Towards Explainable NLP: A Generative Explanation Framework for Text Classification
Abstract
现有的可解释性机器学习系统关注于解释输入和输出的联系。而细粒度的信息(标签的文字解释)经常被忽略,并且系统不说人话(人看不懂)。
细粒度的信息---产品的各个组成部分(价格/包装/质量)
粗粒度---产品整体
为了解决这个问题,提出了一个文本生成解释框架,这个框架可以同时进行分类预测和解释预测结果的细粒度信息。提出了解释因子以及一个最小化风险训练方法,这个方法可以生成更合理的解释。
Introduction
A尝试在可解释的表示上识别一个可解释的模型,该模型在局部上忠实于分类器
局部保真度意味着解释需要很好地近似于模型对数据子集的预测。
B用热图可视化隐藏元素对预测结果的影响
这些方法没有使用解释模型行为的细粒度信息
正常人打分的习惯:先写一些评语,接着总结产品的一些属性并打分,最后给一个overall打分
因此,显式生成细粒度信息来解释预测对于建立可靠的可解释文本分类模型至关重要
idea:显式捕获从原始文本推断出的细粒度信息,利用这些信息帮助解释预测的分类结果,并提高整体表现
具体来说,引入了解释因子的概念和一个最小化风险训练方法,这样的策略使解释和预测之间联系紧密,能获得更好的表现。本文是第一个使用抽象的生成的细粒度信息来解释预测结果的模型。
本文中,将总结(文本)和打分(数字)看为细粒度的信息。
PCMag:数据集里每个item有一段关于产品的长评价文本,三段简短的文本评论(从积极、消极和中立角度解释产品的属性),一个整体打分。作者将三段短文本看作长评论文本的细粒度信息。Skytrax 用户评论数据集:每个实例包括三部分:一段对于航班的评价,五个关于航班不同方面的打分(座椅舒适度,机舱人员,食物,机舱内环境,机票价值),一个总体评分。对于这一数据集,作者将五个子得分看作飞机评论文本的细粒度信息。
本文的贡献:
- 第一个利用生成的细粒度信息建立文本分类的生成解释框架,提出了解释因子,介绍了用语该生成-判别混合模型的最小化风险训练方法
