了解JVM的工作机制能够更好的帮助我们理解java语言本身,规避各种可能的错误。所以,今天趁此机会好好复习一下。来看看JVM是怎么工作的。
一、啥是JVM
JVM可以理解为用来运行java程序的一种运行时引擎(run-time engine)。没错,main方法就是由jvm调用作为入口方法的。JVM是JRE的重要组成部分。
JVM为java程序提供了一次编写,到处运行的基础。
当我们编译一个java文件时,就由编译器生成一个对应的class文件,当我们运行class文件时,JVM会对class文件进行一系列的调度工作。这就是JVM的职责所在。所以,想要弄清楚JVM的工作原理,就要弄清java程序在运行过程中每一步都发生了啥子。下图是JVM的一张架构图,预览一下~
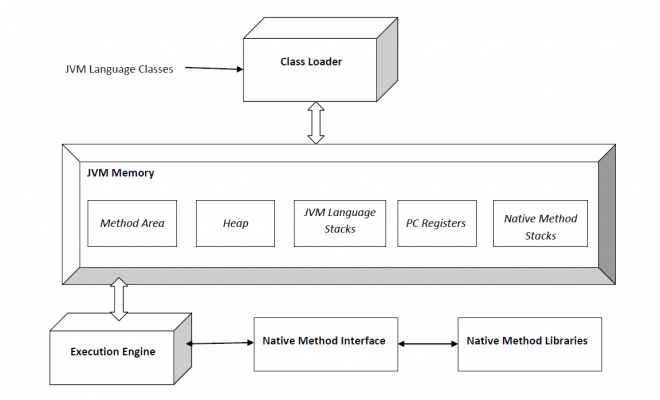
二、JVM的职责
JVM的职责主要包括三部分
装载(Loading)
链接(Linking)
初始化(Intialization)
2.1 装载
类装载器(Class Loader)读取class文件,生成对应的二进制数据并将其存储在方法区中(method Area)。
对于每个class文件,JVM都会存储如下信息:
① 装载类的完全限定名(Fully qualified name)和他们的直接父类
② class文件是否关联于另一个类或者接口或者枚举
③ 修饰符,变量和方法信息等等
装载class文件后,JVM会在堆区中创建一个Class类型来代表这个文件的类信息。是的,这个Class类型就是我们平常说的在java.lang包中预定义的那个Class。具体怎么用这个Class类型,请参考相关文档。注意,对于每一个class文件,只会有一个Class对象被创建,是一对一的关系。
2.2 链接
链接阶段主要是进行验证(Verification),准备(preparation),和解析(resolution)
① 验证:它主要是确保每一个class文件的正确性,如class文件的格式是否符合标准?是否由有效的编译器生成?如果验证失败,我们将会收到java.lang.VerifyError的运行时异常
② 准备:JVM为类变量分配存储空间,并且将他们初始化为默认值。
③ 解析:主要是用来将符号引用替换为直接引用。通过搜索方法区来找到对应定位需要引用的实体。
2.3 初始化
在这个阶段,所有的静态变量都会初始化为我们在代码中定义的值。执行的顺序是:在单个类中,从上到下,在类层次中,由父类到子类。
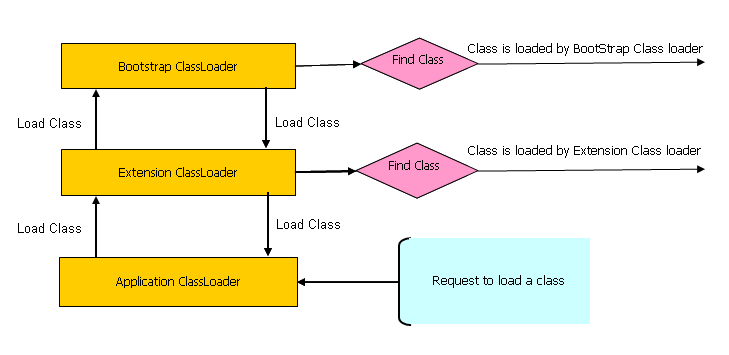
接下来就轮到具体的类装载器了。一般而言,分为三种类装载器
① 根类装载器 (Bootstrap class loader):每一个JVM都必须有一个根类装载器,用来装载可信任的类,例如它会装载位于JAVA_HOME/JRE/lib中的java api类。这个路径也常被称作根目录(bootstrap path)。注意,根类装载器不是由JAVA语言编写,而是由本地语言(Native languages)例如C和C++编写而成。
② 扩展装载器(Extension class loader):它是根装载器的子装载器。主要用于装载位于JAVA_HOME/jre/lib/ext(也叫作扩展路径:Extension path)的各种类,或者也可以由系统属性java.ext.dirs来指定加载路径。这个装载器是由JAVA语言编写,实现类为sun.misc.Launcher$ExtClassLoader。
③ 系统/应用类装载器(System/Application class loader): 它是扩展装载器的子装载器。主要负责加载位于应用类路径(application class path)下的类文件。这个是由我们自己指定。默认情况下,会使用环境变量的值,该环境变量记录了java.class.path的值。该装载器也是由JAVA语言编写而成,实现类为sun.misc.Launcher$ExtClassLoader。
需要特别说明的是,JVM采取了一种委托-分层(Delegation-Hierarchy)机制来加载类文件。系统类装载器将装载请求委托给扩展类装载器,然后再交给根类装载器。如果在根类路径下面发现了需要的类文件,那么就直接加载,否则,会将加载请求回传给扩展类装载进行查找,如果还找不到就回传给系统类装载器。如果连系统类装载器都无法加载,那么我们就会得到一个运行时错误:java.lang.ClassNotFoundException。
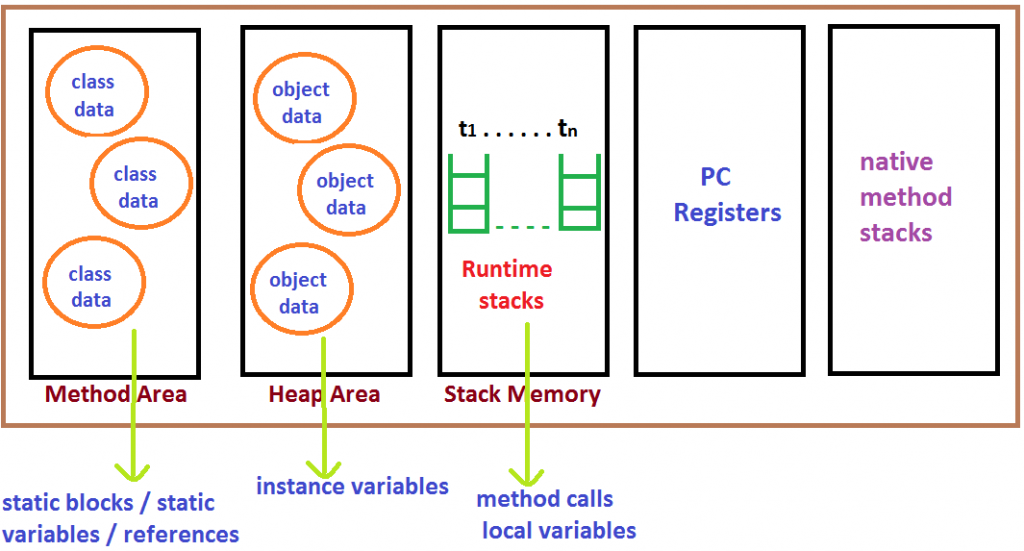
三、JVM的内存分布
JVM内存的分布情况也是我们需要重点关注的。主要分为如下几类:
① 方法区(Method Area):在方法区中,包括所有类层次的信息如类名,直接父类名,类方法,成员变量,静态变量等等。每一个JVM只能拥有一个方法区,且方法区是一个共享资源,可供其他资源访问调用。
