一.线性表,如数组,单链表,双向链表
线性表、数组
U1.有序数组去重,返回新数组长度
A = [1,1,2] -> [1,2] 返回2
分析:其实一般数组的问题都可以用两个指针解决,一个指针用于指向新数组,一个用于操作就数组的指针。
解:

112移动后变成122
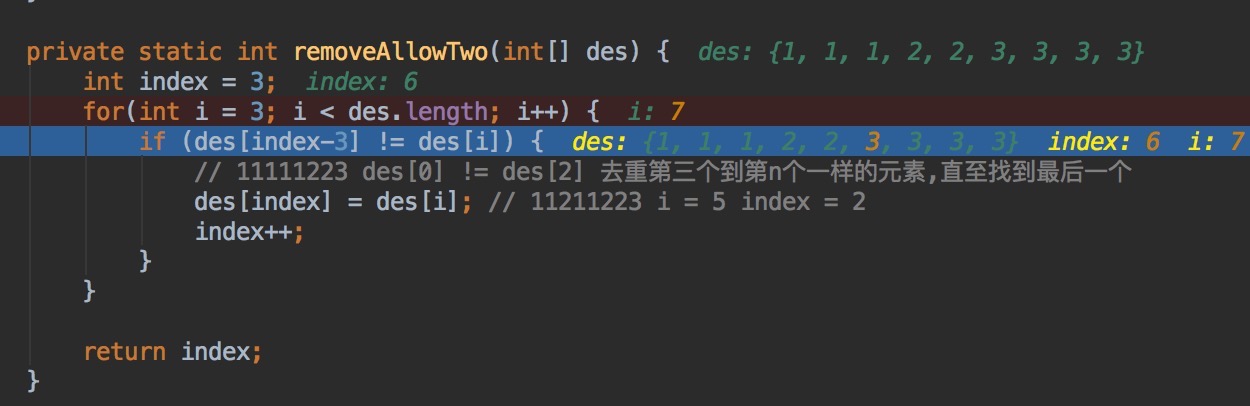
U2.有序数组去重II,返回数组长度
A = [1,1,1,2,2,3] -> [1,1,2,2,3] 允许每个数字最多出现两次
分析:以间隔2找寻下一个需要移动的元素
解:

总结:经测试,最多出现三次,使用如下算法可通过测试用例:
U3.查找:Search� in Rotated Sorted Array
A = [4 5 6 7 0 1 2], 返回查找的目标值的index, 没有返回-1.
分析:使用二分查找,关键点是:1、左右边界的确定 2、遍历方式采用mid值和left值比对
解:
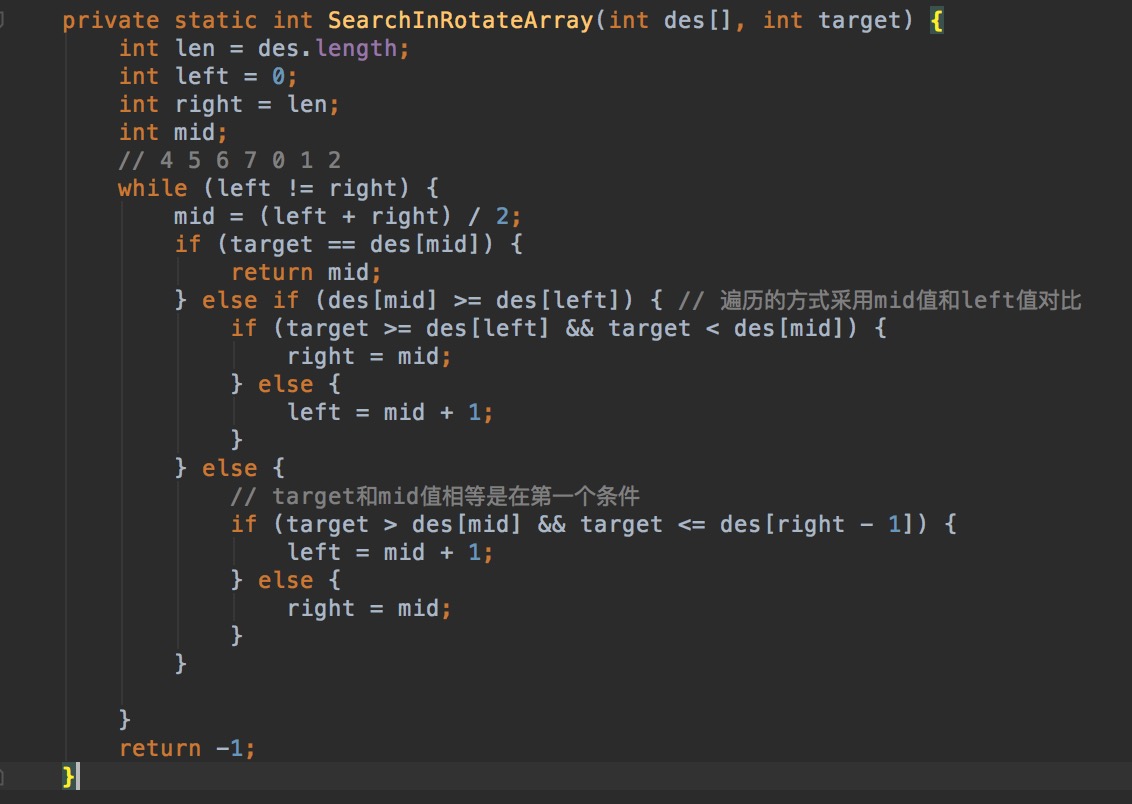
注意:在条件 des[mid] < des[left]分支中,说明当前数组有部分是逆序的,但是可以肯定的是在mid到right中是升序的,所以可以先判断target是否落在其中,否则走另一个条件。
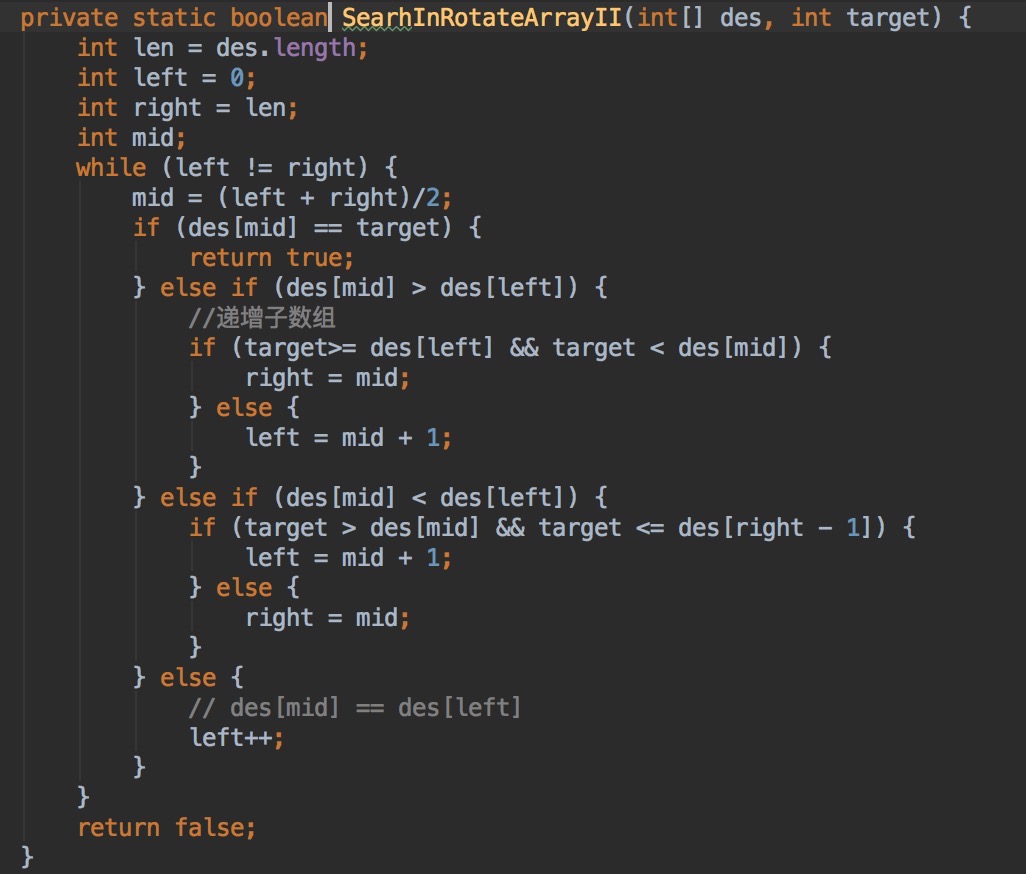
U4.查找,在U3的基础上添加一个条件,A数组中允许有重复的元素
A = [1 3 1 1 1], 找到返回true, 没有返回false.