- 对比了本文框架和不同的神经网络架构的效果,发现本文方法带来显著提升
- 公开了两个NLP数据集,其中包括可用于文本分类结果解释的细粒度信息
Task Definition and Notations
什么是好的细粒度解释?比如产品有三个属性:质量、可用性和价格。如果模型判断产品好,且模型预测产品质量高,可用性好,价格低,则认为属性值较好地解释了模型的预测效果。
因此,对于模型做出的给定分类预测,我们想进一步研究细粒度的信息,这些信息可以解释为什么对当前示例做出这样的决定。同时,我们还想弄清楚从输入文本中推断出的细粒度信息是否可以帮助提高整体分类性能。
文本输入序列为\(S\{s_1,s_2,...,s_{|S|}\}\),需要预测\(S\)属于哪个类别\(y_i(i\in[1,2,...,N])\),为\(y_i\)生成细粒度解释\(e_c\)
Generative Explanation Framework
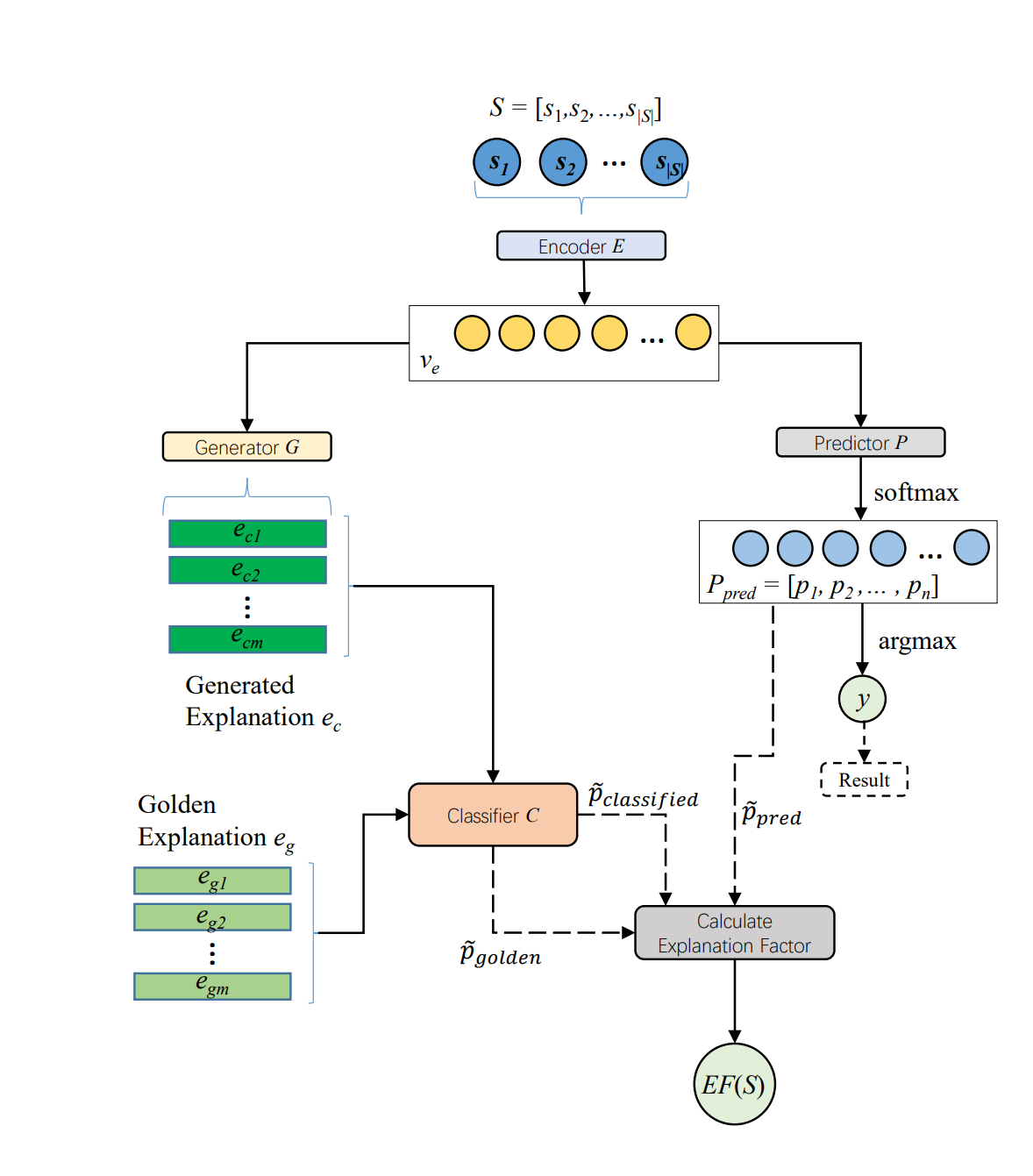
Encoder E将S编码为\(v_e\),Predictor P为各个类别提供分布概率\(P_{pred}\),并从\(P_{pred}\)中提取真值概率。生成器G将\(v_e\)作为输入并生成解释\(e_c\)。分类器和预测器P共同预测类别y。当\(e_c\)输入到c时,C对分布概率\(P_{classified}\) 进行预测,之后输出两个真值概率用于计算解释因子\(EF(S)\)
Base Classifier and Generator
编码器E接收文本序列S作为输入,将其转换为表示向量\(v_e\),类别预测器P接收ve作为输入,并输出预测类别\(y_i\)及其关联概率分布\(p_{pred}\)
生成解释的方法是将ve输入到一个解释生成器G,生成细粒度解释ec
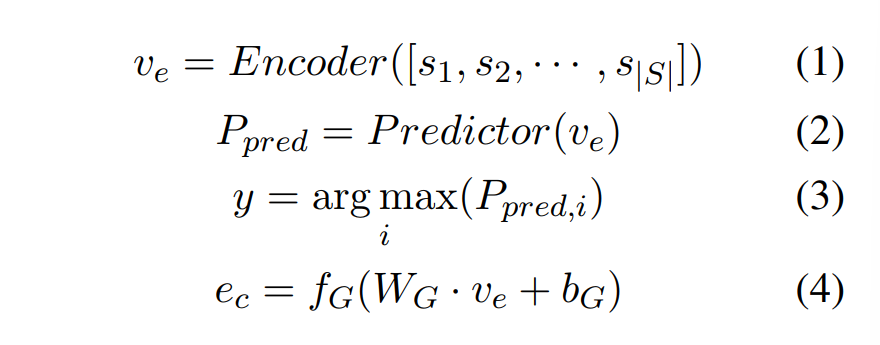
用softmax将分布转换为分类
损失函数L包括分类损失\(L_p\)和解释生成损失\(L_e\)
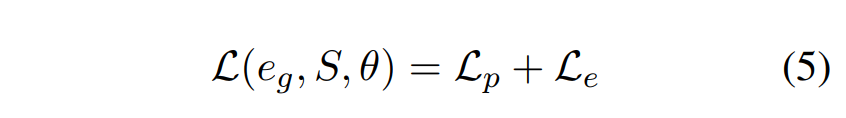
\(\theta\)表示所有参数
