logstash 配置文件编写详解
说明
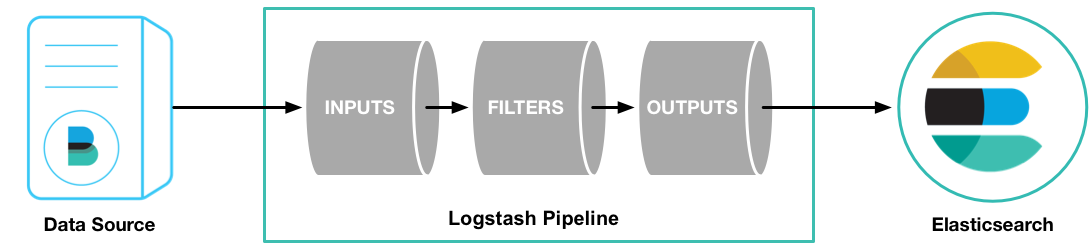
它一个有jruby语言编写的运行在java虚拟机上的具有收集分析转发数据流功能的工具
能集中处理各种类型的数据
能标准化不通模式和格式的数据
能快速的扩展自定义日志的格式
能非常方便的添加插件来自定义数据
通过在配置文件编写输入(input),过滤(filter),输出(output)相关规则,对数据收集转发。
配置文件编写语法
数据类型
boolen: 布尔 a => true
Bytes: 字节 a => “10MiB”
Strings:字符串 a => “hello world”
Number: 数值 a => 1024
Array: 数组 match => [“datatime”,“UNIX”,“ISO8601”]
Hash: 哈希 options => { key1 => “value1”,key2 => “value2” }
编码解码: codec: codec => “json”
密码型: my_passwd => “password”
路径: my_path => “/tmp/logstash”
注释: #
条件判断
==,!= ,< ,> ,<= ,>=
=~
in,not in
and ,or , nand, xor
(), !()
if expression {
} else if expression {
…
} else {
…
}
字段引用
%{[response][status]}
实例配置操作
# 输入
input {
...
}
# 过滤器
filter {
...
}
# 输出
output {
...
}input实例
input {
# file为常用文件插件,插件内选项很多,可根据需求自行判断
file {
path => "/var/log/httpd/access_log" # 要导入的文件的位置,可以使用*,例如/var/log/nginx/*.log
Excude =>”*.gz” # 要排除的文件
start_position => "beginning" # 从文件开始的位置开始读,默认是end
ignore_older => 0 # 多久之内没修改过的文件不读取,0为无限制,单位为秒
sincedb_path => "/dev/null" # 记录文件上次读取位置;输出到null表示每次都从文件首行开始解析
add_field=>{"test"="test"} # 增加一个字段
type => "apache-log" # type字段,可表明导入的日志类型
}
}input拥有多个插件,选择对应的插件获取相应的数据。相关链接:input相关插件
filter实例
插件grok插件
grok插件有非常强大的功能,他能匹配一切数据,但是他的性能和对资源的损耗同样让人诟病。相关插件:filter相关插件链接
方法一:
filter{
grok{
#首先要说明的是,所有文本数据都是在Logstash的message字段中的,我们要在过滤器里操作的数据就是message。
#只说一个match属性,他的作用是从message 字段中把时间给抠出来,并且赋值给另个一个字段logdate。
#第二点需要明白的是grok插件是一个十分耗费资源的插件。
#第三点需要明白的是,grok有超级多的预装正则表达式,这里是没办法完全搞定的,也许你可以从这个大神的文章中找到你需要的表达式
#http://blog.csdn.net/liukuan73/article/details/52318243
#但是,我还是不建议使用它,因为他完全可以用别的插件代替,当然,对于时间这个属性来说,grok是非常便利的。
match => ['message','%{TIMESTAMP_ISO8601:logdate}']
}
}
方法二:
filter {
grok {
match => {"message"=>"%{IPORHOST:clientip}s+%{WORD:method}s+%{URIPATHPARAM:request}s+%{NUMBER:bytes}s+%{NUMBER:duration}"}
}
} output实例
插件elasticsearch,相关插件链接地址:output插件地址
elasticsearch{
hosts=>["10.0.0.11:9200"] # elasticsearch 地址 端口
action=>"index" # 索引
index=>"indextemplate-logstash" # 索引名称
#document_type=>"%{@type}"
document_id=>"ignore"
template=>"/opt/logstash-conf/es-template.json" # 模板文件的路径
template_name=>"es-template.json" # 在es内部模板的名字
template_overwrite=>true #
protocol => "http" #目前支持三种协议 node、http 和tranaport
}