分析:上题中的解des[mid] >= des[left]不能保证子数组一定是递增的了,所以需要把大于等于分开考虑
des[mid] > des[left]能保证子数组递增,des[mid] == des[left]只需要把left++
解:
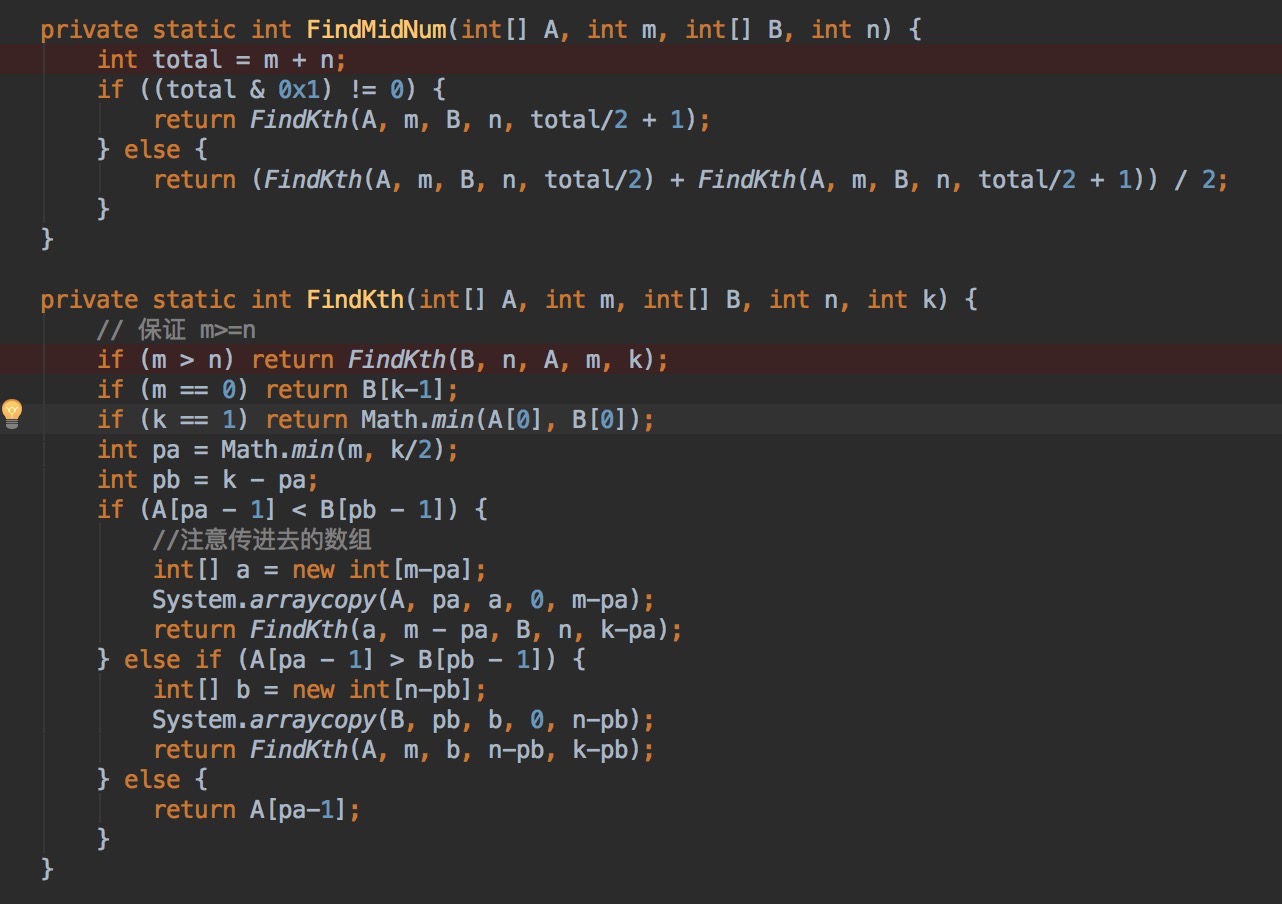
U5.找出两个有序数组中中间大元素。这是一道经典题目,找出两个有序数组中第k大元素。要求时间复杂度log(m+n).
分析:1、常用的解法是在数组A、B中放两个指针pa,pb,比较大小,移动指针,累加个数,直到k为止,即找到第k大的元素。
但是这种解法在k值接近m+n时,使劲复杂度趋近O(m+n).
2、使用类似二分查找法。
如果每次都删除一个一定在第k个元素之前的元素,那么要进行k次,如果一次删除k/2个元素呢?假设A、B元素个数都大于k个,那么
A[k/2-1]和B[k/2-1]两个元素只有以下几种情况:
A[k/2-1] > B[k/2-1]
A[k/2-1] < B[k/2-1]
A[k/2-1] = B[k/2-1]
第一种情况,说明B的前k/2个元素一定在第k大元素之前,也就是说可以直接删除B[k/2-1]数组之前的元素,同样的第二种情况可以直接删除
A[k/2-1]之前的元素,如果 A[k/2-1] = B[k/2-1] ,那么第k大元素就是 A[k/2-1]。
所以可以试用递归的方法来解。
终止条件就是:
•当A或B是空时,直接返回B[k-1]或A[k-1];
• 当k=1是,返回min(A[0],B[0]);
• 当A[k/2-1]==B[k/2-1]时,返回A[k/2-1]或B[k/2-1]
解:
U6.查找当前数组中能组成的最长连续子数组,并返回子数组的长度。要求时间复杂度O(n)。
A =[100, 4, 200, 1, 3, 2],最长子数组是B=[1, 2, 3, 4]返回长度4。
分析:由于要求时间复杂度是O(n),不能使用先排序,在查找的方法,因为最快的排序算法时间复杂度要O(nlogn)。
所以考虑使用哈希表,查找当前元素前后的元素,如果存在子数组长度加1,不存在继续遍历。找到前后元素要使用一个值标识上已经查找过,下次遍历到,直接跳过,所以使用HashMap作为数据结构。
解:
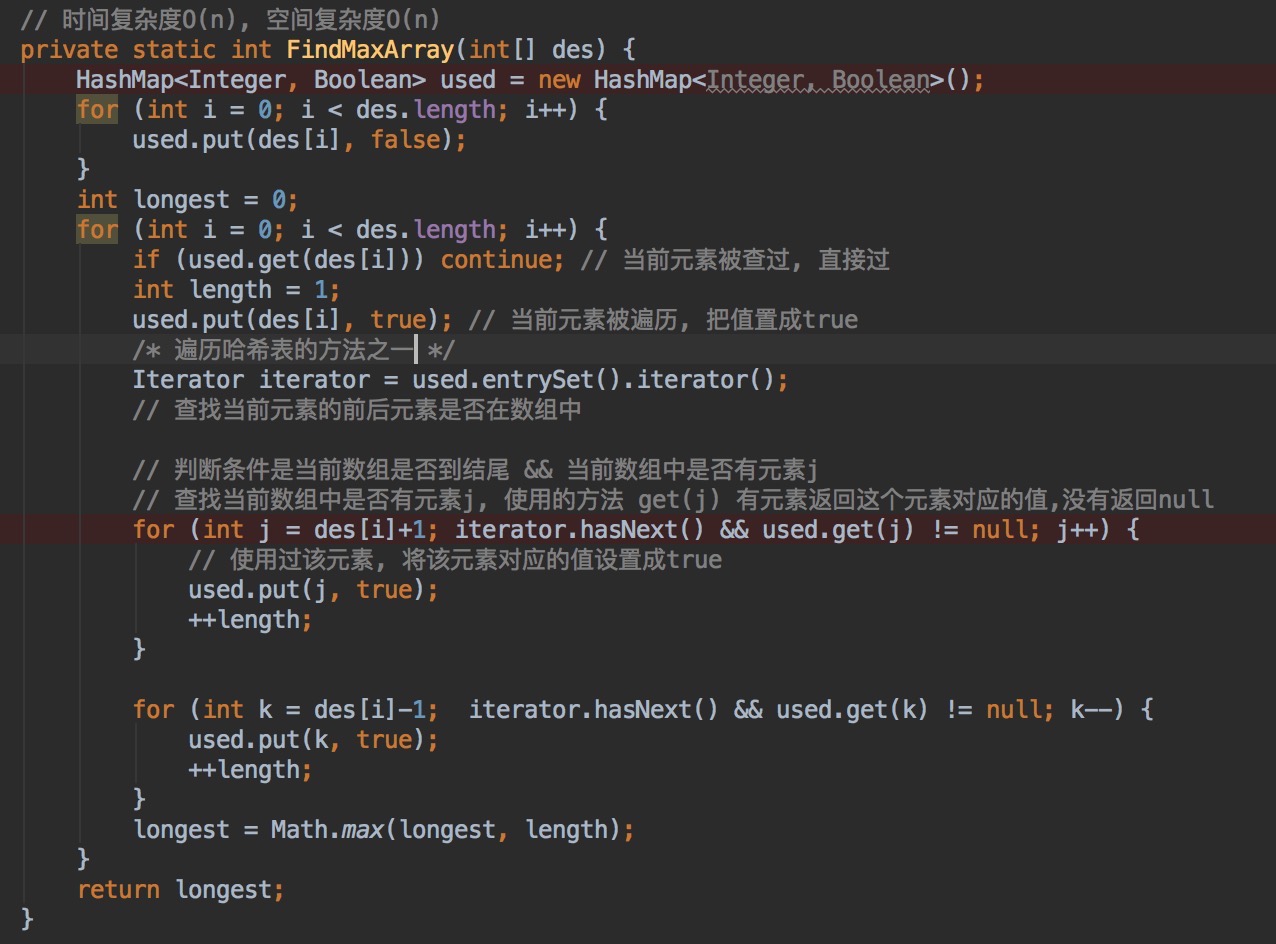
总结:算法说到底第一步要为解决该问题选择一个合适的数据结构,然后再想用什么逻辑来解决问题。
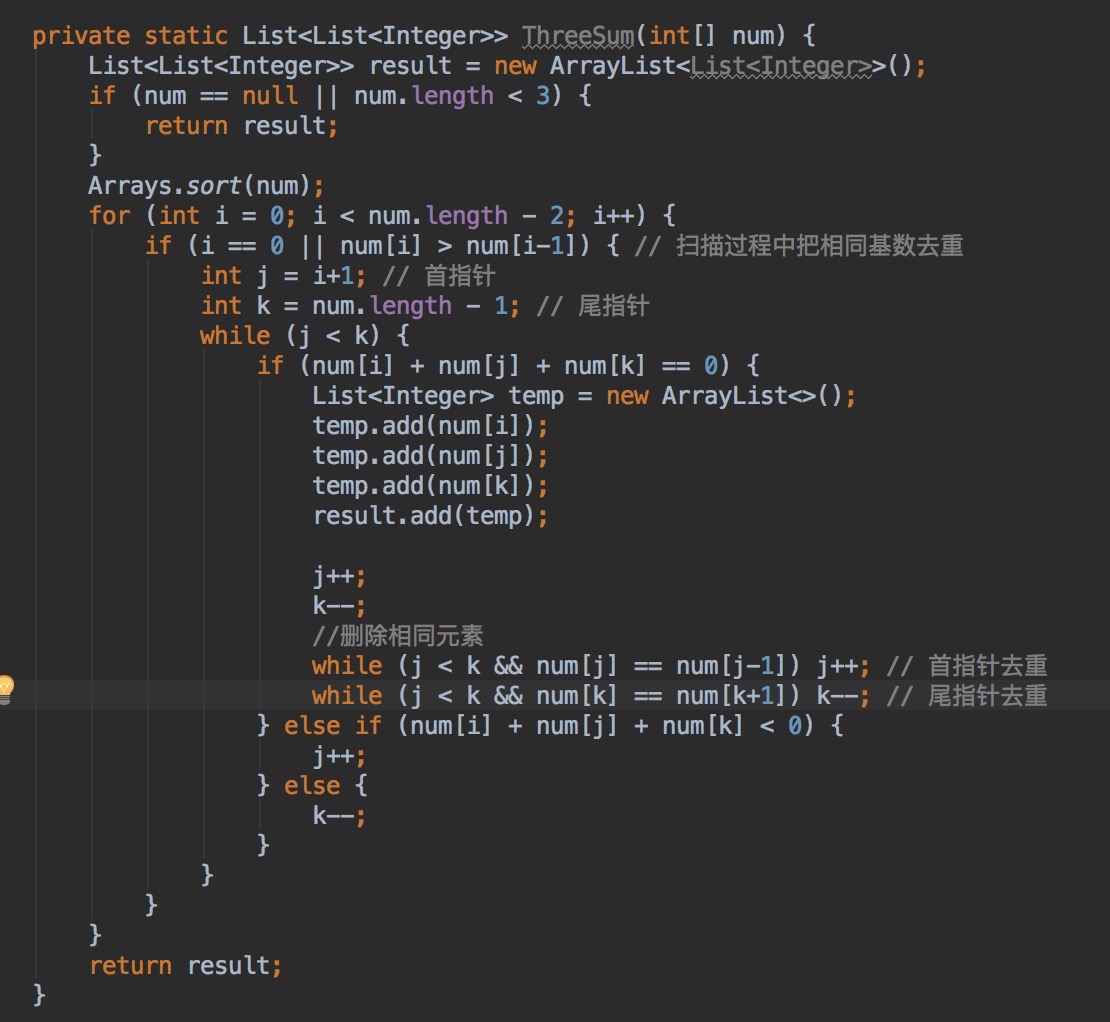
U7.3Sum :无序数组中三个数相加等于0,找出这样的数组序列。
A = {-1 0 1 2 -1 -4 }, 返回:(-1, 0, 1) (-1, -1, 2)
分析:首先把数组排序,然后选择一个基数,在移动两个指针,分别指向排好序的数组的开始和结尾元素,找到符合条件的子序列。
数组中可能存在重复元素,所以注意去重。
解:
U8.3Sum Closest,寻找数组中三个值的和,使得这个和最近金target,并将和返回。
A = {-1 2 1 -4}, and target = 1.
