前言:
Ambari是apache下面的开源项目,主要通过web UI方式对Hadoop集群进行统一创建和管理,以节省Hadoop集群的运维成本。本文通过安装过程中的截图简要介绍一下相关步骤供需要的朋友参考。
系统环境说明:
centos6
安装用户:
root
# 查询当前系统信息
$ uname -a
Linux dev7 2.6.32-431.el6.x86_64 #1 SMP Fri Nov 22 03:15:09 UTC 2013 x86_64 x86_64 x86_64 GNU/Linux
# 手动添加yum仓库地址
PART I:yum安装
$ yum install -y ambari-server
$ ambari-server setup

# 启动server服务
$ ambari-server start
访问部署的主机 http://hostname:8080/ 并使用默认账号秘密登录 admin:admin
PART II:通过WEB方式创建集群
step1:创建并填写集群相关基础信息
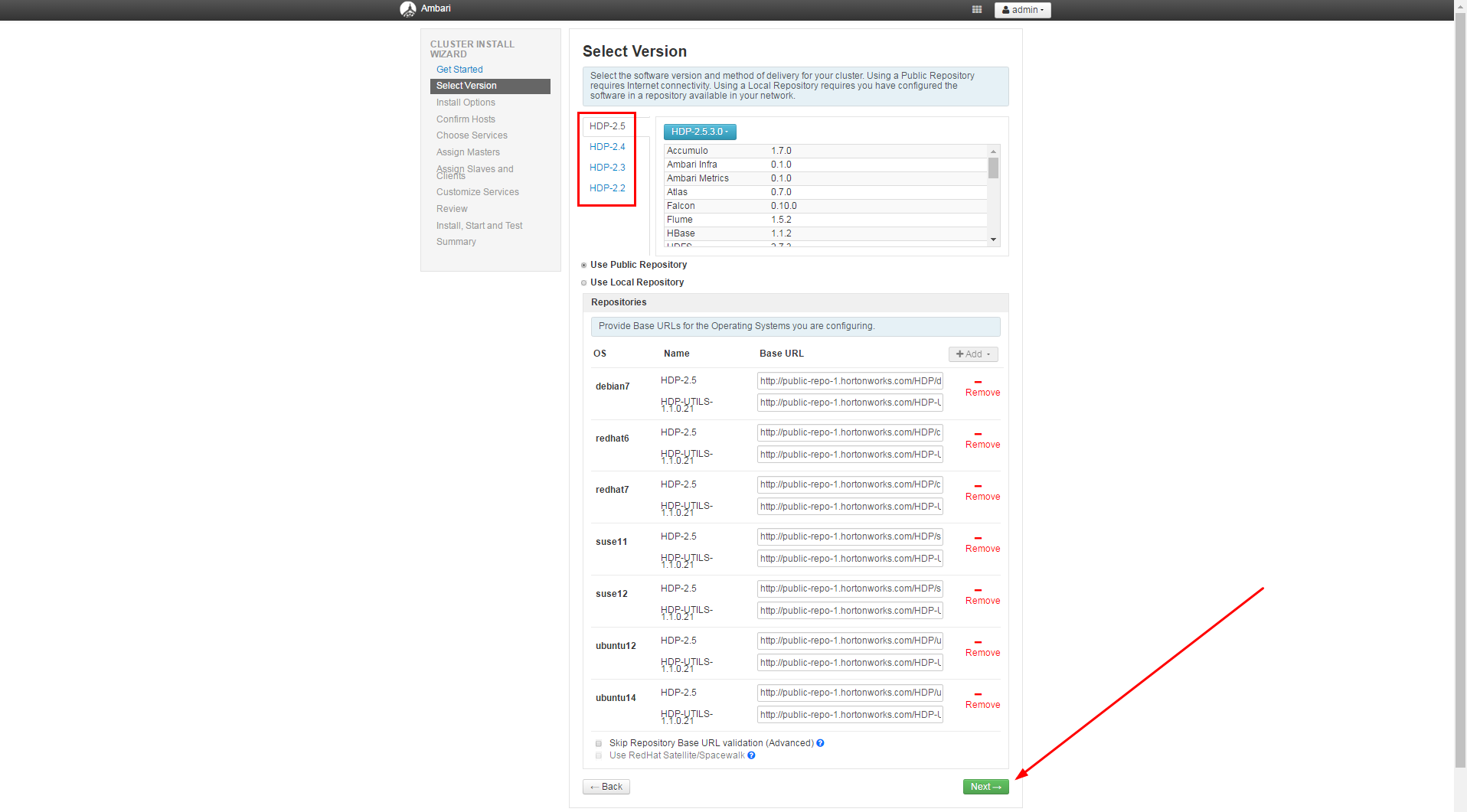
step2: 选择相关组件的版本
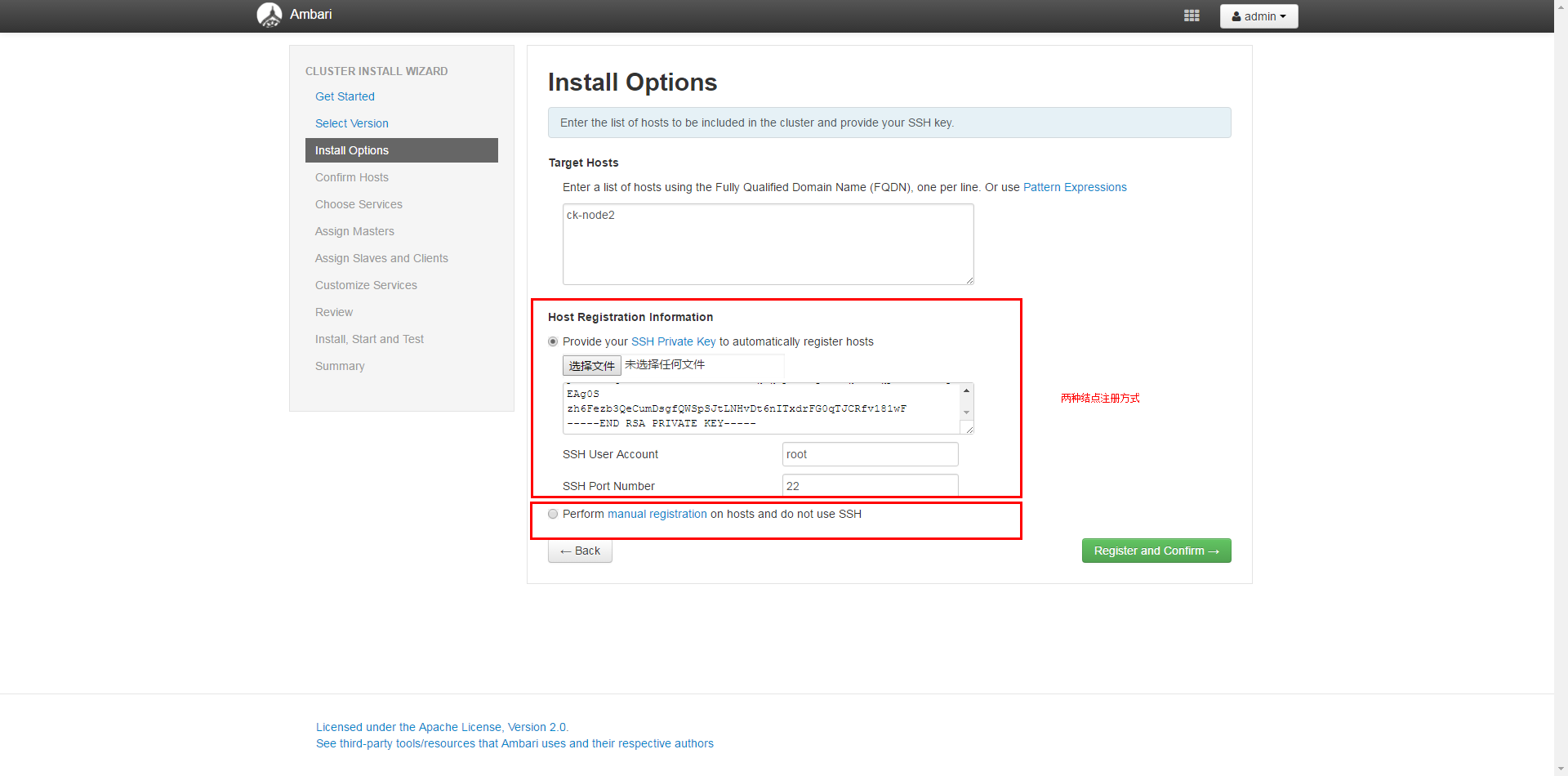
step3:主机结点注册与验证

step4: 选择各个结点的Hadoop组件及服务后点击确定

