Hadoop
简介
Hadoop 是一个由 Apache 基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop 的框架最核心的设计就是: HDFS 和 MapReduce。 HDFS 分布式文件系统为海量的数据提供了存储,则 MapReduce 为海量的数据提供了计算。
Hadoop核心
分布式存储
- 在大量数据需要进行存储的时候如果全部存储到一台服务器 存储效率非常低
- 通过文件系统存储数据时,感觉不到是存储到不同的服务器上的。当读取数据时,感觉不到是从不同的服务器上读取。
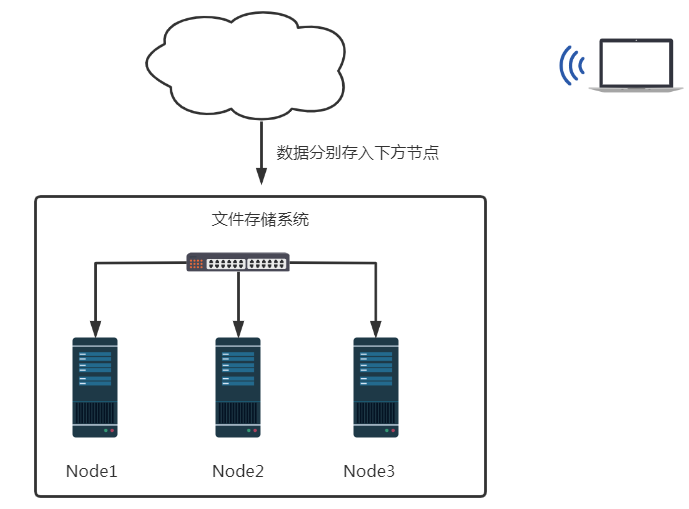
分布式计算
- 在第一阶段分别从不同阶段读取数据的单词数
- 将第一阶段读取的数据进行汇总
组件
命名空间
在分布式存储系统中,分散在不同节点中的数据可能属于同一个文件,为了组织众多的文件,把文件可以放到不同的文件夹中,文件夹可以一级一级的包含。我们把这种组织形式称为命名空间(namespace)。命名空间管理着整个服务器集群中的所有文件。命名空间的职责与存储真实数据的职责是不一样的。
主从节点
主节点负责管理文件系统的文件结构,从节点负责存储真实的数据,称为主从式结构(master-slaves)。用户操作时,也应该先和主节点打交道,查询数据在哪些从节点上存储,然后再从 从节点读取。在主节点,为了加快用户访问的速度,会把整个命名空间信息都放在内存中,当存储的文件越多时,那么主节点就需要越多的内存空间。
blcok
在从节点存储数据时,有的原始数据文件可能很大,有的可能很小,大小不一的文件不容易管理,那么可以抽象出一个独立的存储文件单位,称为块(block)
容灾
数据存放在集群中,可能因为网络原因或者服务器硬件原因造成访问失败,最好采用副本(replication [ˌreplɪ'keɪʃn])机制,把数据同时备份到多台服务器中,这样数据就安全了,数据丢失或者访问失败的概率就小了。
名称解释
- Hadoop: Apache 开源的分布式框架
- HDSF: Hadoop 的分布式文件系统。
- NameNode: Hadoop HDFS 元数据主节点服务器,负责保存 DataNode 文件存储元数据信息,这个服务器是单点的。 Namenode 记录着每个文件中各个块所在的数据节点的位置信息
- DataNode: Hadoop 数据节点,负责存储数据
- JobTracker: Hadoop 的 Map/Reduce 调度器,负责与 TaskTracker 通信分配计算任务并跟踪任务进度,这个服务器也是单点的
- TaskTracker: Hadoop 调度程序,负责 Map,Reduce 任务的启动和执行。 [tɑ:sk] 作业任务
分布式计算
过程
对数据进行处理时,我们会把数据读取到内存中进行处理。如果我们对海量数据进行处理,比如数据大小是 100GB,我们要统计文件中一共有多少个单词。要想把数据都加载到内存中几乎是不可能的,称为移动数据
那么是否可以把程序代码放到存放数据的服务器上哪?因为程序代码与原始数据相比,一般很小,几 乎可以忽略的,所以省下了原始数据传输的时间了。现在,数据是存放在分布式文件系统中, 100GB 的数据可能存放在很多的服务器上,那么就可以把程序代码分发到这些服务器上,在这些服务器上同时执行,也就是并行计算,也是分布式计算。这就大大缩短了程序的执行时间。我们把程序代码移动到数据节点的机器上执行的计算方式称为移动计算。
分布式计算需要的是最终的结果,程序代码在很多机器上并行执行后会产生很多的结果,因此需要有一段代码对这些中间结果进行汇总。 Hadoop 中的分布式计算一般是由两阶段完成的。 第一阶段负责读取各数据节点中的原始数据,进行初步处理,对各个节点中的数据求单词数。然后把处理结果传输到第二个阶段,对中间结果进行汇总,产生最终结果,求出 100GB 文件总共有多少个单词
MapReduce
