1. pre
title: Look Closer to Supervise Better One-Shot Font Generation via Component-Based Discriminator
ref: https://www.bilibili.com/video/BV13Y411w7yL
paper: https://arxiv.org/abs/2205.00146
code: https://github.com/kyxscut/CG-GAN
这篇是一种one-shot 的字体生成方法,也是基于对汉字进行组件分解,亮点在于生成器架构较为简单,模型性能主要通过给予生成器更多的监督信息来取得(判别器、组件级判别器、风格分类器,CAM模块),就是说它的损失函数很多
2. abstract
FFG任务困难,推理时数据少,总结前人经验,粗粒度判别器不足以监督字体生成。为此提出了Component-Aware Module (CAM),能监督生成器更细粒度地解耦内容和风格。之前的工作都是增加生成器的复杂度,这里给简单生成器更有效的监督信息,以此激发生成器的所有潜能,这对字体生成来说是一个新视角。通过结合组件监督和对抗学习,框架效果很好,因此叫做Component-Guided GAN, 也就是CG-GAN。该方法在one-shot字体生成取得了SOTA性能。同时它也能用于handwritten word synthesis手写字合成和scene text image editing场景文本编辑,表现出了良好的泛化性。
3. introduction
人类评判字体风格更注重局部细节,如端点形状、笔锋、笔画粗细、连笔等等(endpoint shapes, corner sharpness, stroke thickness, joined-up writing pattern)。虽然组件体现不出倾斜度、长宽比等字体风格属性,但作者觉得比整个字的形状更能决定字体风格。
img
人学写字时先学一个个组件,组件都学会自然就会写字。藉由以上两点提出了本文的FFG方法。
FFG两个意义:减轻字体设计负担、创建跨语言字库。
方法亮点
- 性能提升是通过给予生成器更细粒度的监督信息