最接近1的3sum是 (-1+2+1=2) 返回2
分析:类似于3Sum,以一个数为基数,两个指针,根据三数之和与target的关系,移动指针,找到最接近target的三数,并返回其和。
解:
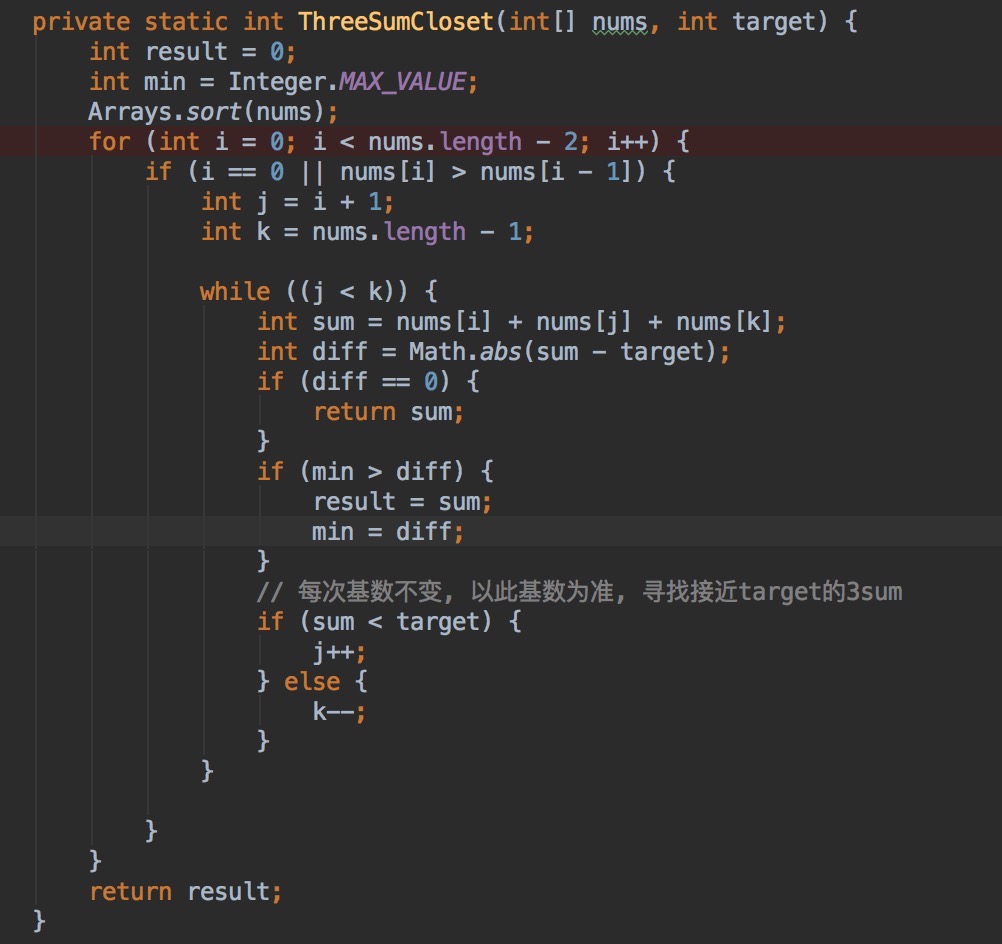
总结:这题与3Sum的不同之处在于,3Sum是要找到所有三数之和等于0的序列,所以,之和不等于0的可以直接越过。而这道题,是要找到所有距离target最近的三数之和,所以看关注的点来决定算法怎么设计。
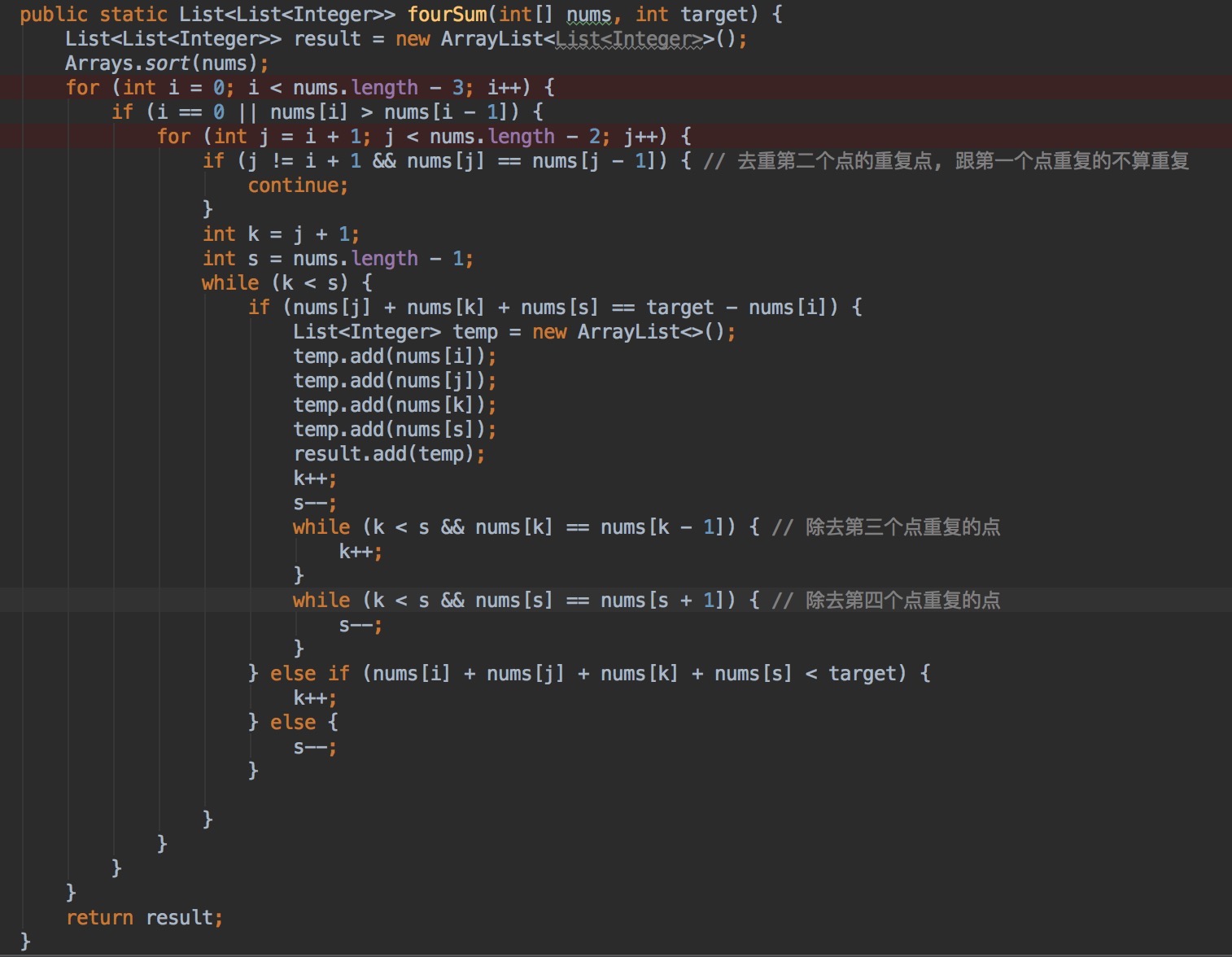
U9.4Sum,类似于3Sum,四个数的和等于target
A = {1 0 -1 0 -2 2}, and target = 0.
