from sklearn.datasets import load_sample_image
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
china = load_sample_image("china.jpg")
plt.imshow(china)
plt.show()
print(china.shape)
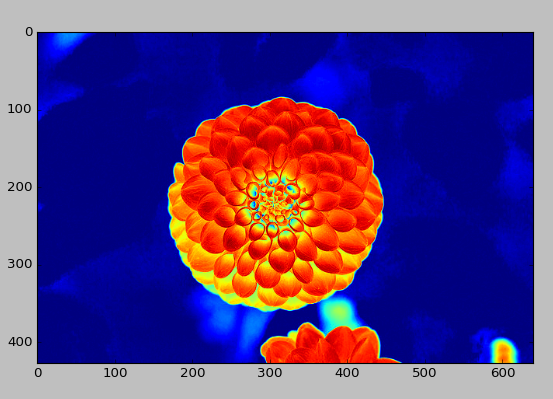
flower = load_sample_image("flower.jpg")
plt.imshow(flower)
plt.show()
print(flower.shape)
plt.imshow(flower[:,:,0])
plt.show()


1、读取一张示例图片或自己准备的图片,观察图片存放数据特点。
from sklearn.datasets import load_sample_image
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
import matplotlib.image as img
zj = img.imread('H:\timg.jpg')
plt.imshow(zj)
plt.show()
zj


2、根据图片的分辨率,可适当降低分辨率。
image = zj[::3,::3]
X = image.reshape(-1,3)
print(zj.shape,image.shape,X.shape)
plt.imshow(zjs)
plt.show()
zjs

3、再用k均值聚类算法,将图片中所有的颜色值做聚类。然后用聚类中心的颜色代替原来的颜色值。
n_colors= 64 #(256,256,256)
model= KMeans(n_colors)
labels = model.fit_predict(X)
colors = model.cluster_centers_
new_zjs = colors[labels]
new_zjs = new_zjs.reshape(zjs.shape)
plt.imshow(new_zjs.astype(np.uint8))
plt.show
plt.imshow(zjs);
plt.show()

4、形成新的图片。
plt.imsave('H:\timg.jpg',zj)
plt.imsave('H:\timgs.jpg',zjs)

5、观察原始图片与新图片所占用内存的大小。
import sys


6、将原始图片与新图片保存成文件,观察文件的大小。
size1 = sys.getsizeof('H:\timg.jpg')
size2 = sys.getsizeof('H:\timgs.jpg')
print('压缩前:'+str(size1)," 压缩后:"+str(size2))

理解贝叶斯定理:
- M桶:7红3黄
- N桶:1红9黄
- 现在:拿出了一个红球
- 试问:这个红球是M、N桶拿出来的概率分别是多少?
把计算过程与结果拍照发上来。
