple类创建的数据类型
元组也可以嵌套任意数据类型
元组也是有序的
tu = (11,22,33,[44,55,"77"])
tu = (11,22,33,[44,55,"77"]) tu[0] = "12" print(tu) 修改元组的第一层元素会报错 TypeError: 'tuple' object does not support item assignment
元组与列表的最大区别是元组是不可修改的
这种不可修改性体现在元组的第一层元素是不可以被修改的。
可以修改第二层前提是第二层元素是可修改的。
四、字典
字典是通过实例化dict类创建的数据类型
字典的存储方式是键值对 的形式:key: value
字典的键可以是数字,字符串,布尔值,但是不允许是列表,和字典
字典的value可以是任意类型的值
1 dic = { 2 11:11, 3 "22":"22", 4 True :"adada", 5 "test":[11,22,33], 6 } 7 print(dic) 8 9 10 {11: 11, '22': '22', True: 'adada', 'test': [11, 22, 33]}
字典是无序的,没有索引值,不能通过索引值访问字典的元素
访问字典元素的方式:
1、for循环遍历字典
dic = { 11:11, "22":"22", True :"adada", "test":[11,22,33], } for i in dic: print(i) 11 22 True test#默认循环字典的键
2、dic.keys()
循环输出字典的键
3、dic.values()
循环输出字典值
1 dic = { 2 11:11, 3 "22":"22", 4 True :"adada", 5 "test":[11,22,33], 6 7 } 8 for i in dic.values(): 9 print(i)
4、dic.items()
遍历数值字典的键和值
1 dic = { 2 11:11, 3 "22":"22", 4 True :"adada", 5 "test":[11,22,33], 6 7 } 8 for k,v in dic.items(): 9 print(k,v) 10 11 12 11 11 13 22 22 14 True adada 15 test [11, 22, 33]
5、dic.get("key")
取出指定key的值,如果key不存在,则返回默认值none
1 dic = { 2 11:11, 3 "22":"22", 4 True :"adada", 5 "test":[11,22,33], 6 7 } 8 v = dic.get("22") 9 print(v) 10 b = dic.get("33") 11 print(b) 12 13 14 22 15 None
6、删除字典的键值对
(1)pop()删除指定的key,并返回删除的key的value
v = dic.pop("test") print(v) [11,22,33]
(2)popitem删除最后一个元素,并返回删除的键和值组成的元组
1 v = dic.popitem() 2 print(v) 3 4 5 ('test', [11, 22, 33])
(3)dic.setdefault(k,value=None)
设置字典的键值对,如果指定的键已经存在,则返回存在的value,如果不存在,则添加键值对。
1 a = dic.setdefault("13","789") 2 v = dic.setdefault(11,"789") 3 print(a,v) 4 print(dic) 5 6 789 11 7 {11: 11, '22': '22', True: 'adada', 'test': [11, 22, 33], '13': '789'}
(4)dic.update(**kwargs)
更新字典,如果键存在,则替换值,不存在则添加,返回值为none
a = dic.update({"k1":"v1",11:"dhqih"})
print(a)
print(dic)
None
{11: 'dhqih', '22': '22', True: 'adada', 'test': [11, 22, 33], 'k1': 'v1'}
列表嵌套字典排序
