编程基础与二进制
一、编程基础
函数调用的基本原理:
函数调用中的问题:
1)参数如何传递?
2)函数如何知道返回什么地方?
3)函数结果如何传递给调用方?
解决思路是使用内存来函数调用过程中需要的数据,这种内存叫做栈。栈是一种先进后出的内存,栈底内存地址最高,栈顶最低。
另外,函数返回值一般使用一种特殊的栈--CPU内的存储器来存储。main函数的相关数据放在栈底,每调用一次函数,都会将函数
的相关数据入栈,调用结束就出栈。举个例子:
public class Sum { public static int sum(int a, int b) { int c = a + b; return c; } public static void main(String[] args) { int d = Sum.sum(1, 2); System.out.println(d); } }
1.调用Sum.sum()方法前栈的情况:
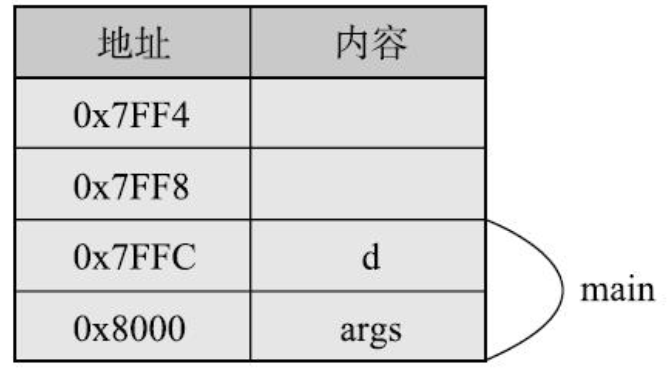
2.在程序执行到sum()函数内部,返回前,栈的情况:
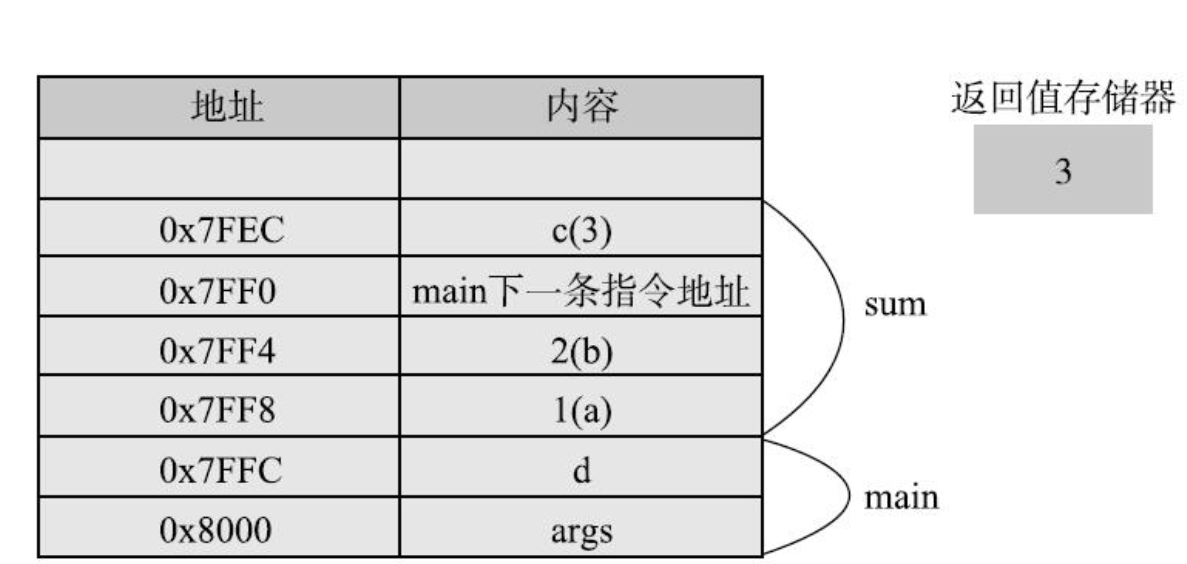
函数的参数和函数内定义的变量,都分配在栈中,这些变量在函数被调用的时候才分配,
而且在调用结束后就被释放了,但这种说法主要针对基本数据类型。
数组和对象的内存分配:
public class ArrayMax { public static int max(int min, int[] arr) { int max = min; for(int a : arr) { if (a > max) { max = a; } } return max; } public static void main(String[] args) { int[] arr = new int[]{2, 3, 4}; int ret = max(0, arr); System.out.println(ret); } }
在程序执行到max函数调用return语句之前:
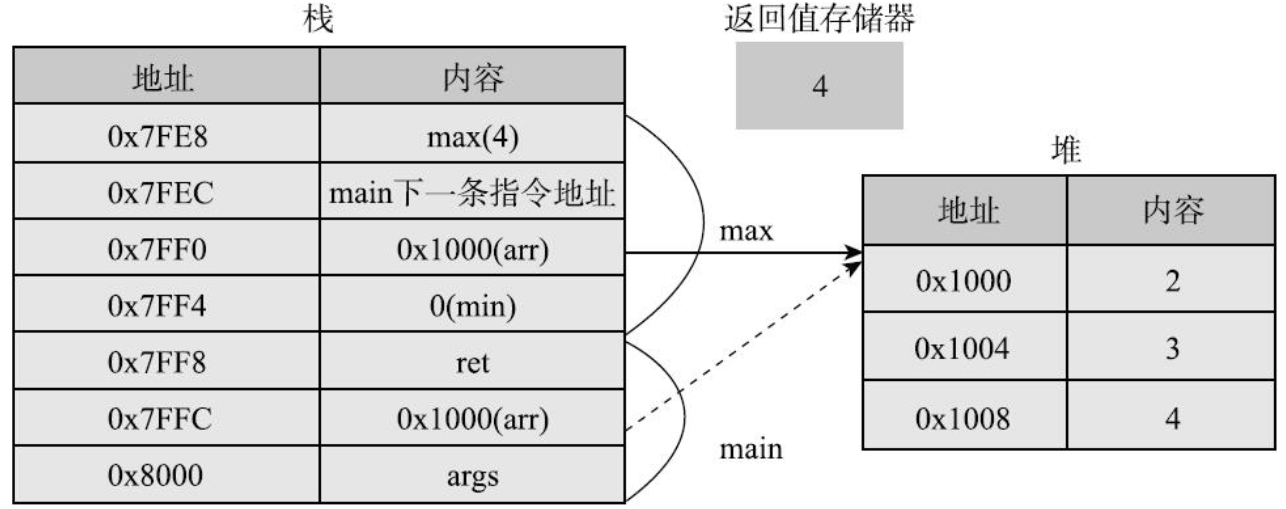
当main函数执行结束,栈空间没有变量指向堆中的内容时,Java系统会自动进行垃圾回收,释放该空间。
二、理解数据背后的二进制
整数的二进制表示:
二进制使用最高位表示符号位,用1表示负数,用0表示正数。但哪个高位?
整数有4种类型byte,short,int,long分别占用1,2,4,8个字节,即分别占用