- 生成器能够捕捉局部风格样式,而不显式依赖于预定义的组件类别,one-shot汉字生成和跨语言字体生成效果很好
- 使用部件级监督是一种human-like方法,克服了以往方法使用成对训练数据进行像素级强监督的局限性
- CAM仅在训练阶段使用,推理时不用,没有额外计算时间
4. Related works
5. Methodology
设计部件感知模块CAM模仿人类学习,为生成器提供多尺度的风格和内容监督,促使其实现部件级别的风格内容解耦,引导生成器保持多尺度风格一致,字形正确性和图像真实性,使它更多地关注字形的局部细节。
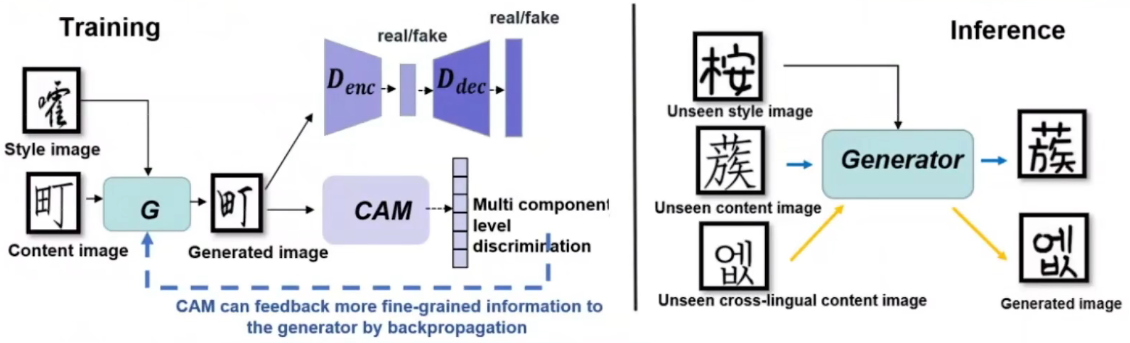
左图是训练示意图,CAM得到的信息将通过反向传播反馈给生成器,能够端到端进行训练(各模块都不用预训练)
右图说明生成器不显式依赖组件类别输入情况下能捕捉局部风格特征,实现跨语种字体生成
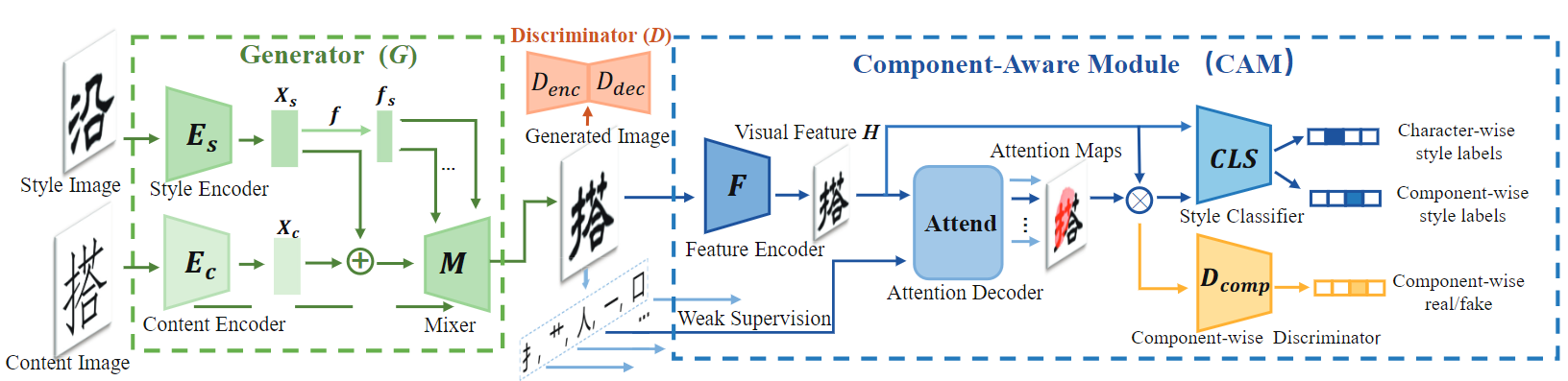
生成器包含风格编码器\(E_s\)和内容编码器\(E_c\),注意\(E_s\)输出是风格特征图\(X_s\)跟内容特征图\(X_c\)具有相同维度。之后\(X_s\)进一步通过映射网络转换为风格潜变量\(f_s\),随后通过AdaIN将\(f_s\)注入混合器Mixer中的每一层进行全局风格渲染,这一步跟StyleGAN的操作非常像。
输入Mixer前\(X_s\)和\(X_c\)会进行拼接,同时\(E_c\)跟Mixer各层之间具有残差连接。
随后Mixer进行特征融合并输出生成图像,随后将图像送入判别器D(橙色部分)跟CAM(蓝色部分),得到监督信息。
CAM是整个网络的重点,其中特征编码器F先对输出图像进行特征提取,然后将特征输入结合了注意力机制的Attention Decoder(本质是个RNN),它将字符拆分成多个部件并借助注意力机制进行识别,相当于加入了部件级的内容监督。
这里需要输入字符的部件序列作为弱监督,用它和decoder预测的部件序列计算交叉熵,得到一个 Structure Retention Loss \(L^{CAM}_{strc}、L^{G}_{strc}\)。
通过将数量较多的字符拆分成数量较少的部件的序列,加速收敛,并促使生成器里的\(E_c\)更加关注字形结构,保持字形一致性.