返回结果:
(-1, 0, 0, 1) (-2, -1, 1, 2) (-2, 0, 0, 2)
分析:解法类似于3Sum,先找一个基准,再根绝3Sum同样的解法,找第二个基准,遍历第三个和第四个值。保证遍历到所有情况。
需要注意的点是去重,第一个基准点的去重,第二个点的去重(注意,当第一个基准点和第二个基准点一样的时候,不去重),三四个点基准点去重,记得用while循环,去除多个重复点。
解:
U10:Remove Element . 删除数组中指定元素,返回新数组个数n,并保证新数组前n个元素是不包含指定元素的。
A= {3, 2, 2, 3},指定剔除元素3; 返回length = 2, 并且保证数组前2个元素是{2, 2};
分析:借助新的指针,可以解决新数组和新数组个数的问题。
解:
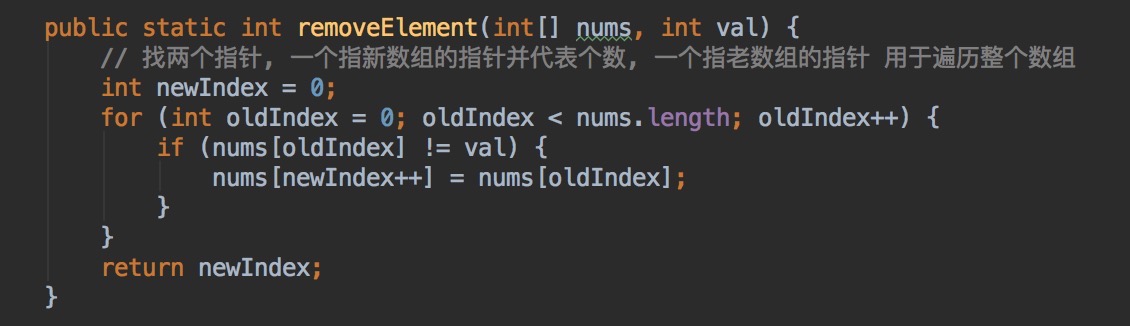
总结:删除数组中元素的问题, 可以借助指针,通常是新数组和原始数组的指针。
比如U1题目: 新理解方式,新的注释
private static int remove(int[] des) {
int index = 0;
for (int i = 1; i < des.length; i++) {
// index和i两个指针, index是新数组的指针, i是原始数组的指针
if (des[index] != des[i])
//把后面的数据往前移动
des[++index] = des[i];
}
return index + 1;
}
U11:寻找下一个排列,实现“下一个排列”函数,将排列中的数字重新排列成字典序中的下一个更大的排列。 如果这样的重新排列是不可能的,它必须重新排列为可能的最低顺序(即升序排序)。 重排必须在原地,不分配额外的内存。 以下是一些示例,
1,2,3 → 1,3,2
3,2,1 → 1,2,3
1,1,5 → 1,5,1
分析:比如排列是(2,3,6,5,4,1),求下一个排列的基本步骤是这样:
1) 先从后往前找到第一个不是依次增长的数,记录下位置p。比如例子中的3,对应的位置是1
2)接下来分两种情况:
(1) 如果上面的数字都是依次增长的,那么说明这是最后一个排列,下一个就是第一个,其实把所有数字反转过来即可(比如(6,5,4,3,2,1)下一个是(1,2,3,4,5,6));
(2) 否则,如果p存在,从p开始往后找,找到下一个数就比p对应的数大的数字(注意,由于步骤1证明这个序列是升序的,所以一个while循环即可找到最近金p位置元素的值,并且比它大),然后两个调换位置,比如例子中的4。调换位置后得到(2,4,6,5,3,1)。最后把p之后的所有数字倒序,比如例子中得到(2,4,1,3,5,6)。既的解。
解:
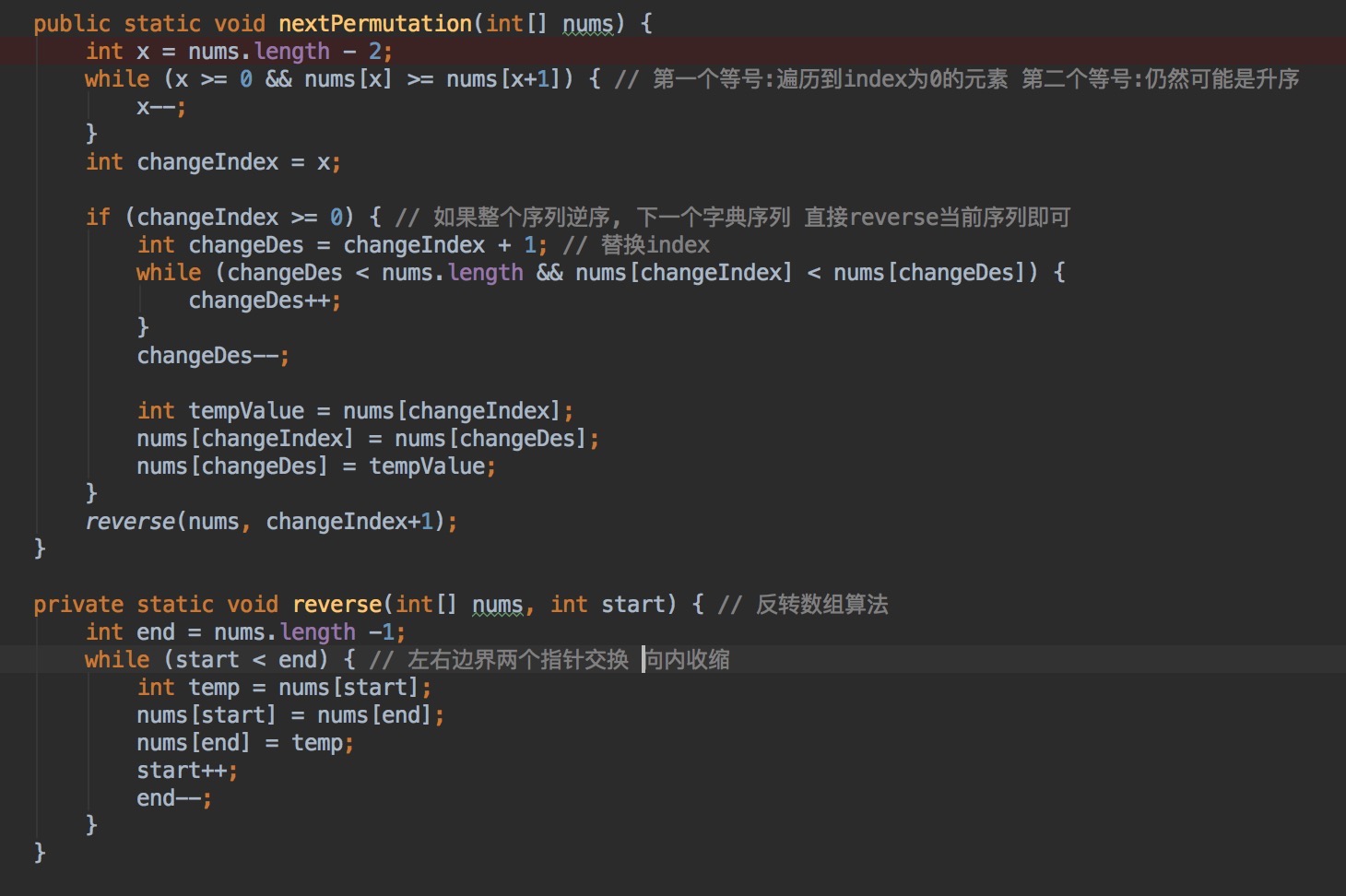
总结:要观察总结数组的特点,再配合指针,能效率更高、更简便的解决问题。
U12:给数n和k, 求a1,a2...an组成的全排列中第k个排列。