8,16,32,64位,每种类型的符号位都是最左边的那一位。
但是,负数的表示不是简单的把最高位变为1。而是使用补码表示法来表示。
补码:就是在原码的基础上取反然后加上1。例如:
1)-1:1的原码是0000 0001,取反为1111 1110再加上1后是1111 1111。
2)-2:2的原码是0000 0010,取反为1111 1101再加上1后是1111 1110。
3)-127:127的原码是0111 1111 ,取反为1000 0000再加上1后是1000 0001。
给定一个负数的二进制表示,想要知道它的十进制值,可以采用相同的补码运算。
比如-2,原码为1111 1110,取反为0000 0001,再加上1,得到0000 0010,就是
十进制的2。
思考:为什么会采用补码再加1这种奇怪的方式表示负数?(提示:计算机只能做加法)。
整数的十六进制表示:
为什么要使用十六进制?因为二进制写出来一长串啊,弟弟。
用法:可以使用十六进制直接写数字常量,在数字前加0x就行了。10到15用A到F表示。
注意:Java7以后也可以使用二进制数字常量,在数字前面加0b或者0B就行了。
位运算
1.移位:
1)左移:操作符为<<,向左移动,右边低位补0,高位舍弃。左移1位,相当于该数十进制乘以2(同时适用于正数和负数)。
2)无符号右移:操作符>>>,向右边动,右边舍弃掉,左边补0,相当于十进制除以2(仅适用于正数)。
3)有符号右移:操作符>>,向右边动,右边舍弃掉,左边补什么取决于原来最高位是什么,原来
是1就补1,原来是0就补0,右移1位相当于除以2(适用于正负数)。
2.按位与---&:
先将两个数据转化为二进制数,然后按位进行与运算,同为1结果为1,其它情况结果为0
用途:
1)清零
2)取一个数种的指定位
3)判断奇偶性:任意数与1取位与,结果1的为奇数
3.按位或-----|
先将两个数据转化为二进制数,然后进行按位或运算,只要有一个是1结果为1,不然结果为0;
用途:
4.按位异或----^
先将两个数据转化为二进制数,然后进行按位异或运算,只要位不同结果为1,不然结果为0
用途:
二进制、十进制与十六进制之间的转换
1)二进制转十进制
1010 = 0*20 + 1*21 + 0*22 + 1*23
2)二进制转十六进制
从左到右4个数为一个单位,不足4位补0:
0010 1100 ----> 2 22+23 ----> 2C
3)十进制转二进制
除以2取余法:
123 ----- 1
61 ----- 1
30 ----- 0
