1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)进行词频统计。
载入数据

创建查表
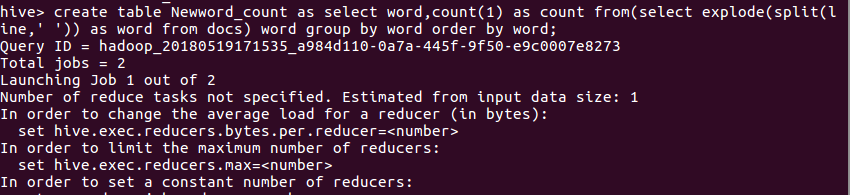
create table Newword_count as select word,count(1) as count from(select explode(split(line,' ')) as word from docs ) word group by word order by word;
查看表是否创建成果
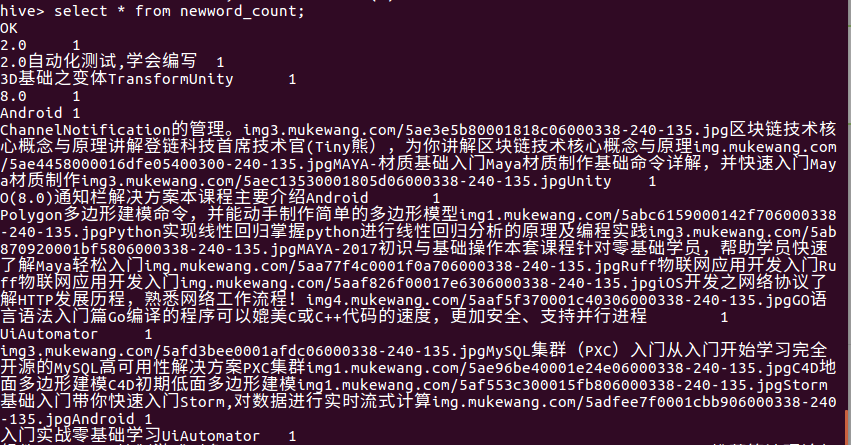
查看结果
2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。
将数据以csv格式上传到hdfs
将文件上传到HDFS上
查看上传成功的文件的前20个数据
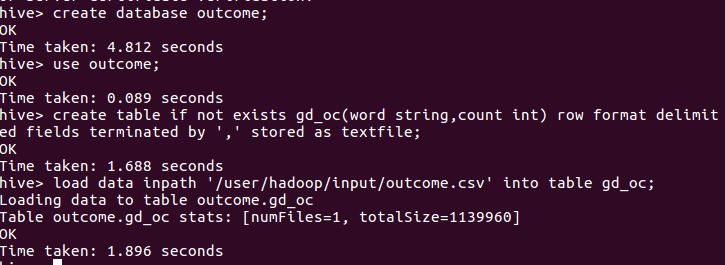
查看数据总条数
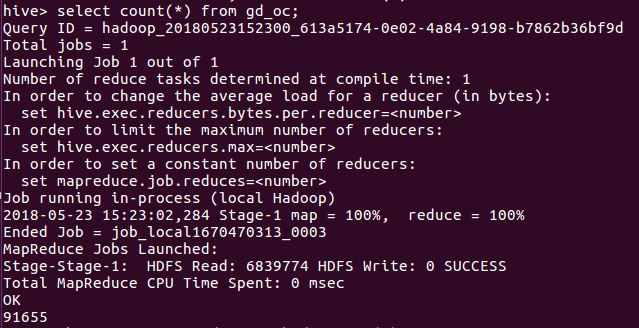
补交作业:
- Python基础
print('你好,{}.'.format(name))
uprint(sys.argv)
库的使用方法:
import ...
from ... import ...
条件语句:
if (abs(pos()))<1:
break
循环语句:
for i in range(5):
while True:
函数定义:
def mygoto(x,y):
def drawjx(r):
综合练习:画一面五星红旗,将代码与运行截图发布博客交作业。
代码:
# -*- coding:utf-8 -*-from turtle import *def mygoto(x,y):
up()
goto(x,y)
down()def drawStar(r):
begin_fill()
for i in range(5):
forward(r)
right(144)
end_fill()
setup(800,600)
bgcolor('red')
color('yellow')
fillcolor('yellow')
mygoto(-335,125)
drawStar(100)
mygoto(-240,200)
drawStar(50)
mygoto(-180,140)
drawStar(50)
mygoto(-180,75)
drawStar(50)
mygoto(-240,30)
drawStar(50)
done()
截图:

- 网络爬虫基础练习
1.利用requests.get(url)获取网页页面的html文件
import requests
newsurl='http://news.gzcc.cn/html/xiaoyuanxinwen/'
res = requests.get(newsurl) #返回response对象
res.encoding='utf-8'
2.利用BeautifulSoup的HTML解析器,生成结构树
from bs4 import BeautifulSoup
soup = BeautifulSoup(res.text,'html.parser')
3.找出特定标签的html元素
soup.p #标签名,返回第一个
soup.head
soup.p.name #字符串
soup.p. attrs #字典,标签的所有属性
soup.p. contents # 列表,所有子标签
soup.p.text #字符串
soup.p.string
soup.select(‘li')
4.取得含有特定CSS属性的元素
soup.select('#p1Node')
soup.select('.news-list-title')
5.练习:
import requests
re=requests.get('http://localhost:63342/bd/test.html?_ijt=i20u1bc6rslg59oa6clor426kh')
re.encoding='utf-8'print(re)print(re.text)
from bs4 import BeautifulSoup
soup = BeautifulSoup(re.text,'html.parser')
取出h1标签的文本
print(soup.h1.text)
取出a标签的链接
print(soup.a.attrs['href'])
取出所有li标签的所有内容
for i in soup.select('li'):
print(i.contents)
取出第2个li标签的a标签的第3个div标签的属性
print(soup.select('li')[1].a.select('div')[2].attrs)
取出一条新闻的标题、链接、发布时间、来源
1.取出一条新闻的标题
print(soup.select('.news-list-title')[0].text)
2.贴链接
print(soup.select('li')[2].a.attrs['href'])
3.发布时间
print(soup.select('.news-list-info')[0].contents[0].text)
4.来源
print(soup.select('.news-list-info')[0].contents[1].text)
截图如下
我所用的html页面符合小练习标准,欢迎复制html,切记只是html
<!DOCTYPE html><html lang="en"><head>
<meta charset="UTF-8">
<title>Simple DOM Demo</title></head><body>
<h1>This is the document body</h1>
<P ID = "p1Node">This is paragraph 1.</P>
<P ID = "p2Node">段落2</P>
<a href="http://www.gzcc.cn/">广州商学院</a>
<li><a href="http://news.gzcc.cn">新闻网</a></li>
<li><a href="http://news.gzcc.cn"><div style="hight:80px">旧闻网</div></a></li>
<li>
<a href="http://news.gzcc.cn/html/2018/xiaoyuanxinwen_0328/9113.html">
<div class="news-list-thumb"><img src="http://oa.gzcc.cn/uploadfile/2018/0328/20180328085249565.jpg"></div>
<div class="news-list-text">
<div class="news-list-title" style="">我校校长杨文轩教授讲授新学期“思政第一课”</div>
<div class="news-list-description">3月27日下午,我校校长杨文轩教授在第四教学楼310室为学生讲授了新学期“思政第一课”。</div>
<div class="news-list-info"><span><i class="fa fa-clock-o"></i>2018-03-28</span><span><i class="fa fa-building-o"></i>马克思主义学院</span></div>
</div>
</a>
</li>
</body></html>
- 获取校园全部新闻
import requestsfrom bs4 import BeautifulSoupfrom datetime import datetimeimport re
#获取点击次数def getClickCount(newsUrl):
newsId = re.findall('\_(.*).html', newsUrl)[0].split('/')[1]
clickUrl = 'http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80'.format(newsId)
clickStr = requests.get(clickUrl).text
count = re.search("hits').html('(.*)');",clickStr).group(1)
return count
# 获取新闻详情def getNewDetail(url):
resd = requests.get(url)
resd.encoding = 'utf-8'
soupd = BeautifulSoup(resd.text, 'html.parser')
title = soupd.select('.show-title')[0].text
info = soupd.select('.show-info')[0].text
time = info.lstrip('发布时间:')[0:19]
dt = datetime.strptime(time, '%Y-%m-%d %H:%M:%S')
if info.find('来源:') > 0:
source = info[info.find('来源:'):].split()[0].lstrip('来源:')
else:
source = 'none'
if info.find('作者:') > 0:
author = info[info.find('作者:'):].split()[0].lstrip('作者:')
else:
author = 'none'
print('链接:'+url)
print('标题:' + title)
print('发布时间:{}'.format(dt))
print('来源:' + source)
print('作者:' + author)
print('***********')
def getListPage(listPageUrl):
res = requests.get(listPageUrl)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
for news in soup.select('li'):
if len(news.select('.news-list-title')) > 0:
# 获取新闻模块链接
a = news.a.attrs['href']
# 调用函数获取新闻正文 getNewDetail(a)
#首页列表新闻
# getListPage('http://news.gzcc.cn/html/xiaoyuanxinwen/')
#计算总页数
resn = requests.get('http://news.gzcc.cn/html/xiaoyuanxinwen/')
resn.encoding = 'utf-8'
soupn = BeautifulSoup(resn.text,'html.parser')
n = int(soupn.select('.a1')[0].text.rstrip('条'))//10+1
for i in range(n,n+1):
pageUrl = 'http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i)
getListPage(pageUrl)
运行结果截图:
爬取简书简单数据:
# -*- coding: UTF-8 -*-import requestsfrom bs4 import BeautifulSoupfrom datetime import datetimeimport reimport jieba
res = requests.get('https://www.jianshu.com/p/7cb27667442a')
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'html.parser')
title = soup.select('.title')[0].text
time = soup.select('.publish-time')[0].text.rstrip('*')
dt = datetime.strptime(time, '%Y.%m.%d %H:%M')
words = soup.select('.wordage')[0].text.lstrip('字数 ')
article = list(jieba.lcut(soup.select('p')[0].text))
print('标题:'+title)print('发布时间:{}'.format(dt))print('字数'+words)print('分词后的正文:')print(article)
4. 用mapreduce 处理气象数据集
cd /usr/hadoop
sodu mkdir qx
cd /usr/hadoop/qx
wget -D --accept-regex=REGEX -P data -r -c ftp://ftp.ncdc.noaa.gov/pub/data/noaa/2017/1*
cd /usr/hadoop/qx/data/ftp.ncdc.noaa.gov/pub/data/noaa/2017
sudo zcat 1*.gz >qxdata.txt
cd /usr/hadoop/qx
#!/usr/bin/env pythonimport sysfor i in sys.stdin:
i = i.strip()
d = i[15:23]
t = i[87:92]
print '%s %s' % (d,t)
#!/usr/bin/env pythonfrom operator import itemggetterimport sys
current_word = None
current_count = 0
word = None
for i in sys.stdin:
i = i.strip()
word,count = i.split(' ', 1)
try:
count = int(count)
except ValueError:
continue
if current_word == word:
if current_count > count:
current_count = count
else:
if current_word:
print '%s %s' % (current_word, current_count)
current_count = count
current_word = word
if current_word == word:
print '%s %s' % (current_word, current_count)
chmod a+x /usr/hadoop/qx/mapper.py
chmod a+x /usr/hadoop/qx/reducer.py
5. hive基本操作与应用
通过hadoop上的hive完成WordCount
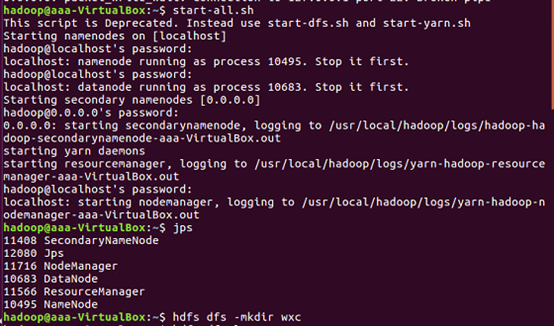
启动hadoop