MapReduce 是一种编程模型,用于大规模数据集(大于 1TB)的并行运算。概念"Map(映射) "和"Reduce(归约) ",和它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个 Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组
任务节点
- 主节点称为作业节点(jobtracker)
- 从节点称为任务节点(tasktracker)
- 在任务节点中,运行第一阶段的代码称为 map 任务(map task),运行第二阶段的代码称为reduce 任务(reduce task)
搭建Hadoop
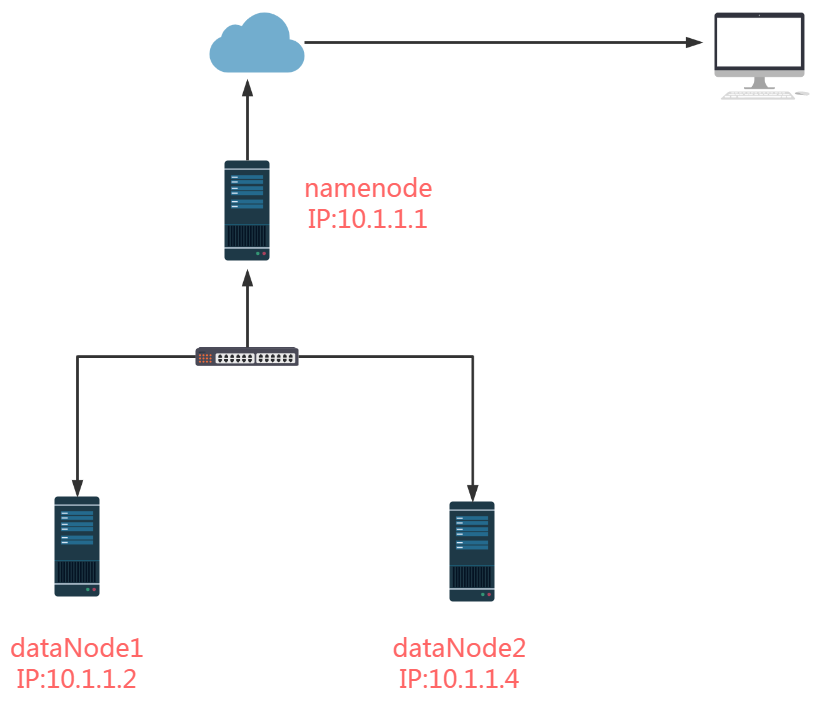
环境架构
| 主机名 | IP | 角色 |
|---|---|---|
| namenode | 10.1.1.1/24 | 主节点 |
| datanode1 | 10.1.1.2.24 | 数据节点 |
| datanode2 | 10.1.1.4.24 | 数据节点 |
基础环境搭建
配置DNS
[root@namenode ~]# vim /etc/hosts
10.1.1.1 namenode.cn
10.1.1.2 datanode1.cn
10.1.1.4 datanode2.cn
[root@namenode ~]# scp /etc/hosts root@datanode1:/etc/
[root@namenode ~]# scp /etc/hosts root@datanode2:/etc/
配置Hadoop专有用户
# 为了保障,在其它服务器上创建的 hadoop 用户 ID 保持一致,创建时,尽量把 UID 调大
[root@namenode ~]# useradd -u 8000 hadoop; echo root123 | passwd --stdin hadoop
[root@datanode1 ~]# useradd -u 8000 hadoop; echo root123 | passwd --stdin hadoop
[root@datanode2 ~]# useradd -u 8000 hadoop; echo root123 | passwd --stdin hadoop
配置SSH
# 生成 root 用户的公钥和私钥
[hadoop@namenode ~]# ssh-keygen
# 导入公钥到其他 datanode 节点认证文件
[hadoop@namenode ~]# ssh-copy-id root@datanode1.cn
[hadoop@namenode ~]# ssh-copy-id root@datanode2.cn
[hadoop@namenode ~]# ssh-copy-id hadoop@datanode1.cn
[hadoop@namenode ~]# ssh-copy-id hadoop@datanode2.cn
[hadoop@namenode ~]# ssh-copy-id hadoop@namenode.cn
配置jdk
# 安装
[root@namenode ~]# rpm -ivh jdk-8u191-linux-x64.rpm
# 查看安装位置
[root@namenode ~]# rpm -pql /root/jdk-8u161-linux-x64.rpm
# 查看版本
[root@namenode ~]# java -version
# 复制到datanode节点 让其配置jdk
[root@namenode ~]# scp jdk-8u191-linux-x64.rpm root@datanode1.cn:/root
[root@namenode ~]# scp jdk-8u191-linux-x64.rpm root@datanode2.cn:/root

配置hadoop