15 ----- 1
7 ----- 1
3 ----- 1
1 ----- 1
0
结果为: 11 1101
4)十进制转十六进制
除16取余法:
188
11 ---- 12
0 ---- 11
AB
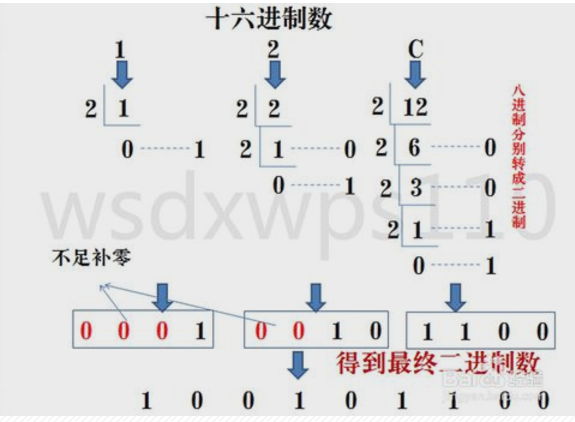
5)十六进制转二进制
十六进制数通过除2取余法,得到二进制数,对每个十六进制为4个二进制,不足时在最左边补零。
6)十六进制转十进制
AB = 11*161 + 12*160
小数的二进制表示:
小数计算为什么会出错?
实际上,不是运算本身会出错而是计算机根本就没办法精确地表示很多数。
比如0.1,其实这跟十进制不能精确表示1/3是一个道理。二进制只能表示
那些可以表述为2的多次方和的数。
字符的编码与乱码:
编码有两大类:一是非Unicode编码,一类是Unicode编码。
非Unicode编码:
1)ASCII:规定了0~127的每个数字代表的意义。
2)其他:ISO 8859-1,Windows-1252,GB2312,GBK,GB18030,Big5
其中ASCII是基础,其他编码方式兼容ASCII。
Unicode编码:
Unicode主要做了一件事,就是给世界上所有字符分配了唯一的数字编号。
但是要注意,它并没有规定这些数字编号怎么对应到具体的二进制表示,这与其他的编码不同,
具体怎么对应是由UTF-32,UTF-16,UTF-8这几种编码方案确定的。具体对应方式:
1)UTF-32:字符编号的整数二进制形式,4个字节。缺点:浪费空间。
2)UTF-16:常用字符集用两个字节表示,增补字符集用4个字节表示。
3)UTF-8:使用变长字节表示,每个字符使用的字节个数与其Unicode编号相关,字节数1-4个不等(小于128的与ASCII一样)。
乱码的原因:
1)解析错误
2)在解析错误的基础上进行了编码转换
char的真正含义:
在Java内部进行字符处理时,采用的是UTF-16BE。
char本质上是一个固定占用两个字节的无符号正整数,这个正整数对应Unicode编号,
用于表示那个Unicode编号表示的字符。char的赋值方式:
char a = 'A'; char b = '唐'; char c = 23235; char d = 0x66; char e = 'u9a6c';
直接写字符常量的时候应该注意文件的编码,比如,GBK编码的源码文件
按UTF-8打开,字符会变成乱码,赋值的时候是按照当前的编码解读方式
,将这个字符形式对应的Unicode编号赋值给变量。