因配置服务时需要一些数据库验证信息,初始测试阶段可参考以下配置信息:
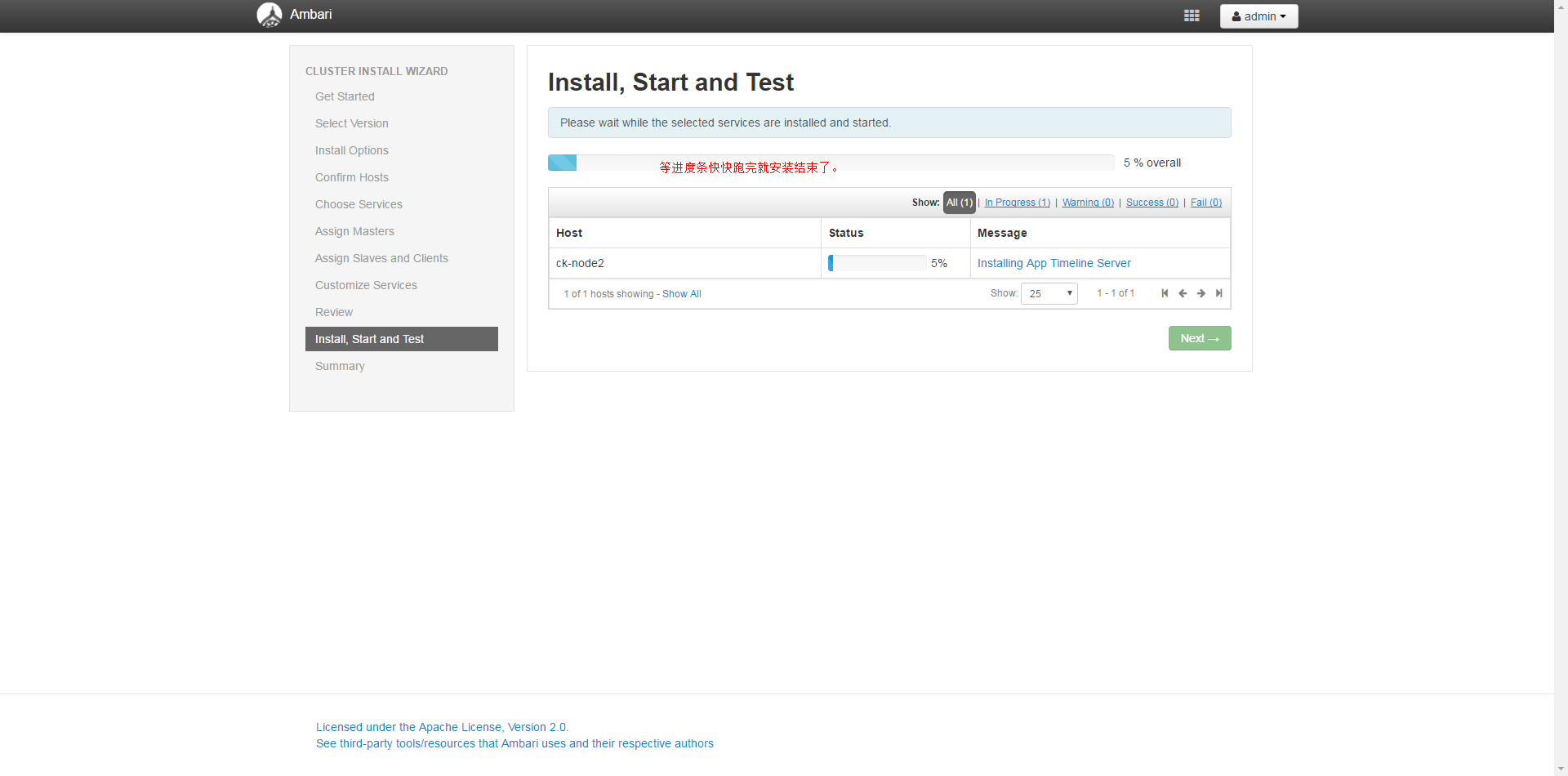
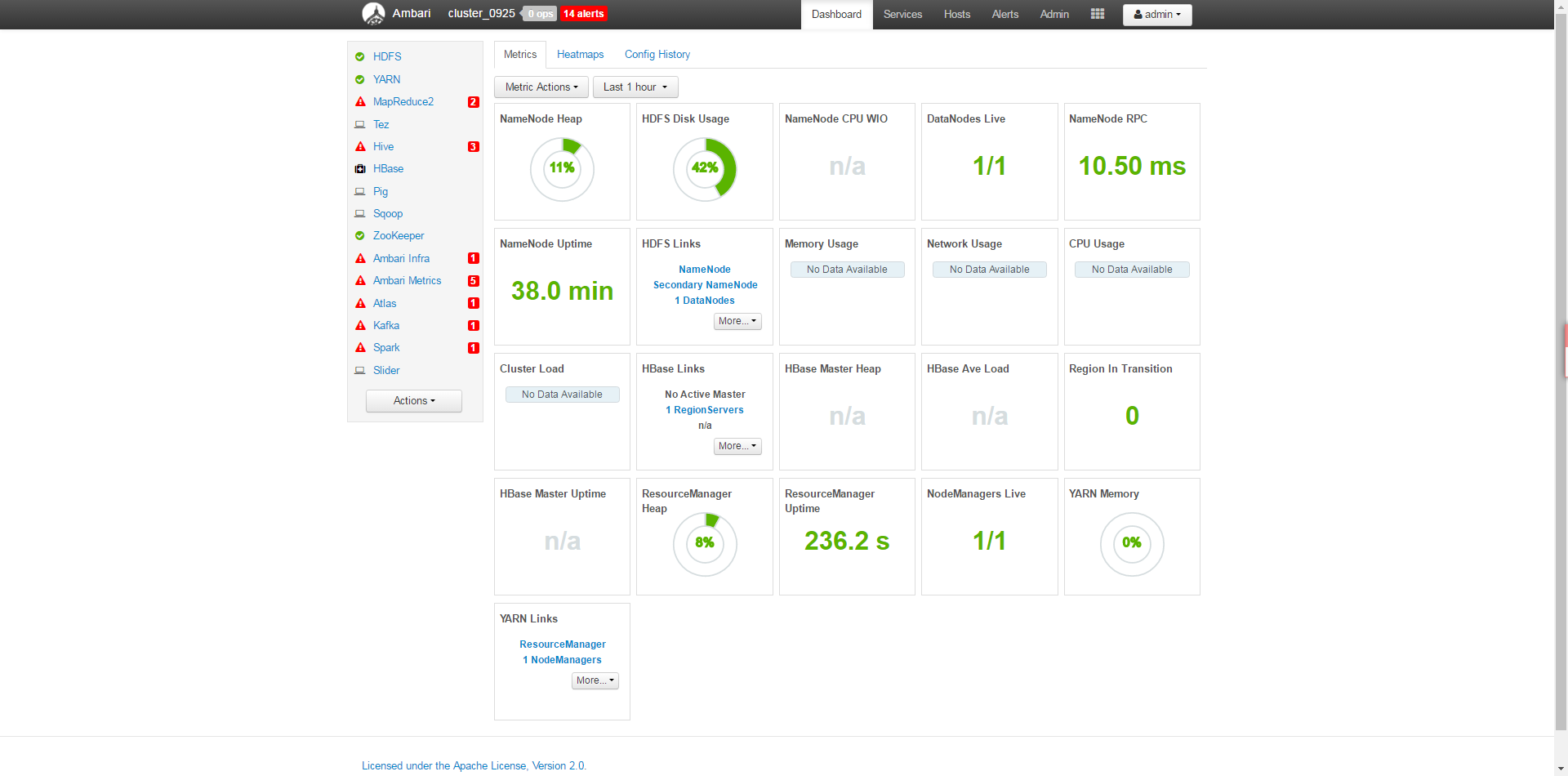
集群初始化成功之后启动HDFS和YARN服务(依赖于Zookeeper服务)可看到如下Ambari的可视化界面
通过访问 http://hostname://8088 和 http://hostname:50070 可查看对应的服务web界面
