首次发布于:https://www.simonjia.top/495.html
有时候看到一些好的视频ppt,想把ppt内容记录下来,需要进行截图然后ocr识别,网上的工具大都限制使用次数,有的免费的只能一次次导入导出,各种验证码频次限制,所以使用起来不方便。现有的tess4j就是目前开源比较流行的ocr识别库了,今天down下来试了试,还不错,图片识别准确度和速度也都挺好的,完美解决我们的需求(不想充会员,ps--得力的ocr识别ui和速度都不错~)
导出下载项目地址:https://github.com/nguyenq/tess4j.git
本地下载好慢,用阿里云wget速度还不错(再下载本地),不然本地直接下载几十k真的忍受不了~
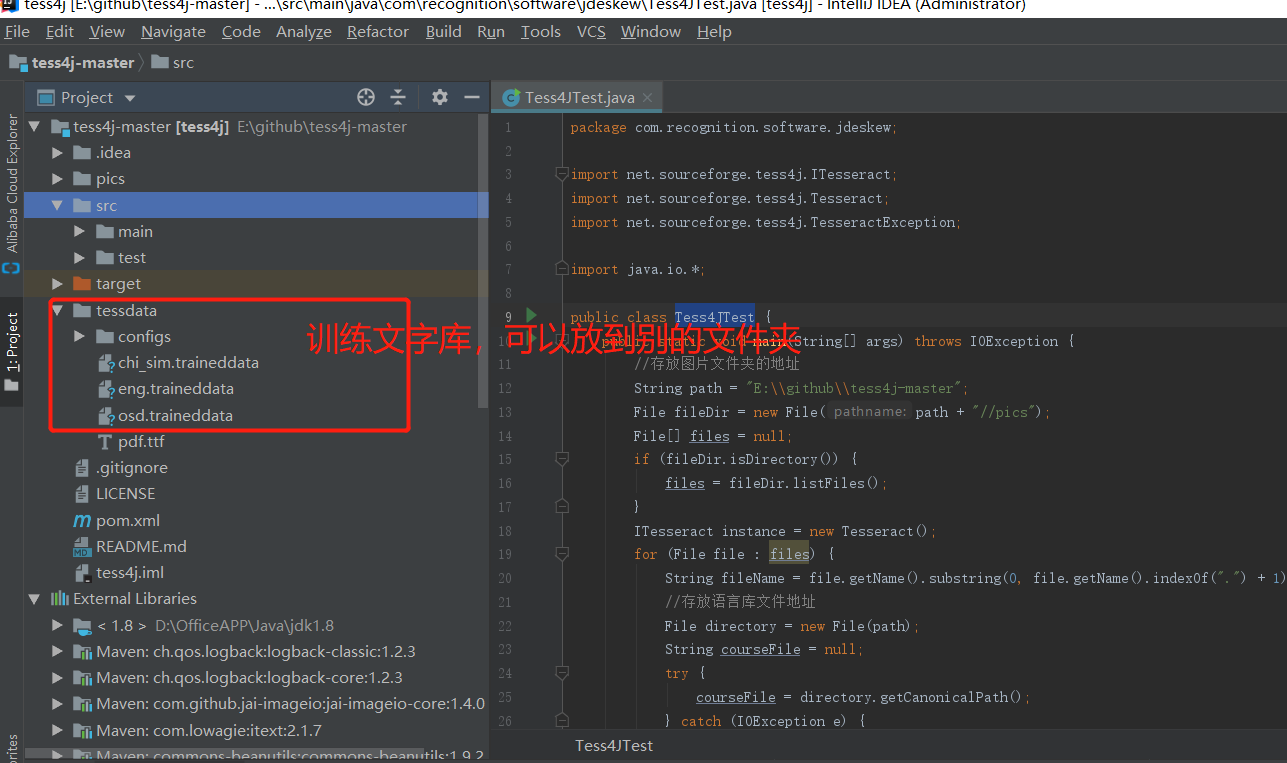
下载后默认没有中文字库,需要我们自己去下载--https://github.com/tesseract-ocr/tessdata/blob/master/chi_sim.traineddata
然后写个main方法:
package com.recognition.software.jdeskew;
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
import java.io.*;
public class Tess4JTest {
public static void main(String[] args) throws IOException {
//存放图片文件夹的地址
String path = "E:\github\tess4j-master";
File fileDir = new File(path + "//pics");
File[] files = null;
if (fileDir.isDirectory()) {
files = fileDir.listFiles();
}
ITesseract instance = new Tesseract();
for (File file : files) {
String fileName = file.getName().substring(0, file.getName().indexOf(".") + 1);
//存放语言库文件地址
File directory = new File(path);
String courseFile = null;
try {
courseFile = directory.getCanonicalPath();
} catch (IOException e) {
e.printStackTrace();
}
//设置训练库的位置
instance.setDatapath(courseFile + "//tessdata");
//chi_sim :简体中文, eng 根据需求选择语言库
instance.setLanguage("chi_sim");
String result = null;
try {
long startTime = System.currentTimeMillis();
result = instance.doOCR(file);
long endTime = System.currentTimeMillis();
System.out.println("Time is:" + (endTime - startTime) + " 毫秒");
} catch (TesseractException e) {
e.printStackTrace();
}
System.out.println("result: ");
System.out.println(result);
//将识别的文字放入不同文件内,也可以放一个,看需求- -
FileOutputStream fos = new FileOutputStream(new File("C:\Users\Administrator\Desktop\" + fileName + ".txt"));
OutputStreamWriter osw = new OutputStreamWriter(fos, "UTF-8");
BufferedWriter bw = new BufferedWriter(osw);
bw.write(result + "
");
bw.close();
osw.close();
fos.close();
}
}
}
我这里是读取一个pics文件夹,将里面所有图片都识别出来,然后每张图片各自写入一个txt文件中,
无需导入dll文件什么的,很方便,识别准确度也不错!