初始化环境
# 切换到hadoop
[root@namenode ~]# su - hadoop
# 解压
[hadoop@namenode ~]$ tar -xvf hadoop-3.0.0.tar.gz
创建工作目录
[hadoop@namenode ~]$ mkdir -p /home/hadoop/dfs/name /home/hadoop/dfs/data /home/hadoop/tmp
修改配置文件
# 进入配置文件
[hadoop@namenode ~]$ cd hadoop-3.0.0/etc/hadoop/
# 配置java环境变量
[hadoop@namenode hadoop]$ cp hadoop-env.sh hadoop-env.sh.bak
[hadoop@namenode hadoop]$ vim hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_191-amd64
# 配置hadoop运行框架
# 该文件是 yarn 框架运行环境的配置,同样需要修改 java 虚拟机的位置
[hadoop@namenode hadoop]$ cp yarn-env.sh yarn-env.sh.bak
[hadoop@namenode hadoop]$ vim yarn-env.sh
yarn-env.sh > hadoop-env.sh > hard-coded defaults
# 指定访问 hadoop web 界面访问路径
[hadoop@namenode hadoop]$ cp core-site.xml core-site.xml.bak
[hadoop@namenode hadoop]$ vim core-site.xml
<configuration>
<property>
# 定义默认文件系统主机和端口
<name>fs.defaultFS</name>
<value>hdfs://namenode.cn:9000</value>
</property>
<property>
# 定义I/O缓冲区大小
<name>io.file.buffer.size</name>
<value>13107</value>
</property>
<property>
# 定义临时文件位置
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
# 名称节点和数据节点的存放位置、文件副本的个数
[hadoop@namenode hadoop]$ cp hdfs-site.xml hdfs-site.xml.bak
[hadoop@namenode hadoop]$ vim hdfs-site.xml
<configuration>
<property>
# 定义HDFS对应的HTTP服务器地址和端口
<name>dfs.namenode.secondary.http-address</name>
<value>namenode.cn:9001</value>
</property>
<property>
# 定义DFS的名称节点在本地文件系统的位置
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/dfs/name</value>
</property>
<property>
# 定义DFS的数据节点在本地文件系统的位置
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/dfs/data</value>
</property>
<property>
#每个 Block 有 2 个备份。
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
# 是否通过http协议读取hdfs文件,如果选是,则集群安全性较差
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