② 堆区(Heap Area):所有的对象都存储在堆区中。每一个JVM也只能有一个堆区。它也具有共享性。
③ 栈区 (Stack Area):对于每一个线程,JVM都会在此处创建一个运行时栈。每一个栈块又叫做活动记录/栈帧(activation record/stack frame),它们都记录了方法调用的情况,所有属于该方法的局部变量都存于对应的栈帧中。线程结束后,栈帧会被销毁。栈区不是共享资源,它由对应的线程独享。
④ PC寄存器(PC registors): 用于存储线程的当前的执行指令的地址。很明显,每个线程都有属于自己的PC寄存器。
⑤ 本地方法栈(Native method stacks):对于每个线程,都会分别创建一个本地方法栈。主要用于存储本地方法的调用情况。
四、执行引擎(Execution Engine)
执行引擎用来执行class文件(字节码)。执行器一行一行的读取字节码,结合当前内存区存储的各种数据和信息,执行相关指令。执行器也可以分为三个部分
① 解释器(Interpreter):用来逐行解释字节码并执行。缺点就是如果同一个方法调用多次,每一次都还是需要进行解释,效率低下浪费资源。
② 实时编译器 (JIT- Just In Time Compiler):主要用来提升解释器的执行效率。它会将整个的字节码进行编译并将其转化为本地码(Native Code)。如此一来,每当解释器看到对应的方法调用时,都可以直接使用JIT提供的本地码而不需要再次进行解释。从而也提升了效率。
③ 垃圾回收器(Garbage Collector):主要用于销毁没有引用的对象。
五、常见问题
5.1 上文中出现的“本地方法”到底是个什么东西?
这其实和一个关键的概念有关:JNI。JNI也叫java本地接口,该接口能够与本地方法(Native Method Libraries)库进行交互,为程序的执行提供本地库(如C/C++)的支持。它能够让JVM调用C/C++库或者被C/C++库调用。后者主要是在硬件特性比较特殊的情况下使用。
本地方法库主要是指本地库(C/C++)的集合,执行器会用到这些库。
native这个词其实也是JAVA语言的关键词之一。一般情况下用的比较少。但是它有如下几个作用:
It allows you to:
-
- call a compiled dynamically loaded library (here written in C) with arbitrary assembly code from Java
- and get results back into Java
This could be used to:
-
- write faster code on a critical section with better CPU assembly instructions (not CPU portable)
- make direct system calls (not OS portable)
with the tradeoff of lower portability.
5.2 静态变量会被垃圾回收器回收吗?
当类被加载后,静态变量属于上文的方法区,很明显,他不会被回收。但是,除非用来加载这个类的类加载器被回收了,那这个静态方法也就会被回收。如此,一般情况下就可以理解为never。也请注意,根类装载器是不会被回收的。
5.3 Class.forName都干了些啥?
它啊,就是用于加载类啊,并且初始化静态变量。
主要是有很多人问到在老版本的jdbc为啥需要Class.forName("oracle.jdbc.driver.OracleDriver")这个东东。
注意啊,这个是老版本的需求,现在已经不用了:
In previous versions of JDBC, to obtain a connection, you first had to initialize your JDBC driver by calling the method
Class.forName. This methods required an object of typejava.sql.Driver. Each JDBC driver contains one or more classes that implements the interfacejava.sql.Driver.
...
Any JDBC 4.0 drivers that are found in your class path are automatically loaded. (However, you must manually load any drivers prior to JDBC 4.0 with the methodClass.forName.)
说白了用Class.forName就是保证在不用显式import的情况下来使用对应的类,也即是说,可以在classpath下不存在相关类文件时,仍旧可以构建项目,加载指定类文件。