Explanation Factor
生成解释的监督方法非常简单(如上个section所示)。然而,这个生成过程有一个显著的缺点:不能在生成解释和预测的整体结果之间建立强联系。换句话说,生成解释似乎独立于预测的总体结果。因此,为了对结果产生更合理的解释,我们使用解释因子来帮助解释和预测之间建立更强的联系。
正如我们在介绍部分所演示的,细粒度信息有时会比原始输入文本序列更直观地反映总体结果。例如,给出一个评论句子“The product is good to use”,我们可能不确定该产品是否应该被评为5星或4星。但是,如果我们看到产品的属性都被评为5颗星,我们可能更相信该产品的总体评级应该是5颗星。
首先,我们预训练一个分类器C,它也会通过直接接受解释作为输入来预测类别y。更具体地说,C的目标是模仿人类的行为,这意味着C应该比以原文为输入的基模型更准确地预测总体结果。我们在实验部分证明了这个假设。
作者使用预训练分类器 C 为文本编码器 E 提供指导,使其能够生成一个含有更多信息量的向量表示 \(v_e\)。在训练过程中,作者首先使用解释生成器 G 得到生成性解释 \(e_c\) ,之后将\(e_c\)输入到分类器 C 中,得到预测结果 \(P_{classified}\) 的概率分布。同时,作者将人们可接受的文本解释 \(e_g\) 输入到分类器中,得到可接受的解释(golden explanation)的概率分布 \(P_{gold}\) ,公式如下:
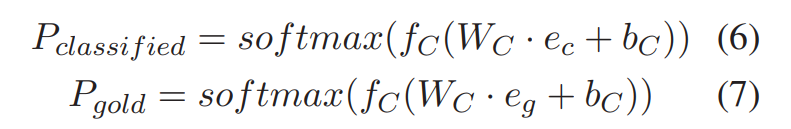
为了衡量预测结果、生成的解释和可接受解释的生成结果之间的距离,作者从 \(P_{classified}\), \(P_{pred}\),\(P_{gold}\) 中分别抽取了真值(ground-truth),用于衡量最小化风险训练中预测结果和ground-truth的差异。
定义解释因子为:
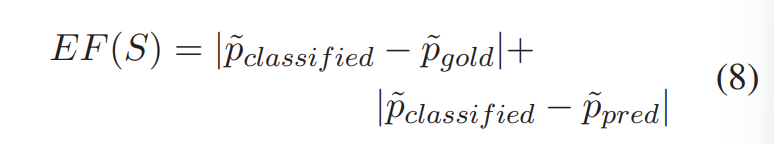
- 第一部分表示生成的解释 \(e_c\) 和可接受的解释 \(e_g\) 之间的距离。作者认为,由于使用了可接受的解释对 C 进行了预训练,当 C 接收了相似的解释时,其应当产生相似的预测结果。在该任务中,作者希望 \(e_c\) 可以表达与 \(e_g\) 相同或相似的含义。