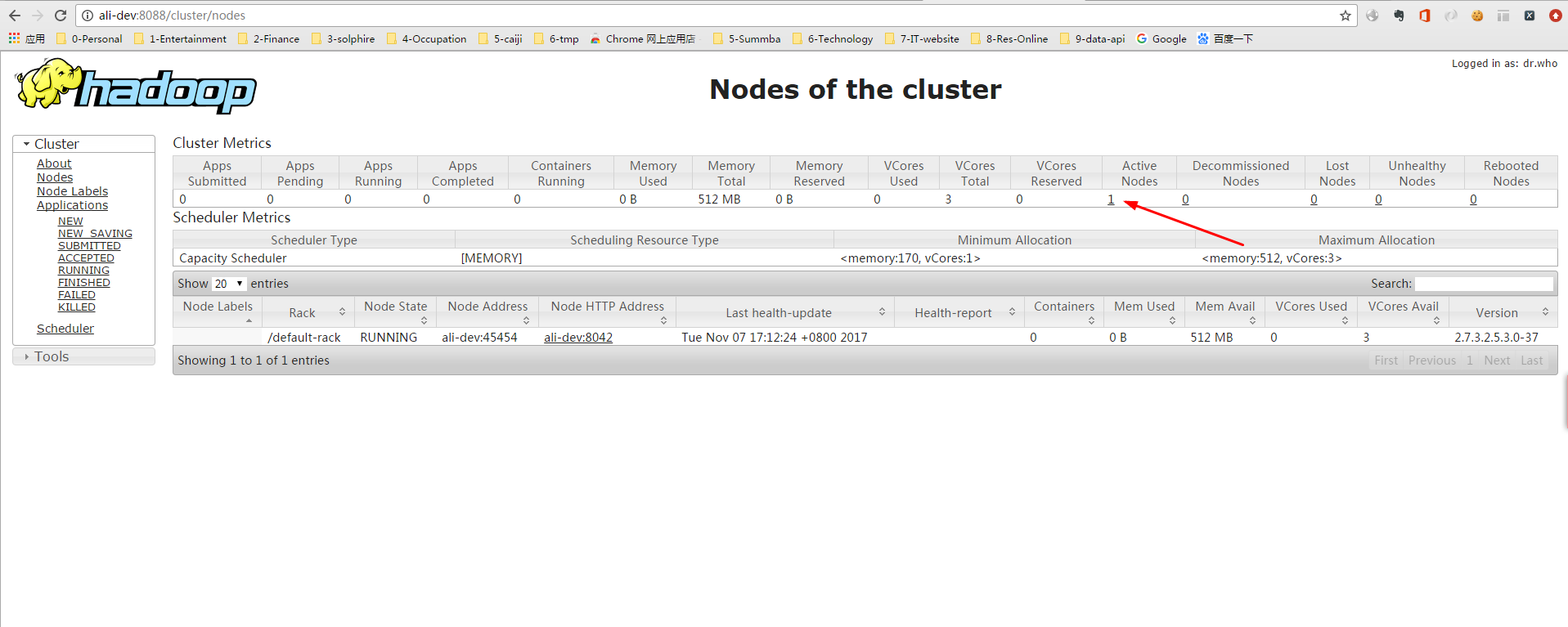
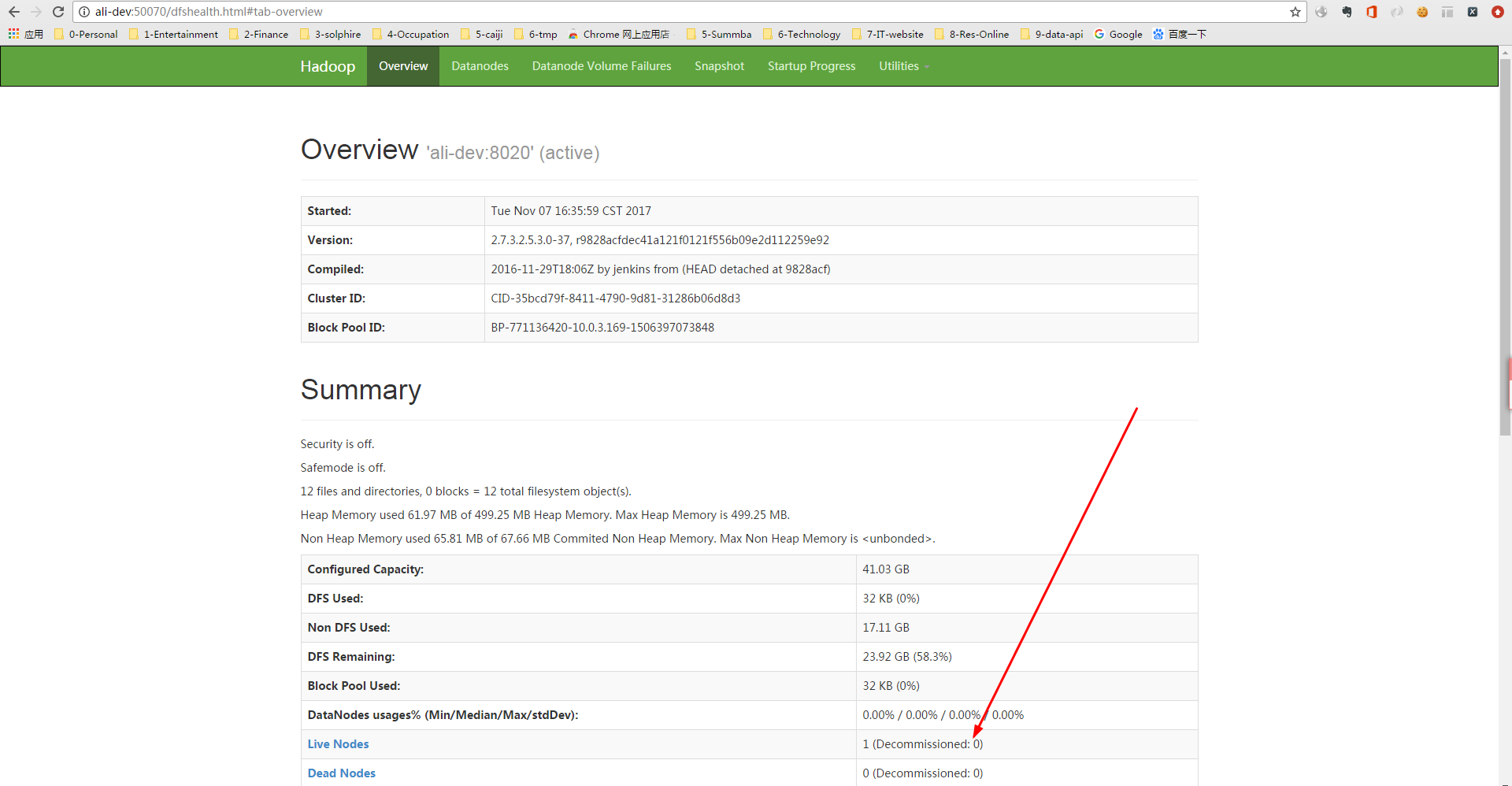
集群结点默认的安装目录:
$ ls /usr/hdp/current
集群服务运行式默认的日志目录
$ ls /var/log/hadoop-yarn/
注意:
若出现结点注册失败,可通过配置免密方式登录主机
$ ssh-keygen -t rsa $ cat ~/.ssh/id_rsa.* >> ~/.ssh/authorized_keys $ chmod 600 ~/.ssh/authorized_keys
附:
Ambari官网还附有源码自编译的安装方式,详细请参考 https://cwiki.apache.org/confluence/display/AMBARI/Installation+Guide+for+Ambari+2.6.0