RabbitMQ是一个开源的AMQP实现,服务器端用Erlang语言编写,支持多种客户端,如:Python、Ruby、.NET、Java、JMS、C、PHP、ActionScript、XMPP、STOMP等,支持AJAX。用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。
AMQP,即Advanced message Queuing Protocol,高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。消息中间件主要用于组件之间的解耦,消息的发送者无需知道消息使用者的存在,反之亦然。
AMQP的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、安全。
集群概述
通过 Erlang 的分布式特性(通过 magic cookie 认证节点)进行 RabbitMQ 集群,各 RabbitMQ 服务为对等节点,即每个节点都提供服务给客户端连接,进行消息发送与接收。
这些节点通过 RabbitMQ HA 队列(镜像队列)进行消息队列结构复制。本方案中搭建 3 个节点,并且都是磁盘节点(所有节点状态保持一致,节点完全对等),只要有任何一个节点能够工作,RabbitMQ 集群对外就能提供服务。
环境
- VMware版本号:12.0.0
- CentOS版本:CentOS 7.3.1611
- RabbitMQ版本:RabbitMQ 3.6
- 虚拟机(IP):192.168.252.101,192.168.252.102,192.168.252.103
安装 RabbitMQ
单机安装
首先在三台主机上都安装 Erlang 安装 RabbitMQ Server
配置集群
修改 hostname
临时生效hostname
命令格式
hostname <new hostname>
在三台机器执行如下命令
192.168.252.101 $ hostname node1
192.168.252.102 $ hostname node2
192.168.252.103 $ hostname node3
查看修改后的hostname
$ hostname
- 临时修改启动集群好像有点问题,不推荐
永久更改hostname
修改 hosts
编辑/etc/hosts文件,添加到在三台机器的/etc/hosts中以下内容
$ vi /etc/hosts
192.168.252.101 node1
192.168.252.102 node2
192.168.252.103 node3
注意
三台主机上安装的 RabbitMQ 都保证都可以正常启动,才可以进行以下操作
停止RabbitMQ 服务
$ service rabbitmq-server stop
Redirecting to /bin/systemctl stop rabbitmq-server.service
设置 Erlang Cookie
设置不同节点间同一认证的Erlang Cookie
这里将 node1 的该文件复制到 node2、node3,由于这个文件权限是 400为方便传输,先修改权限,非必须操作,所以需要先修改 node2、node3 中的该文件权限为 777
$ chmod 777 /var/lib/rabbitmq/.erlang.cookie
$ scp /var/lib/rabbitmq/.erlang.cookie node2:/var/lib/rabbitmq/
$ scp /var/lib/rabbitmq/.erlang.cookie node3:/var/lib/rabbitmq/
- 然后将 node1 中的该文件拷贝到 node2、node3,最后将权限和所属用户/组修改回来
$ chmod 400 /var/lib/rabbitmq/.erlang.cookie
$ chown rabbitmq /var/lib/rabbitmq/.erlang.cookie
$ chgrp rabbitmq /var/lib/rabbitmq/.erlang.cookie
会提示输入yes 和 密码
注意事项
cookie在所有节点上必须完全一样,同步时一定要注意。
erlang是通过主机名来连接服务,必须保证各个主机名之间可以ping通。可以通过编辑/etc/hosts来手工添加主机名和IP对应关系。如果主机名ping不通,rabbitmq服务启动会失败。
运行各节点
$ rabbitmqctl stop
$ rabbitmq-server -detached
组成集群
这个也可以不执行,直接在节点服务器执行下边的脚本,不过得保证这个rabbitmq服务是正常启动的
node1 $ rabbitmqctl stop_app
按照顺序执行 先node2,node3
node2 $ rabbitmqctl stop_app # 停止rabbitmq服务
node2 $ rabbitmqctl join_cluster rabbit@node1 # node2和node1构成集群, node2必须能通过node1的主机名ping通
node2 $ rabbitmqctl start_app # 开启rabbitmq服务
node3 $ rabbitmqctl stop_app # 停止rabbitmq服务
node3 $ rabbitmqctl join_cluster rabbit@node1 # node3和node1构成集群, node2必须能通过node1的主机名ping通
node3 $ rabbitmqctl start_app # 开启rabbitmq服务