# mapreduce 任务的配置
[hadoop@namenode hadoop]$ cp mapred-site.xml mapred-site.xml.bak
[hadoop@namenode hadoop]$ vim mapred-site.xml
<property>
# hadoop使用yarn必须使用yarn
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
# 定义历史服务器的地址和端口,通过历史服务器查看已经运行完的Mapreduce作业记录
<name>mapreduce.jobhistory.address</name>
<value>0.0.0.0:10020</value>
</property>
<property>
# 定义历史服务器web应用访问的地址和端口
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:19888</value>
</property>
# 任务的启动位置
[hadoop@namenode hadoop]$ cp yarn-site.xml yarn-site.xml.bak
[hadoop@namenode hadoop]$ vim yarn-site.xml
<property>
#用户可以自定义一些服务,例如Map-Reduce的shuffle功能就是采用这种方式实现的,这样就可以在NodeManager上扩展自己的服务。
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
# ResourceManager 提供给客户端访问的地址。客户端通过该地址向RM提交应用程序,杀死应用程序等
<name>yarn.resourcemanager.address</name>
<value>namenode.cn:8032</value>
</property>
<property>
# ResourceManager提供给ApplicationMaster的访问地址。ApplicationMaster通过该地址向RM申请资源、释放资源等
<name>yarn.resourcemanager.scheduler.address</name>
<value>namenode.cn:8030</value>
</property>
<property>
# ResourceManager 提供给NodeManager的地址。NodeManager通过该地址向RM汇报心跳,领取任务等
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>namenode.cn:8031</value>
</property>
<property>
# ResourceManager 提供给管理员的访问地址。管理员通过该地址向RM发送管理命令等。
<name>yarn.resourcemanager.admin.address</name>
<value>namenode.cn:8033</value>
</property>
<property>
# ResourceManager对web 服务提供地址。用户可通过该地址在浏览器中查看集群各类信息
<name>yarn.resourcemanager.webapp.address</name>
<value>namenode.cn:8088</value>
</property>
<property>
# yarn库文件
<name>yarn.application.classpath</name>
<value>/home/hadoop/hadoop-3.0.0/etc/hadoop:/home/hadoop/hadoop-
3.0.0/share/hadoop/common/lib/*:/home/hadoop/hadoop-