分析:方法1:可以使用U11暴利求解k-1次
方法2:数学方法,规律:n个数组成的全排列个数一共有n!个, 确定全排列中第一个位置的数字a1, 剩下的全排列个数是(n-1)!个,所以第一个数字就是k/(n-1)!下标对应的值(因为求得的是下标,所以在计算之前要k--,还有要注意,求得a1后,要从数组中吧这个a1删除,从数组中剩下的数字求排列), 同样,a2的求解方式 k2/(n-2)!下标对应的值。 k2 = k%(n-1)!, 以此类推,求n次,即可求得第k个数列。
解:
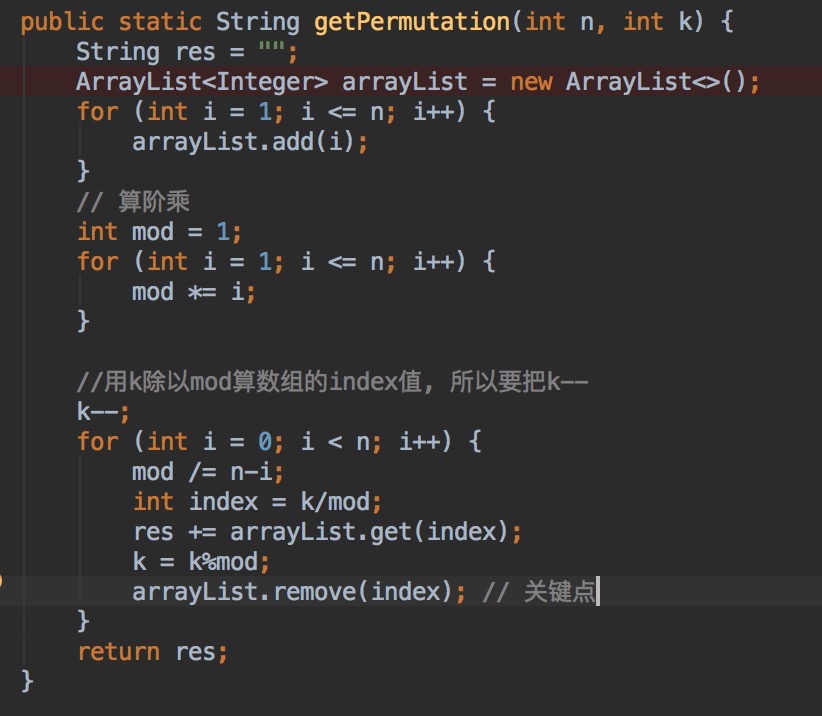
总结:看题目的规律, 是不是可以使用数学方法解决。
U13:Valid Sudoku,
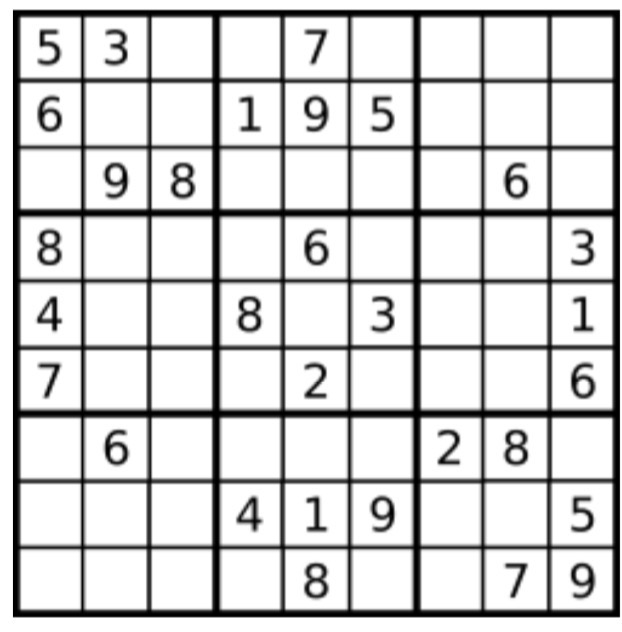
没看题目前,以为是填数,好复杂。。。仔细看了下,题意是看现有数阵中,横列、竖列和9个3*3方阵中的数字是不是在1~9中无重复的数字。
分析:考虑使用HashSet数据结构,其中不允许有重复元素。所以每行每列使用for循环配合HashSet即可(使用一个HashSet,每次用完清除下HashSet)。
需要注意的是3*3方阵怎么组织for循环,
最为外层要循环9次,对应九个小方阵,那么要借助第一个for循环的k, k = 012都对应第012列, 也就是i的初值不变,只是累加三次,而j的值要随着k的变化
分别是012 345 678,所以初值 i = k/3*3, j = k%3*3;
解:
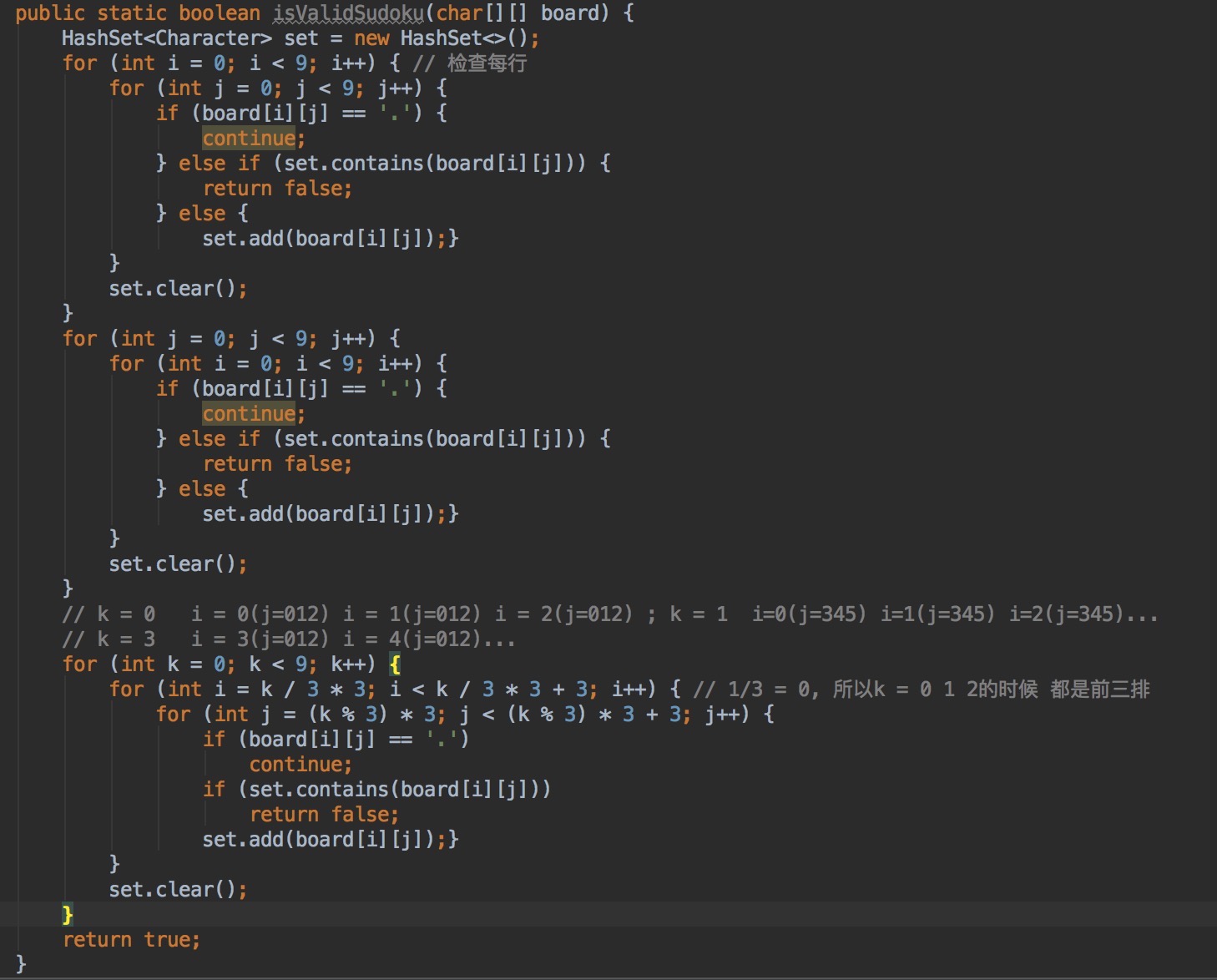
U14:trap water, 数组在数轴上按照1:1比例从左到右摆放,求数组能装的最大水量。
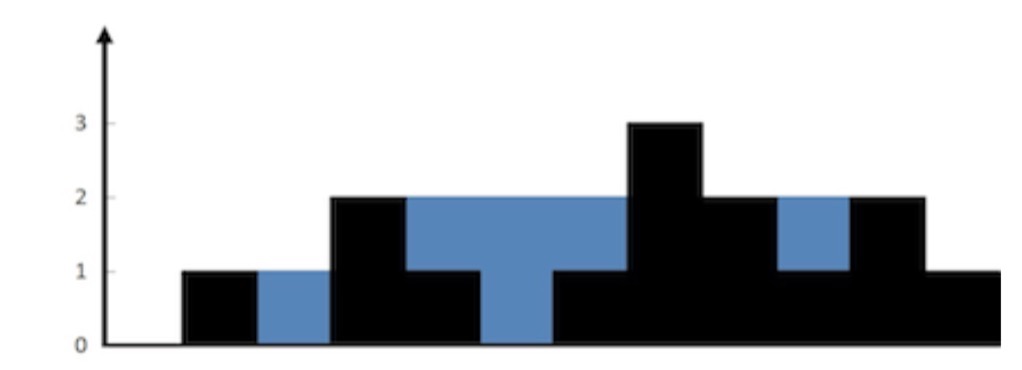
分析:借鉴网上解法,将数组从两端往中间逼近,两个指针所指的数,从小的那一侧开始,同时存储当前遍历的数组中的次大值,
存水计算过方式就是次大值-当前指针所指的数组值。
解:

总结:分析题目规律,借助指针,寸的值用声明一个新变量来解决问题。
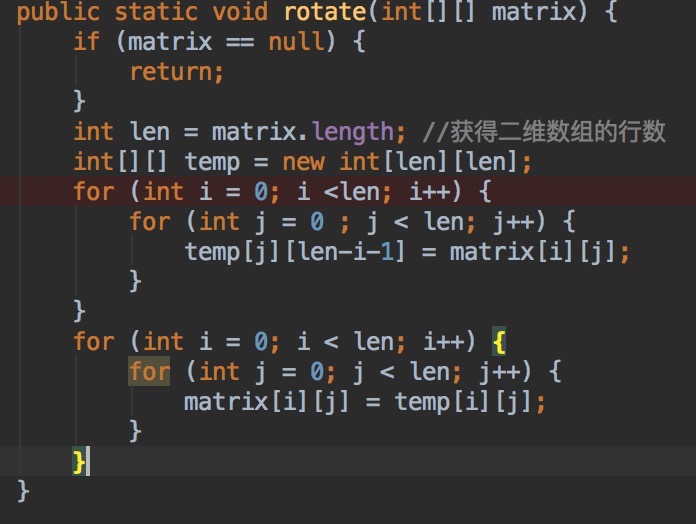
U15:n*n二维数组顺时针旋转90°
分析:数组第一行变成最后一列,第二行变成倒数第二列....最后一行变成第一列。(注意,二维数组不能直接赋值,要一个值一个值的赋值)
解:
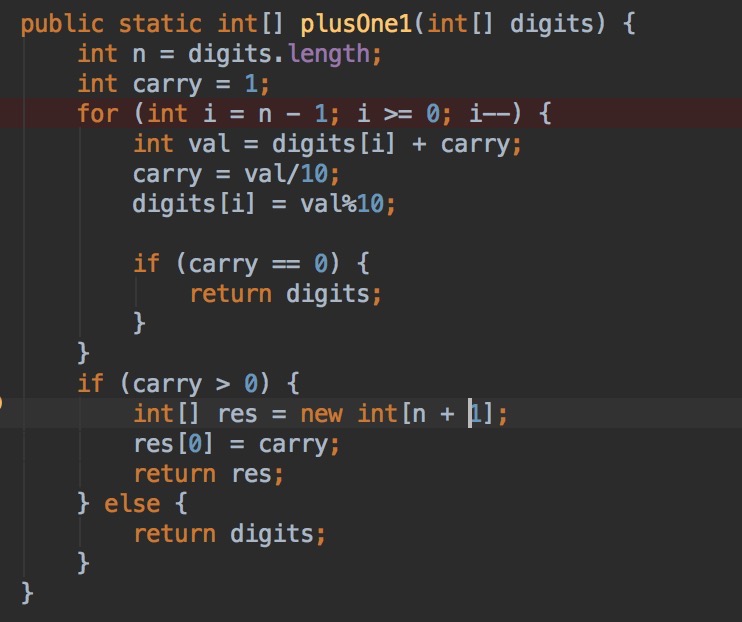
U16.Plus One
一个数组中存一个数,高位存在数组下标0开始的位置, 给这个数加1,返回结果。
分析:主要考虑进位问题,其中,如果到最高位仍然有进位,注意返回值是多一位。优化解法,设置一个变量,当做进位,初始值设置成1,代表加的1,
当进位变量变成0后,接下来的就不用再计算。(进位用计算完相加的值除10得进位值,取余得当前位的值)
解:
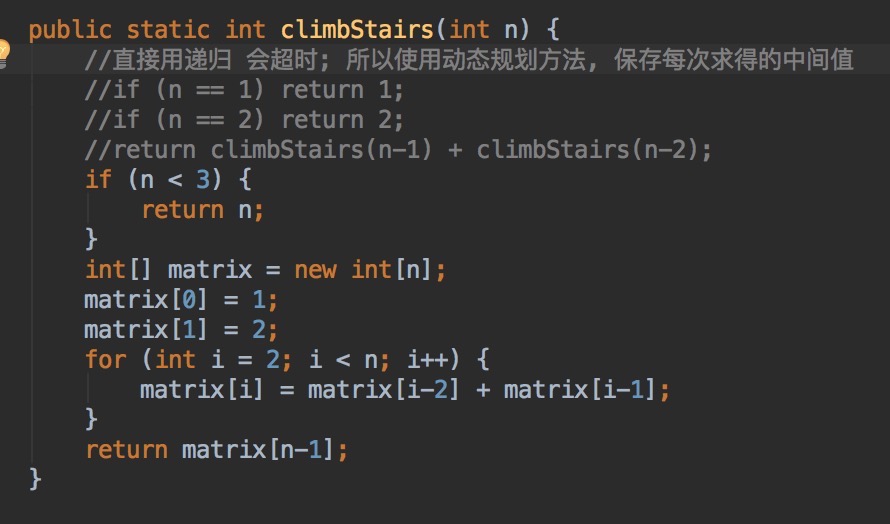