有如下列表,请按照年龄排序(涉及到匿名函数) l=[ {'name':'sunqi','age':24}, {'name':'tony','age':3}, {'name':'su','age':18}, ]
l.sort(key=lambda item:item["age"])
五、布尔值
布尔值只有两种
(1)True 在计算机中存为1
(2)False 在计算机中存为0,常见的False类型:空列表,空字典,空字符串,空元组,0,none
可以调用bool()函数进行布尔值的判断
六、集合
集合是通过实例化set类创建的数据类型
集合特点:
(1)集合的每个元素都不相同
(2)集合是无序的
(3)集合的元素必须是不可变的(不能是列表,字典……)
1 s = {1,3,3,4,(2,3,4)} 2 print(s) 3 4 5 {1, (2, 3, 4), 3, 4} 6 集合的元素是无序的
集合方法:
1、set.add()
向集合中添加元素
s = {1,3,3,4,(2,3,4)}
s.add("sunqi")
print(s)
{1, 3, 4, 'sunqi', (2, 3, 4)}
2、set.remove()
删除集合的指定元素,如果元素不存在就会报错
1 s = {1,3,3,4,(2,3,4)} 2 3 s.remove(1) 4 print(s)
3、set.pop()
删除集合中的随机一个元素并返回删除的元素
1 s = {"suqni",1,3,3,4,(2,3,4)} 2 a = s.pop() 3 print(s) 4 print(a)
{3, 4, 'suqni', (2, 3, 4)}
1
4、set.clear()
清空集合
5、set.discard()
移除指定的元素,如果元素不存在,do nothing 不会报错
6、union方法
求出两个集合的并集
1 s1 = {"sunqi",1,3,4,(2,3,4)} 2 s2 = {"abc",1,3,7,8,(2,3,4)} 3 a = s1.union(s2) 4 print(a) 5 6 7 {1, 'sunqi', 3, 4, 'abc', 7, 8, (2, 3, 4)}
7、intersection方法
求出两个集合的交集
1 s1 = {"sunqi",1,3,4,(2,3,4)} 2 s2 = {"abc",1,3,7,8,(2,3,4)} 3 a = s1.intersection(s2) 4 print(a) 5 6 {1, (2, 3, 4), 3}
8、difference方法
找出第一个集合与第二个集合的差集,就是第一个集合减去与第二个集合相同的元素
1 s1 = {"sunqi",1,3,4,(2,3,4)} 2 s2 = {"abc",1,3,7,8,(2,3,4)} 3 a = s1.difference(s2) 4 s1.difference_update(s2)#得出差集并将差集更新到s1 5 print(s1) 6 print(a)
9、symmetric_difference方法
symmetric_difference_update()求补集并更新s1
补集
1 s1 = {"sunqi",1,3,4,(2,3,4)} 2 s2 = {"abc",1,3,7,8,(2,3,4)} 3 b = s1.intersection(s2) 4 a = s1.symmetric_difference(s2) 5 c = s1.union(s2) 6 print("交集",b) 7 print("补集",a) 8 print("并集",c)
1 交集 {1, (2, 3, 4), 3} 2 补集 {'sunqi', 4, 'abc', 7, 8} 3 并集 {'sunqi', 1, 3, 4, 'abc', 7, 8, (2, 3, 4)}
10、issubset 和 issuperset 方法
判断子集和父集
1 s1 = {1,3,(2,3,4)} 2 s2 = {"abc",1,3,7,8,(2,3,4)} 3 a = s1.issubset(s2)#s1是s2的子集 4 b = s1.issuperset(s2) 5 print(a)#True 6 print(b)#False
11、isdisjoint方法
判断两个集合是否有交集,有则返回True
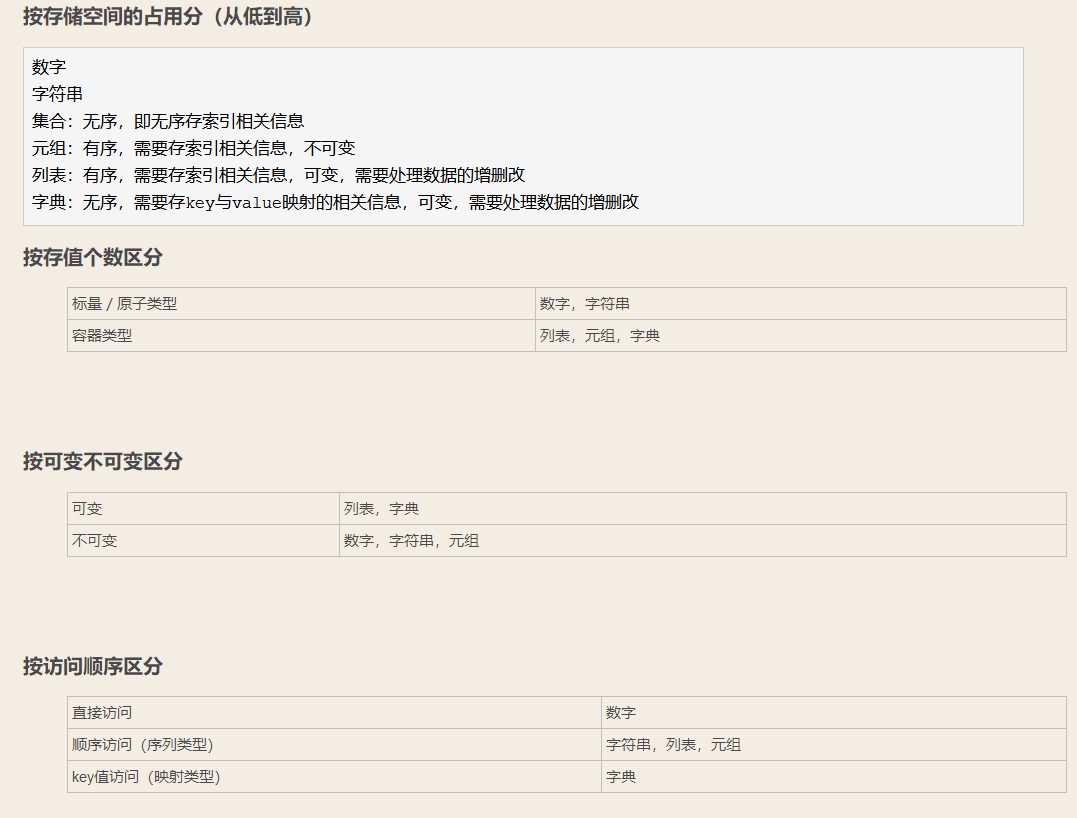
数据类型总结