- 第二部分表示生成解释 \(e_c\) 和原始文本S之间的相关性,生成的解释应当和原始文本的预测结果一致。
Minimum Risk Training
为了消除细粒度信息和输入文本之间的脱节,我们使用最小风险训练(Minimum risk training, MRT)来优化我们的模型,其目标是最小化预期损失。给定序列S和可接受的解释 \(e_g\) ,我们设\(\gamma(e_g,S,\theta)\) 为参数 θ 的整体预测结果集合,\(\Delta (y,\tilde y)\) 表示预测结果和ground-truth之间的语义距离,则目标函数为:
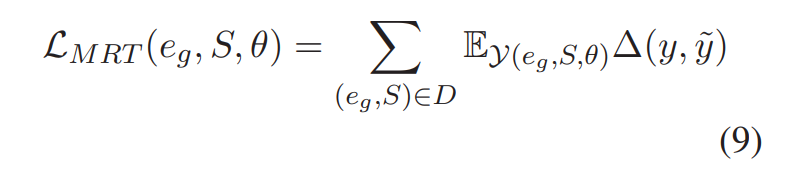
D表示整个训练数据集
在本文的实验中,\(E(e_g, S, θ)\) 是集合 \(γ(e_g, S, θ)\) 上的期望,即公式(5)中的整体损失。作者将解释因子 \(EF(S)\) 定义为输入文本、生成解释和可接受解释之间的语义距离,因此, MRT 的目标函数可表示为如下公式:
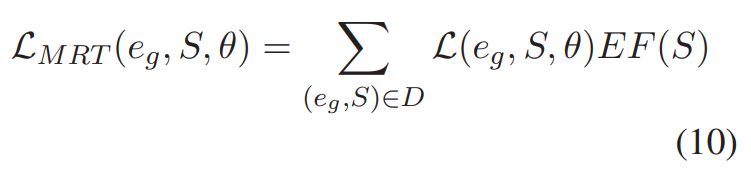
MRT 使用 EF(S) 衡量损失,以使用特定的评估指标对 GEF 进行优化。尽管当输入文本、生成解释和可接受解释的真值非常接近时, \(L_{MRT}\) 可取0或接近0,仍然不能保证生成的解释接近可接受解释。为了避免损失的性能退化,作者将最终的损失函数定义为 MRT 损失和解释生成损失的加和,即:
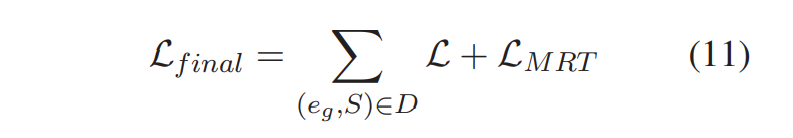
1:1的权重是试出来的
Application Case
一般来说,对于真实的数据集,细粒度的解释有不同的形式,这意味着\(e_c\)可以是文本的形式,也可以是数字分数的形式。我们使用不同的基模型将环境因子应用于这两种解释形式
Text Explanations