U17:爬楼梯,一次可以爬一个阶梯,也可以爬两个阶梯,求n个阶梯共有多少种爬法。
分析:f(n) = f(n-1) + f(n-2)斐波那契数列问题, 如果用递归算法,会超时,所以考虑使用动态规划,存储每次算得的中间值。
解:
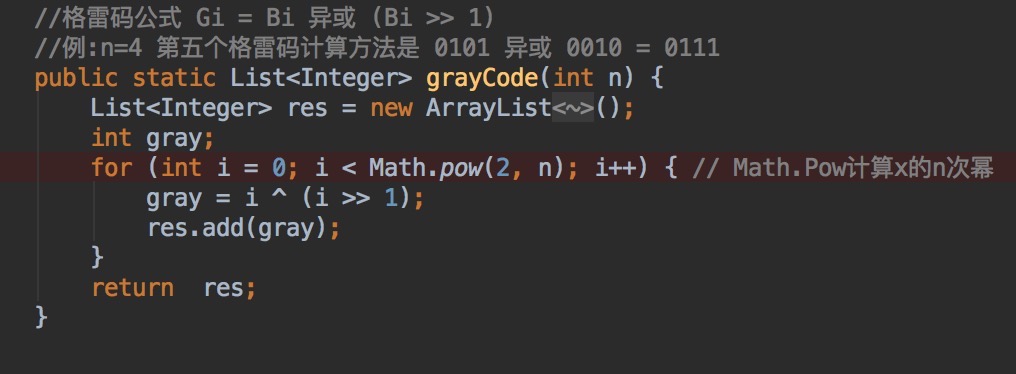
U18:gray code, 给一个数n, 生成n个二进制数组成的格雷码(格雷码的特点是相邻的数只有一位二进制位不同)。
分析:格雷码生成有两种方法:
方法一: 三位的格雷码 是 两位的格雷码 前四位前面加0, 后四位前面加1然后倒序。
00 01 11 10
000 001 011 010 110 111 101 100
方法二:使用异或,n位二进制位有2的n次幂个数组成格雷码,那么第i位格雷码的生成规则是 i的二进制表示与 i >> 1 的二进制表示的异或,即
Gi = Bi 异或 (Bi>>1) >> 右移
解:
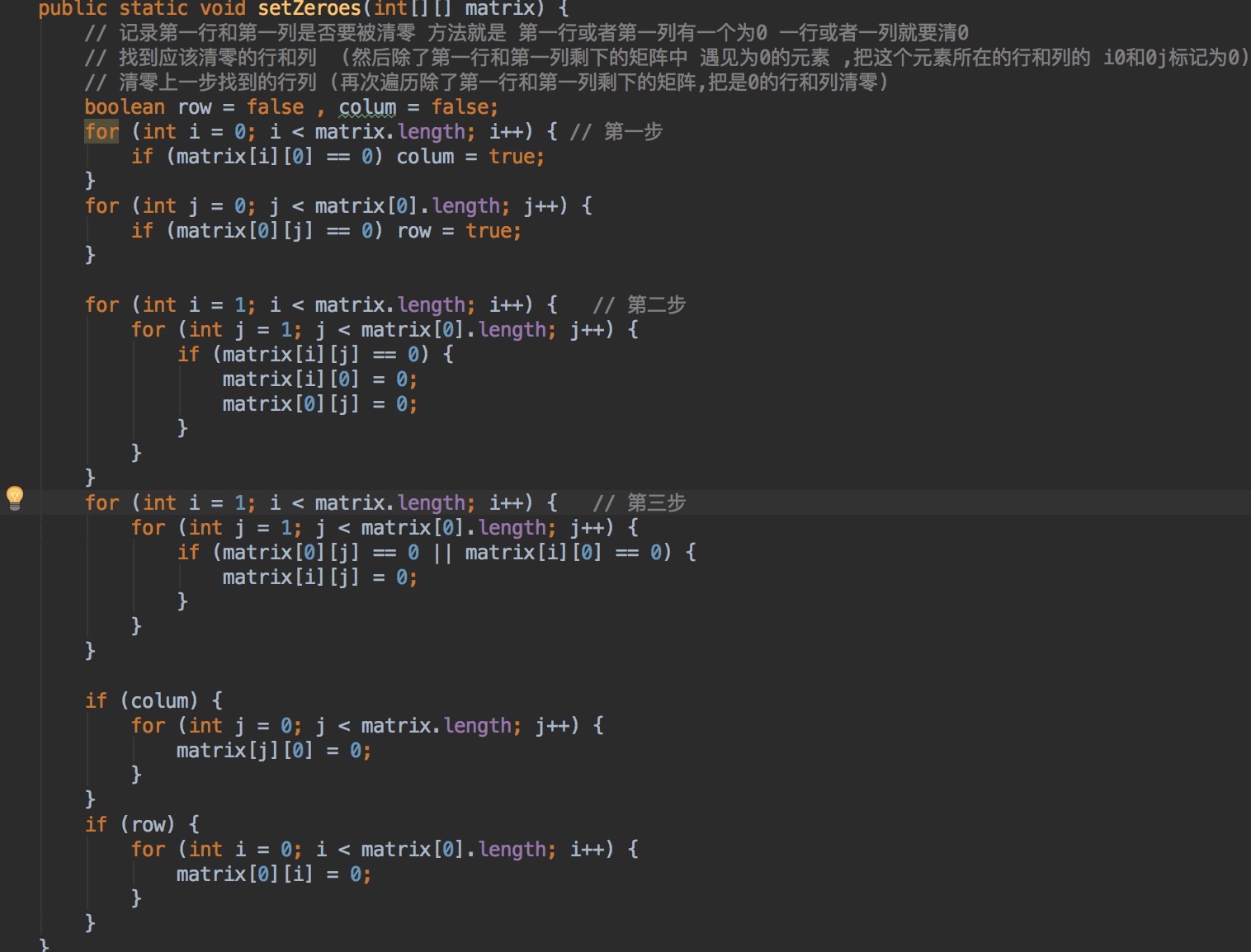
U19:ZeroMatrix, 一个二维数组,使数组中为0的元素所在的行和列为0。要求空间复杂度为线性。
分析:如果简单的在原数组中直接设置0,整个数组会被设置成0,原有的值会被覆盖,如果在申请个数组保存原来的值,不符合题目中空间复杂度线性的条件。so,
(2步)利用原数组的第一行和第一列,把第一行中的每个元素,对应二维数组中每一列元素(列元素中有0那么这一列元素的第一行中的元素置成0);
第一列中每个元素作为,每一行元素中是否有0的标识(这一行有0,那么第一列中对应的元素为0)。在利用第一行元素和第一列元素做标识之前(1步)要先标记第一行元素和第一列元素是否需要置成0(方法就是看第一行中和第一列中是否有0);(3步)根据第一行和第一类元素中的0,清除这一行和这一列元素为0.
解:
U20:加油站围成一个圈,gas[i]标识第i个点的加油站油量,cost[i]代表从第i个点到第i+1个点所消耗的油量。求从哪个点开始走能走完这一圈。不能走完返回-1,只有一个答案。
分析:从头开始遍历,直到遍历到当前邮箱剩余量不足以走到下一站,说明当前sum1 < 0, 并且是由于sum1中最后一站不够使用导致的;依次往后推,直到gas.length,走完一圈,如果当前剩余油量sumn大于0,并且满足sumn + ...+sum2+sum1 >= 0,说明当可以循环一圈。
解:

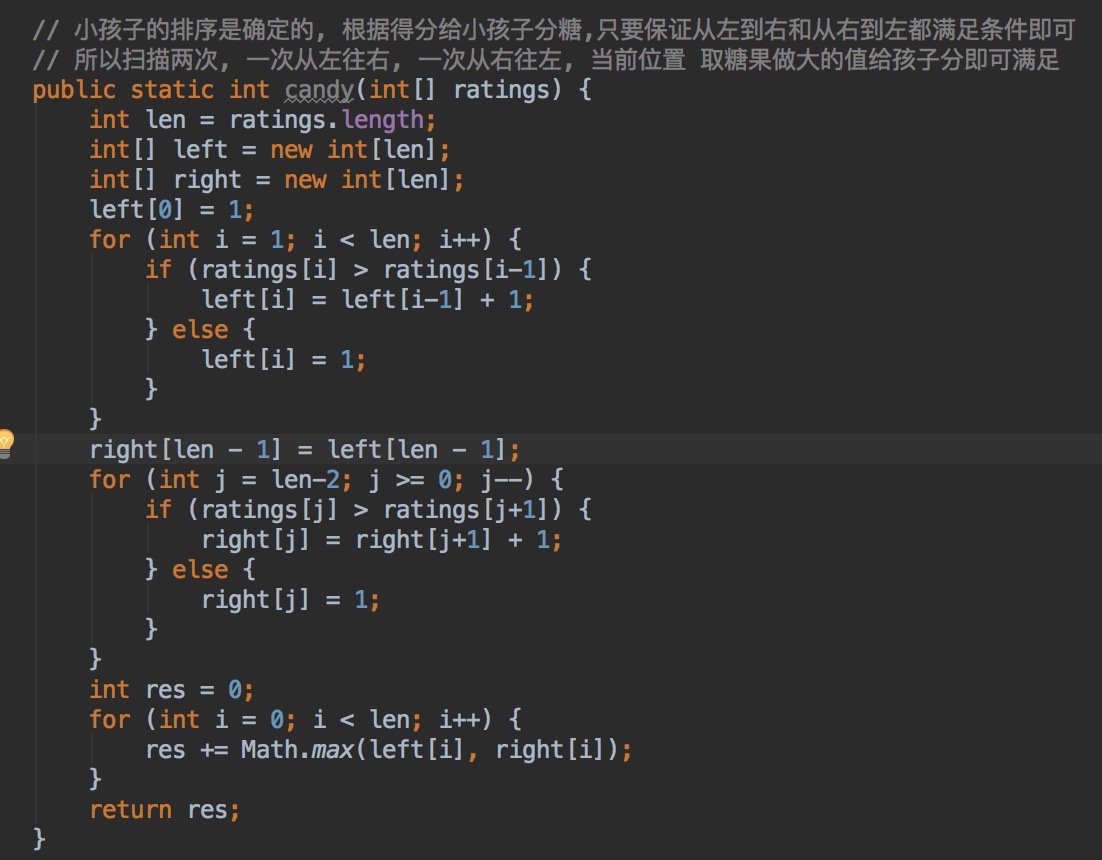
U21:一排小朋友,根据得分分糖果,每个小朋友至少一颗糖果,但要保证分高的小朋友得到的糖果要多于左右小朋友的糖果。
分析:从左到右和从右到左分别设置一个当前小朋友应得糖果的值,分别存放在两个数组中,然后遍历两个数组,取数组中较大的值即可。
解:
U22:SingleNumber:Given an array of integers, every element appears twice except for one. Find that single one.