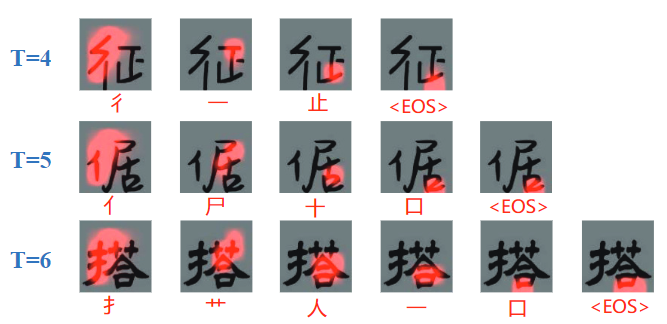
对Attention Map进行可视化,decoder能够较好地关注到部件区域,将每个时间步得到的attention map(输出是部件序列,那么一个map就对应了一个部件)跟特征图H相乘得到的加权特征图代表了对应的部件信息,可以用于后续的判别
此外还用了Style Classifier (CLS)去监督输入图片的全局和局部风格一致性:style matching loss(\(L^{CAM}_{sty}、L^{G}_{sty}\))。
将代表全局信息的原始特征图和代表局部信息的加权特征图输入CLS,用识别出的风格id跟groundtruth计算交叉熵。
CLS将引导生成器的\(E_s\)获得更好的特征表达能力,能够在不显式依赖组件类别输入的情况下捕捉局部风格特征。
除此之外CAM里还有一个 Component-wise Discriminator \(D_{comp}\) 用于对每个component patch进行一个真假判别(输入是加权特征图),用于引导生成器更好地捕捉局部特征:Component Realism Loss \(L_{comp}\)
此外还引入了一个 Identity Loss \(L_{idt}\)来保证网络对目标域的恒等映射,即将同一张字形给生成器,输出图像应当与输入一模一样,计算二者的L1损失,用于确保\(E_c\)生成的comtent representation是style-invariant
最终损失项如下图所示,
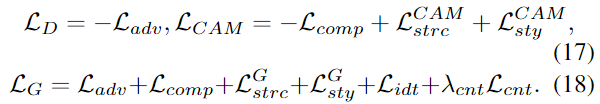
\(\lambda_{cnt}\)设置为10
6. Experiments
6.1. Chinese font generation
数据集,423种字体,其中随机选399种作为训练集,每个字体取800个字(seen characters),这800字能被385个部件覆盖。评估则基于两个数据集:399种见过的字体,每个字体取150个没见过的字;另一个是剩下的24种没见过的字体,每个取200个没见过的字。

在Unseen styles and unseen contents数据上的生成结果,主要与LF-Font对比。

Cross lingual font generation上的生成结果,这里没有跟MX-Font对比,对比的对象都挺弱的,似乎不太能说明问题

整个数据集上的定量评估,跟FsFont一样,可能注意力机制确实更好,各项指标都远超其他模型。特别是one-shot时就能超越8-shot的LF-Font(AAAI 2021)
6.2. Handwriting generation
6.3. Ablation study
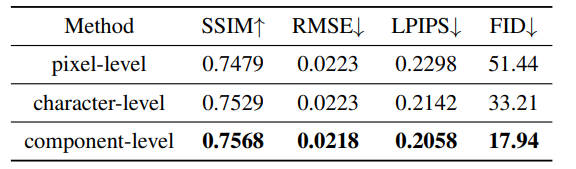
验证组件级监督的有效性