CVAE与传统的SEQ2SEQ模型相比能够生成情感文本并捕获更大的多样性。在该结构中,可接受的解释 eg 和生成解释 ec 包括积极、消极和中立三类评论。分类器为使用双向 GRU-RNN 结构的残差模型。模型的输入为三类评论,输出为预测分类的概率分布。
CVAE+GEF的结构:
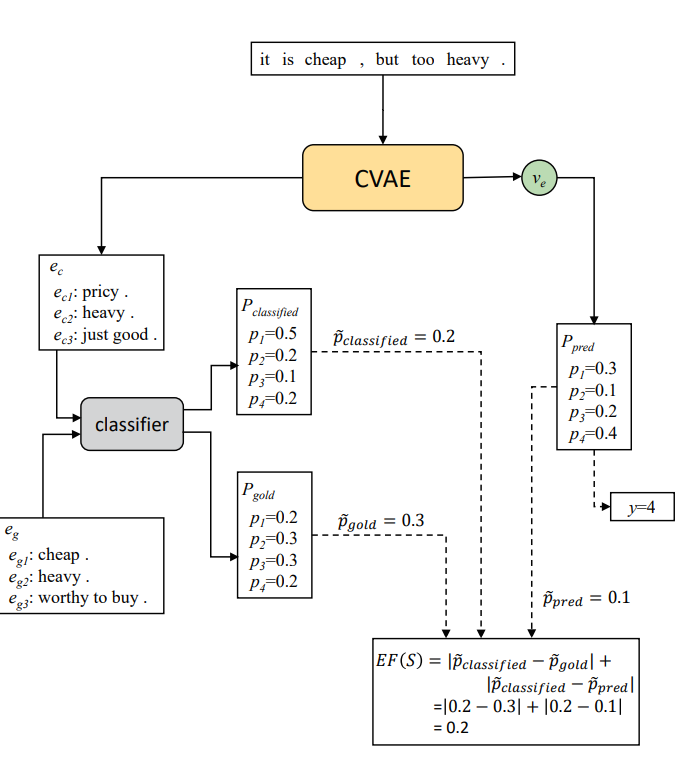
分类结果共有4类,本示例中的分类真值为2。作者假设预训练的分类器是一个“完美”的分类器,能在接收 eg 作为输入时将最终标签正确预测为2。因此作者希望向该结构输入 ec 时,同样能够得到结果为2。
Numerical Explanations
对总体结果进行细粒度解释的另一种常用形式是数值分数。例如,当用户想要评价一个产品时,他/她可能首先评价产品的一些属性,如包装、价格等。在对所有属性进行评级之后,她/他将给出产品的总体评级。所以我们可以说,属性的评级在某种程度上可以解释为什么用户给出总体评分。我们分别使用LSTM和CNN模型作为编码器E。在这个例子中,数值解释也被视为一个分类问题。
Dataset
在两个数据集上进行了实验,分别使用文本和数字评级来表示细粒度信息。第一个是从PCMag网站抓取的,另一个是Skytrax用户评论数据集。
PCMag Review Dataset
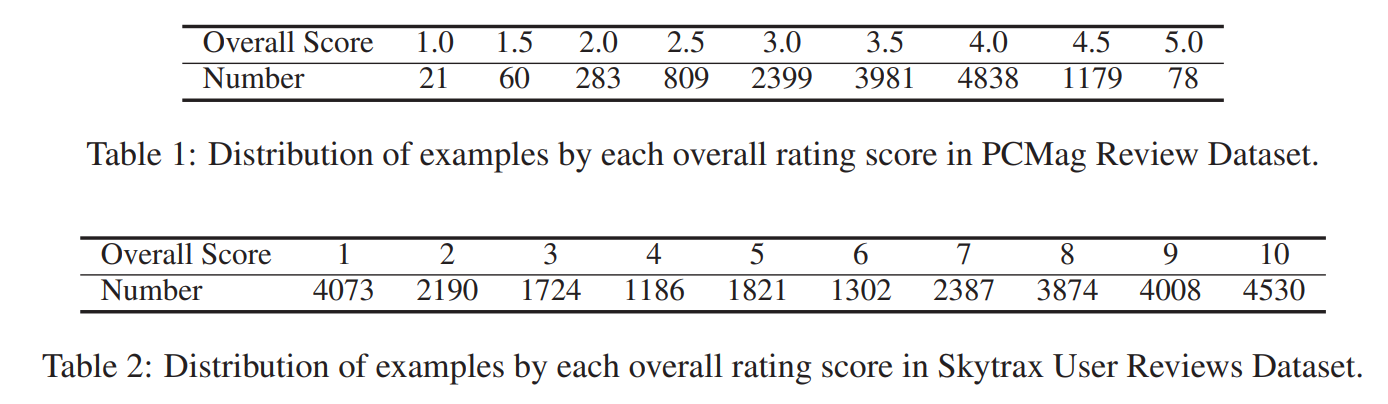
数据集是从PCMag网站抓取的。它是一个为笔记本电脑、智能手机、相机等电子产品提供评论的网站。数据集中的每一项都由三个部分组成:一个长的回顾文本、三个简短评论和产品的总体评分。三个简短的评论分别从积极、消极、中性的角度对长篇评论进行总结。总体评分是一个从0到5的数字,评分的可能值是{1.0,1.5,2.0,…, 5.0}。
由于长文本生成不是我们关注的内容,所以评论文本包含的内容多于70个句子或者token数>=75都会被过滤。我们将数据集随机分成10919/1373/1356对用于训练/dev/测试集。(见Table 1)
Skytrax User Reviews Dataset