分析:使用异或,成对出现的数异或后的结果是0,剩下的就是要求得得数字。
解:
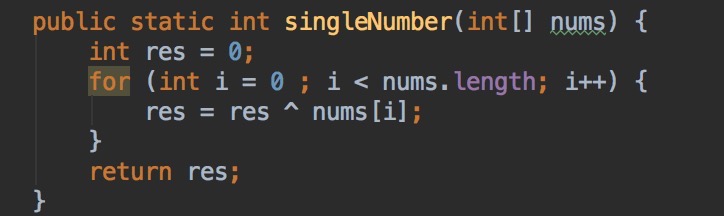
U23:SingleNumberII:Given an array of integers, every element appears three times except for one, which appears exactly once. Find that single one.
Note:
Your algorithm should have a linear runtime complexity. Could you implement it without using extra memory?
分析:显然,这道题目不再能使用异或来解决,那就想想选一个合适的数据结构,因为有的值是出现多次,只有一个值出现一次,所以考虑使用map(HashSet的特点是集合内不允许有重复的元素,所以不适合该题目)。所以当前遍历的值如果在map中不存在,把对应的value设置成1,如果map中已存在这个值,把value设置成2。最后再遍历一次,找到value值是1的即找到目标值。
解:

链表
L1:两个链表,代表两个数,求两个数相加,并以链表形式返回。
(2->4->3)+ (5->6->4) 返回 7->0->8
分析:1、注意进位问题;2、两个链表长度不一致处理(注意带上进位);3、最后只有一个进位,要处理
关键点,返回链表处理:一般是先声明一个链表用于返回用,再声明一个链表指向这个返回链表,用于操作使用。
解:
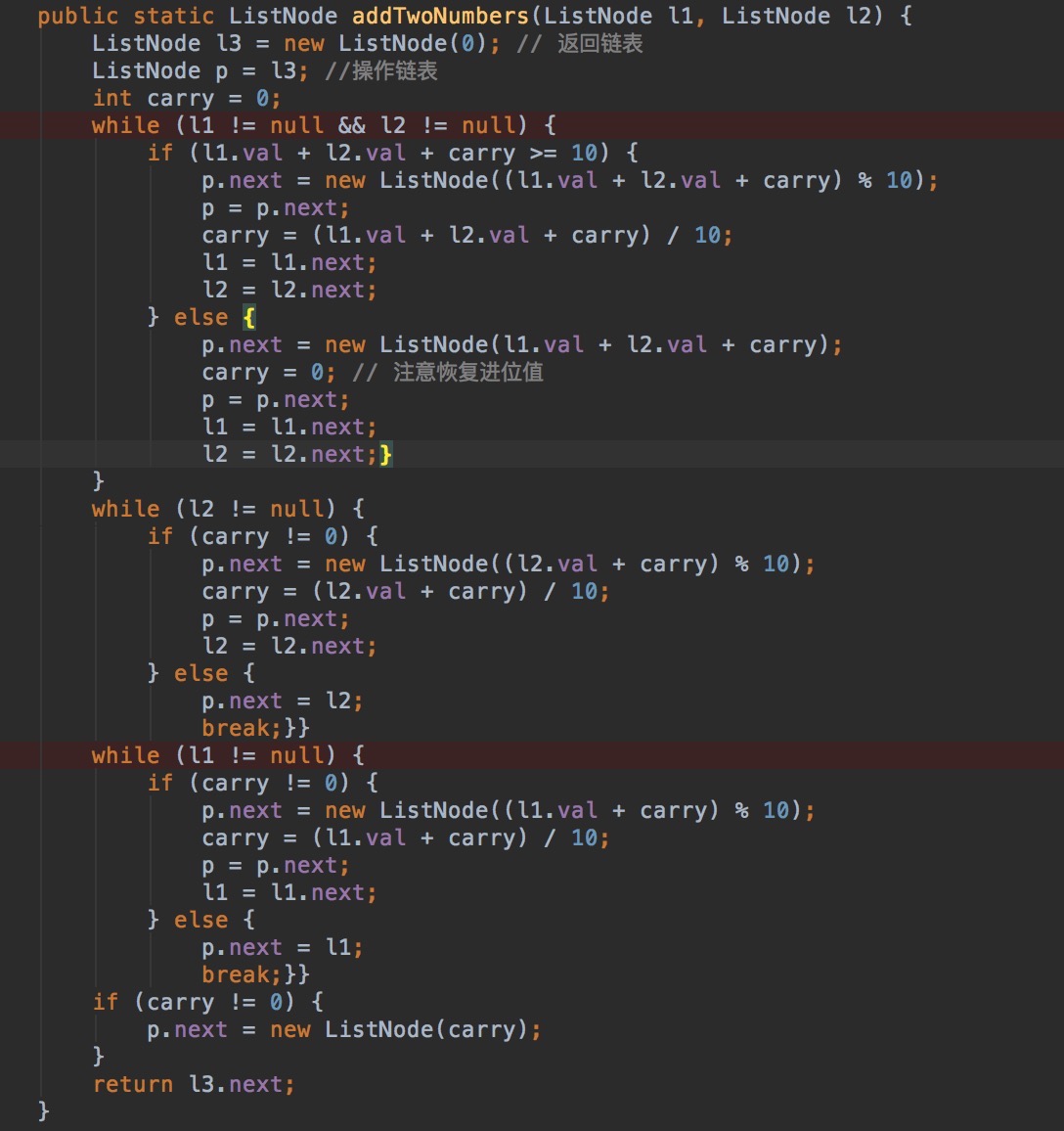
L2反转部分链表,输入单链表表头以及m,n。反转链表中第m到第n个值。
例:1->2->3->4->5 m = 2, n = 4 反转结果 1->4->3->2->5
分析:从第m个开始,依次把元素插入合适的位置。操作指针分别指向1、2、3,链表变成1-3-2-4-5后,指针分别指向1、2、4。再把4移动到1后面,以此类推。
解:
L3:Partition List ,题意是输入一个链表和一个值a,改变链表使得链表中小于a的值都放到,第一个大于等于a的值前面。
例如:1->4->3->2->5->2 and x = 3 , 改变后的链表应该是 1->2->2->4->3->5。也就是把小于3的2 2 都放在第一个大于3的4前面。
分析:求解过程中一直试图操作三个指针,分别是待插入节点的前一个节点,和当前操作的节点和它的前一个节点,但是算法修改很多次,还是有问题,于是乎,,,网上寻找了一个很赞的解法。
用两个链表分别维护小于目标值的节点链表 和 大于目标值的链表,并且顺序不会有问题。只维护两个指针,分别是待插入节点的前一指针和待插入节点的指针。移动是根据当前值小于目标值而移动。见解法以及注释。
解:

L4:Remove Duplicates from Sorted List