此时 node2 与 node3 也会自动建立连接
设置内存节点
其中–ram指的是作为内存节点,要是想做为磁盘节点的话,就不用加–ram这个参数了
加入内存节点集群
node2 # rabbitmqctl join_cluster --ram rabbit@node1
只要在节点列表里包含了本身,它就成为一个磁盘节点。
在RabbitMQ集群里,必须至少有一个磁盘节点存在。
更改节点属性
node2 $ rabbitmqctl stop_app # 停止rabbitmq服务
node2 $ rabbitmqctl change_cluster_node_type ram # 更改节点为内存节点
Turning rabbit@node2 into a ram node
node2 $ rabbitmqctl change_cluster_node_type disc # 更改节点为磁盘节点
Turning rabbit@node2 into a disc node
node2 $ rabbitmqctl start_app # 开启rabbitmq服务
查看集群状态
执行完之后分别在每台机器上查看节点状态
[root@node1 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@node1
[{nodes,[{disc,[rabbit@node1,rabbit@node2,rabbit@node3]}]},
{alarms,[{rabbit@node2,[]},{rabbit@node3,[]}]}]
[root@node2 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@node2
[{nodes,[{disc,[rabbit@node1,rabbit@node2,rabbit@node3]}]},
{running_nodes,[rabbit@node3,rabbit@node2]},
{cluster_name,<<"rabbit@localhost">>},
{partitions,[]},
{alarms,[{rabbit@node3,[]},{rabbit@node2,[]}]}]
[root@node3 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@node3
[{nodes,[{disc,[rabbit@node1,rabbit@node2,rabbit@node3]}]},
{running_nodes,[rabbit@node2,rabbit@node3]},
{cluster_name,<<"rabbit@localhost">>},
{partitions,[]},
{alarms,[{rabbit@node2,[]},{rabbit@node3,[]}]}]
第一行是集群中的节点成员,disc表示这些都是磁盘节点
第二行是正在运行的节点成员
登录后台
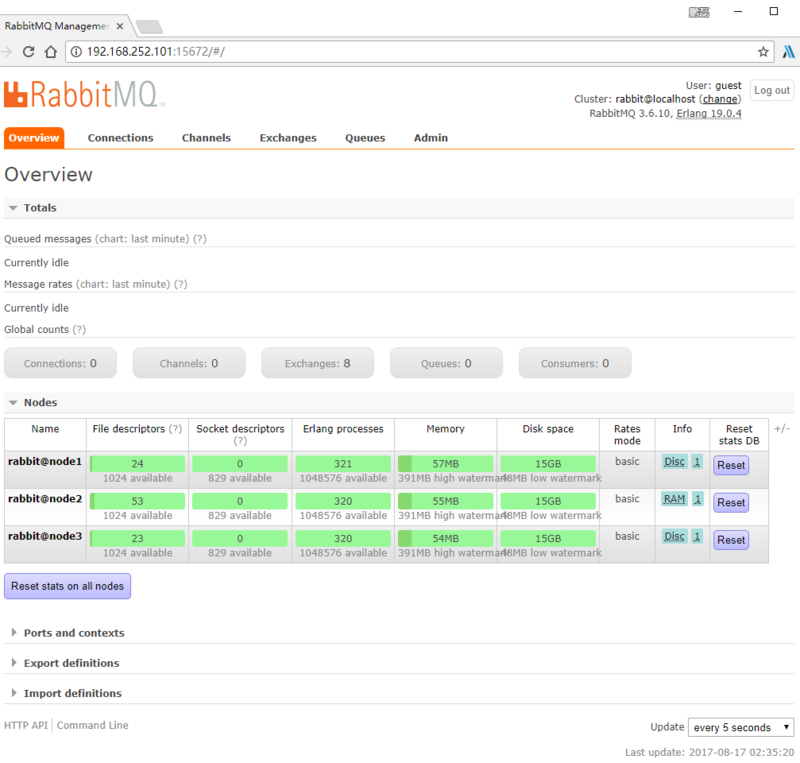
上面配置RabbitMQ默认集群模式,但并不保证队列的高可用性,尽管交换机、绑定这些可以复制到集群里的任何一个节点,但是队列内容不会复制,虽然该模式解决一部分节点压力,但队列节点宕机直接导致该队列无法使用,只能等待重启,所以要想在队列节点宕机或故障也能正常使用,就要复制队列内容到集群里的每个节点,需要创建镜像队列
镜像队列概念
镜像队列可以同步queue和message,当主queue挂掉,从queue中会有一个变为主queue来接替工作。
镜像队列是基于普通的集群模式的,所以你还是得先配置普通集群,然后才能设置镜像队列。
镜像队列设置后,会分一个主节点和多个从节点,如果主节点宕机,从节点会有一个选为主节点,原先的主节点起来后会变为从节点。
queue和message虽然会存在所有镜像队列中,但客户端读取时不论物理面连接的主节点还是从节点,都是从主节点读取数据,然后主节点再将queue和message的状态同步给从节点,因此多个客户端连接不同的镜像队列不会产生同一message被多次接受的情况。
设置镜像队列策略
在普通集群的中任意节点启用策略,策略会自动同步到集群节点
命令格式
set_policy [-p vhostpath] {name} {pattern} {definition} [priority]
在任意一个节点上执行
[root@node1 ~]# rabbitmqctl set_policy -p / ha-allqueue "^message" '{"ha-mode":"all"}'
Setting policy "ha-allqueue" for pattern "^message" to "{"ha-mode":"all"}" with priority "0"
注意:"^message" 这个规则要根据自己修改,这个是指同步"message"开头的队列名称,配置时使用的应用于所有队列,所以表达式为"^"
集群重启
集群重启时,最后一个挂掉的节点应该第一个重启,如果因特殊原因(比如同时断电),而不知道哪个节点最后一个挂掉。可用以下方法重启:
先在一个节点上执行
$ rabbitmqctl force_boot
$ service rabbitmq-server start
在其他节点上执行
$ service rabbitmq-server start
查看cluster状态是否正常(要在所有节点上查询)。
$ rabbitmqctl cluster_status