3.0.0/share/hadoop/common/*:/home/hadoop/hadoop-
3.0.0/share/hadoop/hdfs:/home/hadoop/hadoop-
3.0.0/share/hadoop/hdfs/lib/*:/home/hadoop/hadoop-
3.0.0/share/hadoop/hdfs/*:/home/hadoop/hadoop-
3.0.0/share/hadoop/mapreduce/*:/home/hadoop/hadoop-
3.0.0/share/hadoop/yarn:/home/hadoop/hadoop-
3.0.0/share/hadoop/yarn/lib/*:/home/hadoop/hadoop-3.0.0/share/hadoop/yarn/*
</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>20480</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>4096</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage</name>
<value>95.0</value>
</property>
# 配置数据节点
[hadoop@namenode hadoop]$ cp workers workers.bak
[hadoop@namenode hadoop]$ vim workers
datanode1.cn
datanode2.cn
修改hadoop文件权限
[hadoop@namenode hadoop]$ chown hadoop:hadoop -R /home/hadoop/hadoop-3.0.0
复制hadoop到数据节点
[hadoop@namenode hadoop]$ scp -r /home/hadoop/hadoop-3.0.0 hadoop@datanode1.cn:~/
[hadoop@namenode hadoop]$ scp -r /home/hadoop/hadoop-3.0.0 hadoop@datanode2.cn:~/
[hadoop@datanode1 ~]$ mkdir -p /home/hadoop/dfs/name /home/hadoop/dfs/data /home/hadoop/tmp
[hadoop@datanode1 ~]$ chown hadoop:hadoop -R /home/hadoop/hadoop-3.0.0
[hadoop@datanode2 ~]$ mkdir -p /home/hadoop/dfs/name /home/hadoop/dfs/data /home/hadoop/tmp
[hadoop@datanode2 ~]$ chown hadoop:hadoop -R /home/hadoop/hadoop-3.0.0
启动hadoop
初始化hadoop
[hadoop@namenode bin]$ cd /home/hadoop/hadoop-3.0.0/bin/
# 格式化文件系统
[hadoop@namenode bin]$ ./hdfs namenode -format

启动hdfs
[hadoop@namenode sbin]$ cd /home/hadoop/hadoop-3.0.0/sbin
[hadoop@namenode sbin]$ ./start-dfs.sh
# 查看进程
[hadoop@namenode sbin]$ ps -axu | grep namenode --color

启动分布式计算
# ResourceManager 是 Yarn 集群主控节点,负责协调和管理整个集群(所有NodeManager)的资源。
[hadoop@namenode sbin]$ ./start-yarn.sh