我们合并了从Skytraxs Web门户获取的航空公司评论数据集。该数据集中的每个条目由三个部分组成:即一个评论文本、五个子字段的分数和一个总体评分。这五个子字段的分数分别表示用户对座椅舒适度、客舱物品、食物、飞行环境和机票价值的评分,每个分数都是0 ~ 5之间的整数。总分是1到10之间的整数。
类似于PCMag Review Dataset,我们过滤掉了Review包含超过300个token的项目。然后我们将数据集随机分成21676/2710/2709对用于训练/dev/测试集。(见Table 2)
Experiments and Analysis
Experimental Settings
为了检验所提出的GEF的有效性,我们在基模型和基模型+GEF上使用相同的实验设置。我们使用GloVe对PCMag数据集进行词嵌入,并使用Adam最小化目标函数。表3列出了这两个数据集的超参数设置。同时,由于文本解释的生成损失大于分类损失,当分类损失达到一定阈值(根据dev set调整)后,我们停止更新预测器,以避免过拟合。

Experimental Results
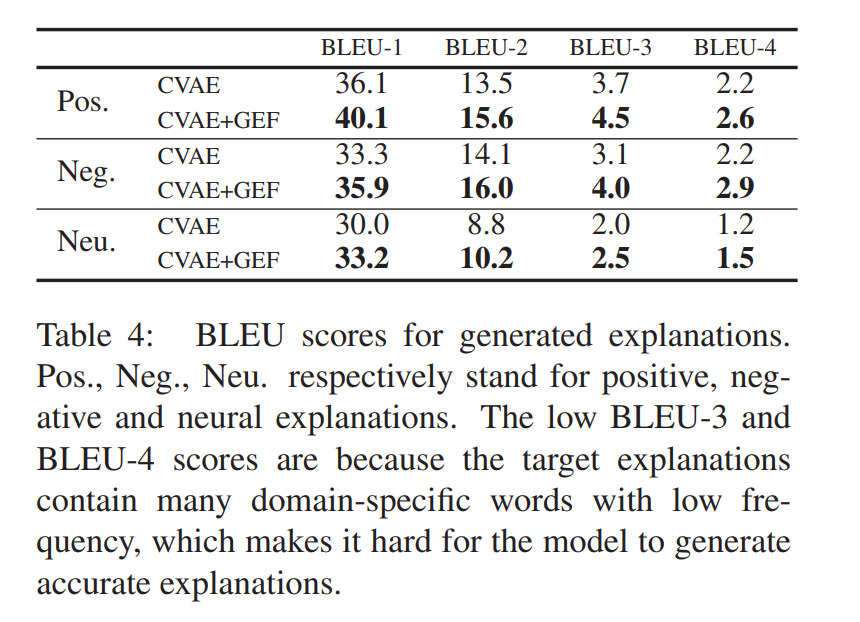
说明CVAE+GEF产生的解释具有较高的质量。CVAE+GEF可以产生更接近整体结果的解释,从而可以更好地说明我们的模型为什么会做出这样的决定。
我们认为,生成的细粒度解释应该为分类任务提供额外的指导,因此我们还比较了CVAE和CVAE + GEF。我们使用top-1准确度和top-3准确度作为分类性能的评价指标。在表5中,我们比较了CVAE+GEF和CVAE在测试集和验证集的结果。如表所示,CVAE+GEF的分类效果优于CVAE,说明细粒度信息确实有助于提高整体分类结果。
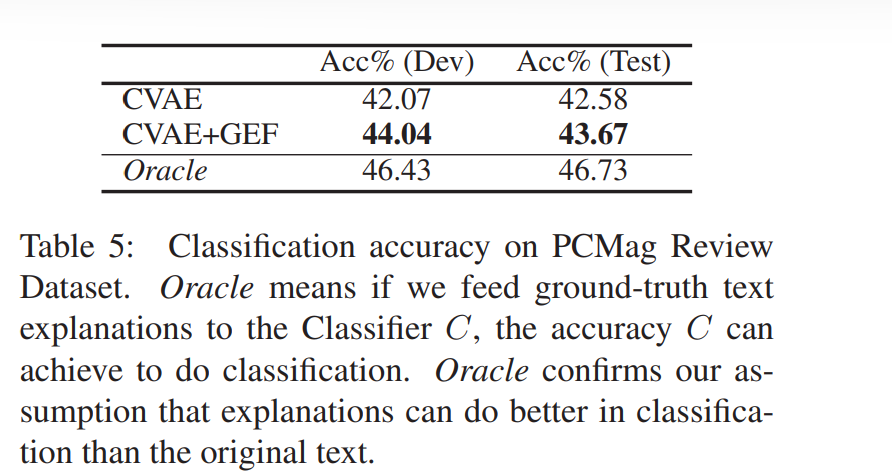
Oracle的意思是,如果我们向分类器C提供ground-truth文本解释,C可以提高分类的准确性。Oracle证实了我们的假设,解释在分类方面比原始文本做得更好。
如上所述,我们有一个假设,如果我们使用细粒度的解释分类,我们将比只使用原始输入文本得到更好的结果。因此,我们将分类器C的性能列在表5中进行比较。实验表明,C比CVAE和CVAE+GEF都有更好的性能,证明了我们的假设是合理的。