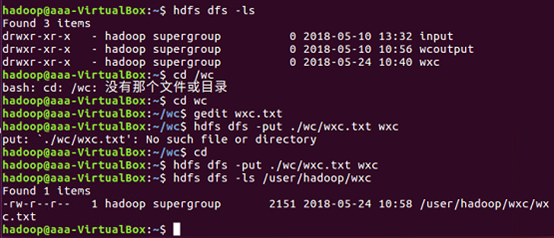
Hdfs上创建文件夹
创建的文件夹是datainput

上传文件至hdfs

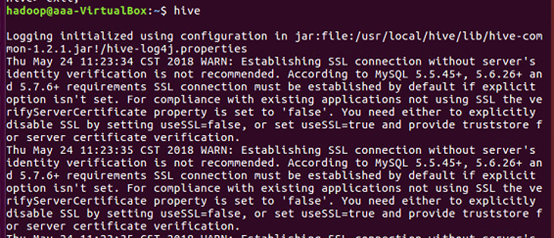
启动Hive
创建原始文档表

导入文件内容到表docs并查看
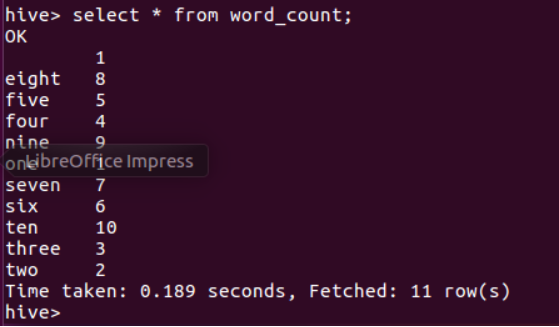
用HQL进行词频统计,结果放在表word_count里

查看统计结果