# 查看进程
[hadoop@namenode ~]$ ps -axu | grep resourcemanager --color

启动工作历时服务
[hadoop@namenode sbin]$ ./mr-jobhistory-daemon.sh start historyserver
启动从存储服务
[hadoop@namenode sbin]$ ./hadoop-daemon.sh start datanode
启动资源管理服务
[hadoop@namenode sbin]$ ./yarn-daemon.sh start nodemanager
查看状态
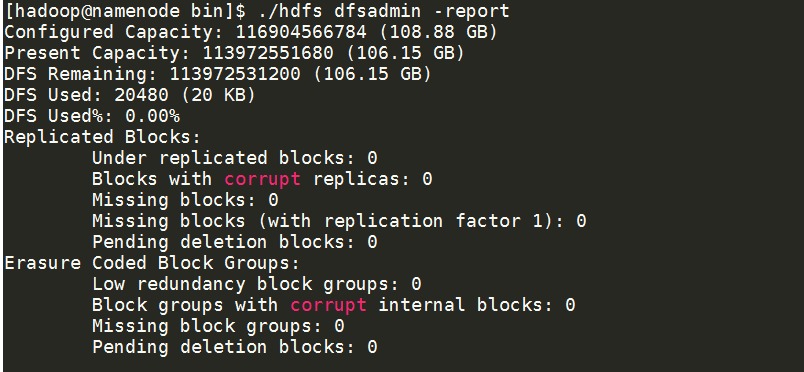
HDFS状态
[hadoop@namenode sbin]$ cd /home/hadoop/hadoop-3.0.0/bin/
[hadoop@namenode bin]$ ./hdfs dfsadmin -report
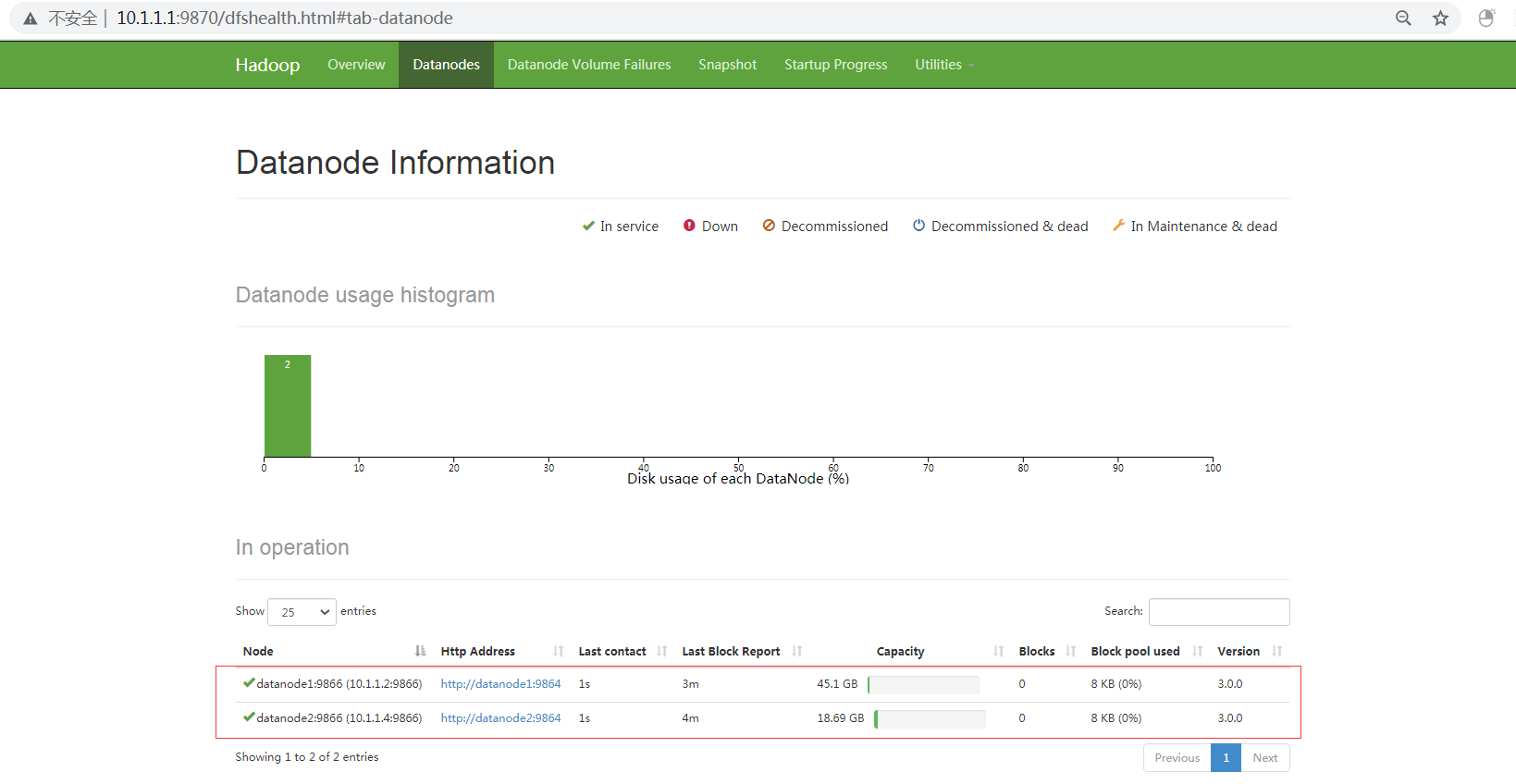
web界面查看HDFS
[hadoop@namenode bin]$ ./hdfs fsck / -files -blocks
执行计算
配置hadoop环境变量
[hadoop@namenode ~]$ su - root
[root@xuegod63 ~]# vim /etc/profile #在文件最后,追加以下内容:
export HADOOP_HOME=/home/hadoop/hadoop-3.0.0
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
[root@namenode ~]# su - hadoop
添加测试数据
[hadoop@namenode ~]$ vim test02.txt
张三
李四
张三
王二麻子
赵家坝
[hadoop@namenode ~]$ vim test02.txt
赵家坝
范冰冰
李晨
赵丽颖
张三
实验验证
[hadoop@namenode ~]$ hadoop fs -ls / #查看 hdfs 目录情况
Found 1 items
drwxrwx--- - hadoop supergroup 0 2018-02-03 18:29 /tmp
[hadoop@xuegod63 ~]$ hadoop fs -mkdir -p /input #在 hdpf 的根目录下,创建 input 目录
[hadoop@xuegod63 ~]$ hadoop fs -put /home/hadoop/test*.txt /input #把 file*.txt # 文件放到 hdfs 的 input 目录下
[hadoop@namenode ~]$ hadoop fs -cat /input/test01.txt

查看单词数量并且汇总
[hadoop@namenode ~]$ hadoop jar /home/hadoop/hadoop-3.0.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.0.jar wordcount /input /test3 # 输出到output文件
# 查看输出的文件
[hadoop@xuegod63 ~]$ hadoop fs -ls /test3
-rw-r--r-- 2 hadoop supergroup 0 2020-09-02 15:45 /test3/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 78 2020-09-02 15:45 /test3/part-r-00000
# 查看结果
[hadoop@namenode ~]$ hadoop fs -cat /test3/part-r-00000