像素级监督:去掉CAM模块,并用L1损失替换组件级目标函数,
字符集监督:用字符标签替换组件标签
据上图,用组件监督效果最好,而且在FID指标上有显著优势
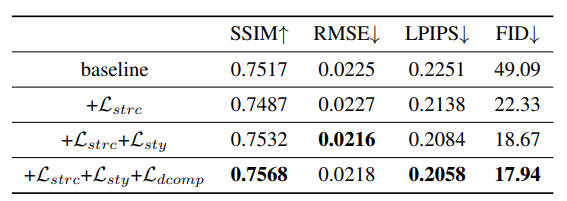
验证CAM的有效性
主要是各项损失函数的有效性,具体是去掉CAM模块作为baseline,然后逐步加入各项损失
可以看到损失确实有效,但效果就不是很明显了
7. Extension
8. Conclusion
文章对于one-shot字体生成任务提出了一种简单但有效的CG-GAN,特别是引入了CAM去监督生成器,CAM更加细粒度地解耦风格内容,即在组件级别上,去指导生成器取得更好的表现能力。更进一步,CG-GAN是第一个能扩展到手写词(英文)生成handwriting word generation跟场景文本编辑scene text editing任务上的FFG方法,展现了它的泛化能力。
9. Supplementary Material
A Implementation
模型使用Adam优化,\(\beta_1=0.5, \beta_2=0.999\)
卷积和线性层权重根据高斯分布\(\Nu(0, 0.02)\)初始化。
实验基于PyTorch,并且在单张1080Ti上训练,批大小为16
在汉字字体生成中所有图片大小都是128x128,学习率只有0.0001,并且经过 40 epochs 训练后衰减至0
B Additional qualitative results
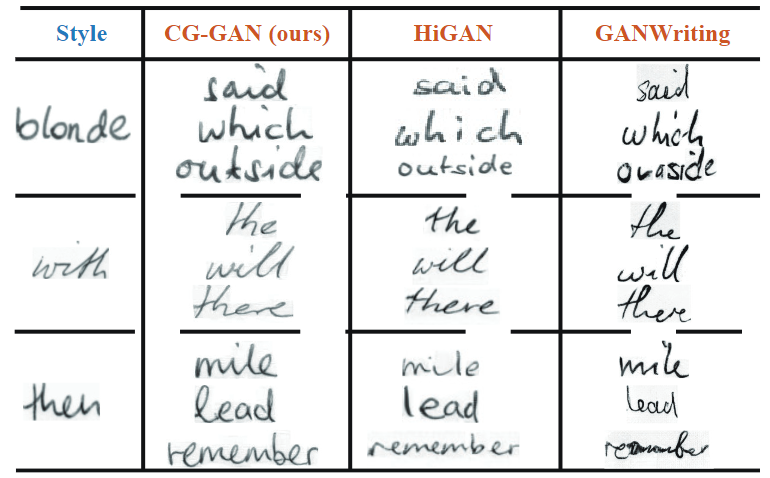
比较有趣的是模型无需其他改动,就可以直接应用到英文手写体合成任务上,这里是与其他模型生成结果的对比。

更多手写体生成效果,模型能够很好学到局部书写风格特征,如这里字符间的连笔。仔细看会发现背景也会被学习并生成, 如倒数第二行的with的灰暗背景,这跟后面的场景文本编辑就很像了
Latent space interpolations

也可以对风格隐向量进行插值,得到良好的过渡效果,得到更多的生成样本,或许也能作为文本识别的数据增广手段
Scene text editing

场景文本编辑,似乎是生成包含复杂背景的艺术字?可以看到效果很不错,还会根据字数的多少自动安排字符间距
Additional ablation results
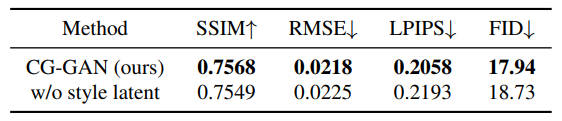
去掉了风格隐向量跟AdaIN注入,可以看到没啥影响,甚至还好了一些
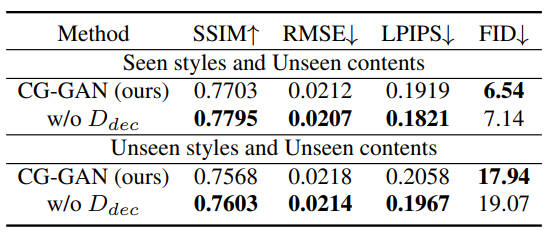
去掉了判别器的U-net结构,准确来说是去掉了上采样部分的结构,只留编码器,同样是没啥影响
作者解释这就是他们主要的目的,即模型性能不取决于复杂的网络结构。实际上代码中作者已经注释掉了U-net的部分,却保留了风格隐向量。