删除有序链表中的重复值
例:输入 输出
1->1->2 1->2
1->1->2->3->3 1->2->3
解:
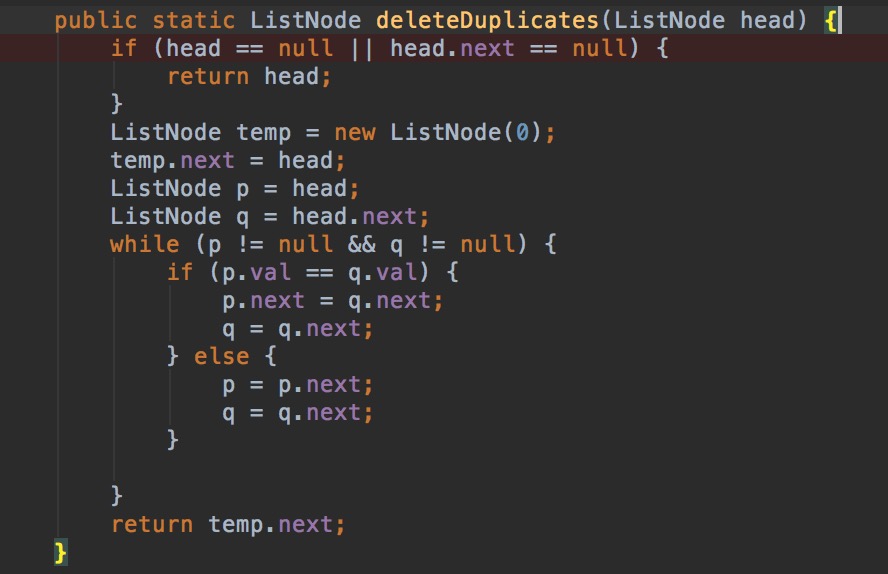
L5:Remove Duplicates from Sorted List II
删除链表中重复的元素,返回只出现一次的元素的链表。
例子:
输入 输出
1->2->3->3->4->4->5 1->2->5
1->1->1->2->3 2->3
解:
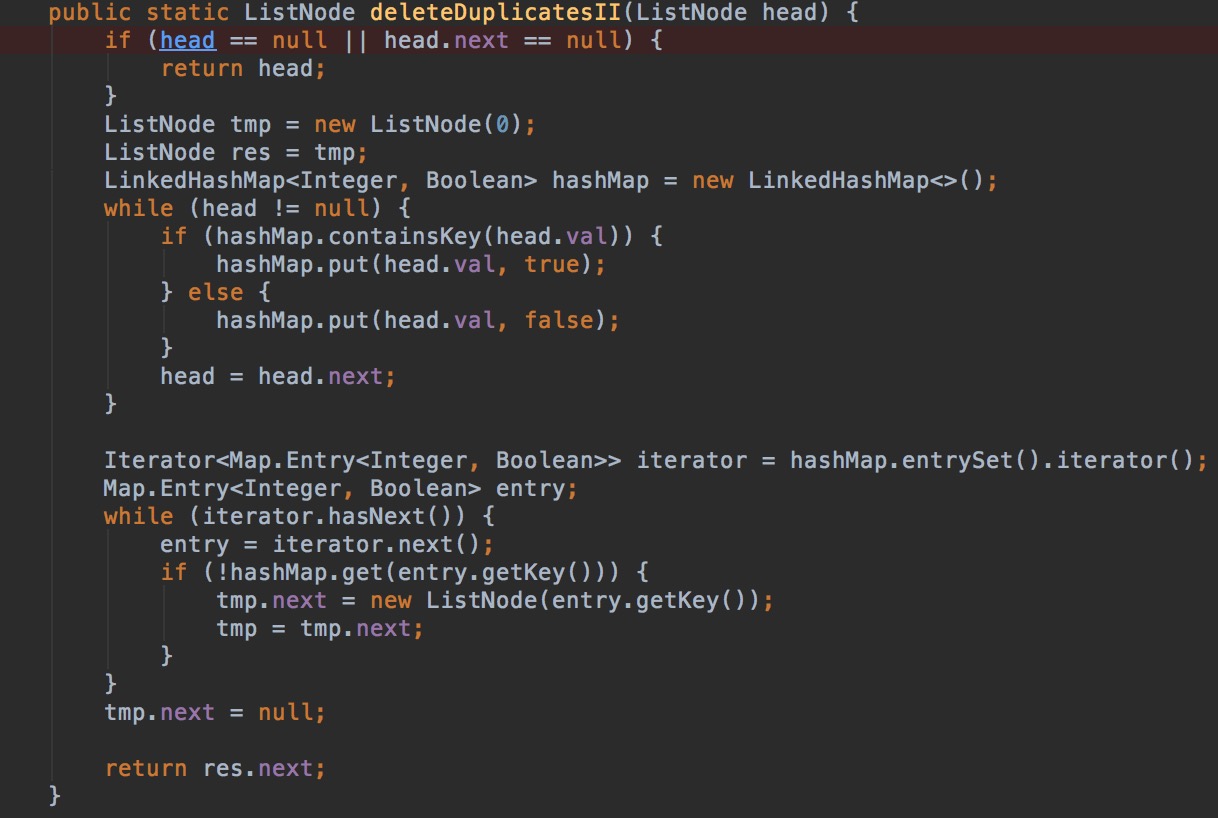
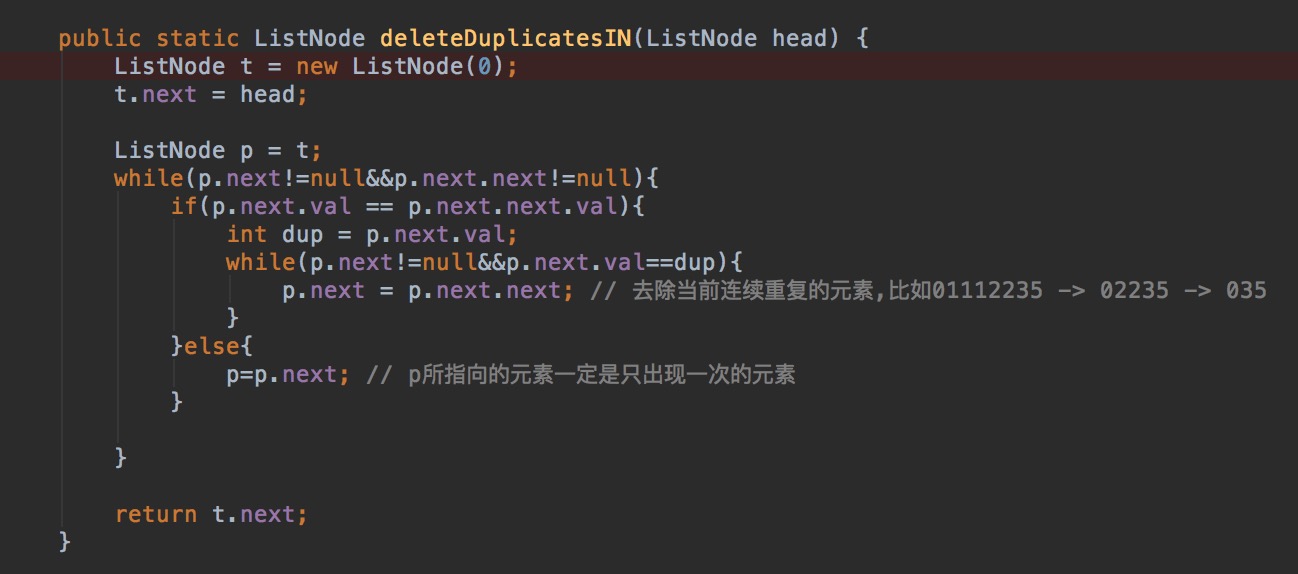
两种解法,第二种是参考网上的解法。
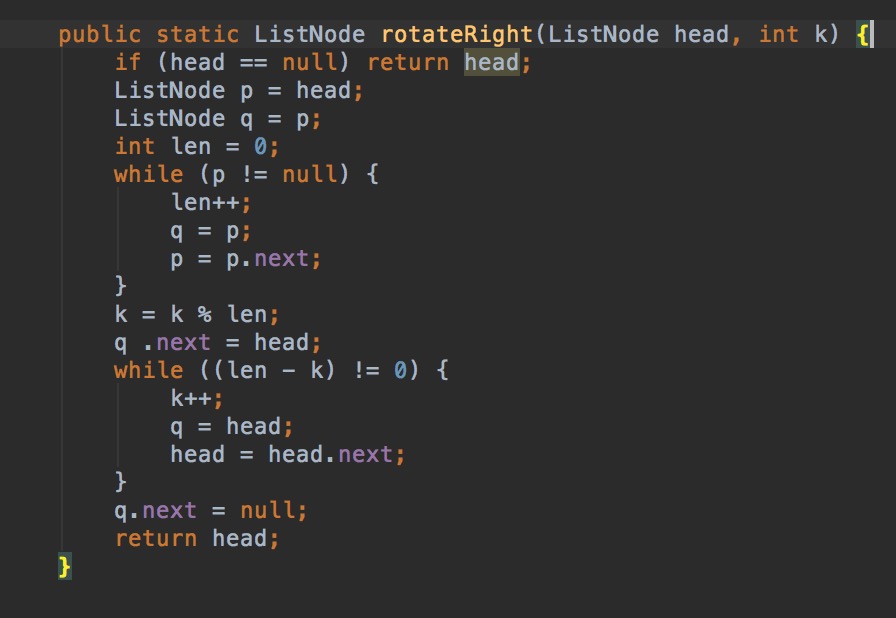
L6: Rotate List
Given a list, rotate the list to the right by k places, where k is non-negative.
For example: Given 1->2->3->4->5->nullptr and k = 2, return 4->5->1->2->3->nullptr.
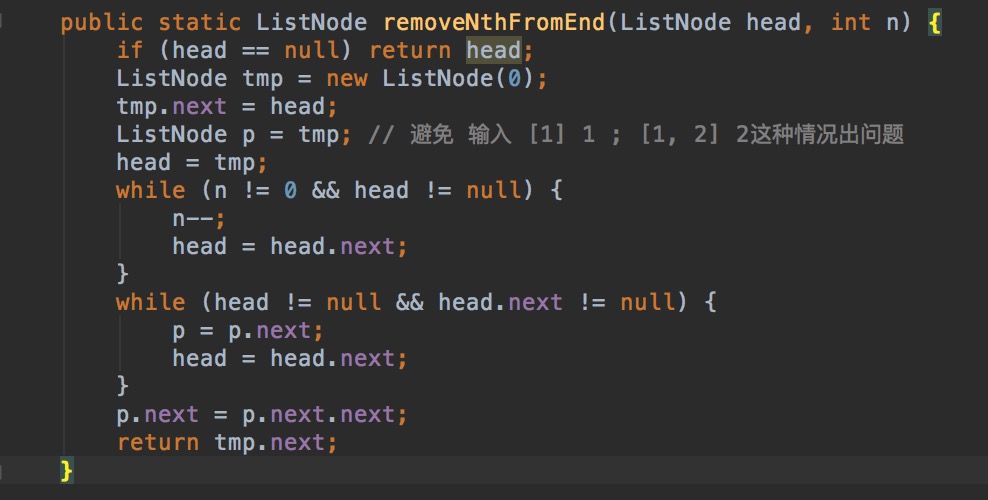
Given a linked list, remove the nth node from the end of list and return its head. For example, Given linked list: 1->2->3->4->5, and n = 2.
A�er removing the second node from the end, the linked list becomes 1->2->3->5.
Given a linked list, swap every two adjacent nodes and return its head.
For example, Given 1->2->3->4, you should return the list as 2->1->4->3.
Your algorithm should use only constant space. You may not modify the values in the list, only nodes
itself can be changed.

L9:Reverse Nodes in k-Group
Given a linked list, reverse the nodes of a linked list k at a time and return its modified list.
If the number of nodes is not a multiple of k then le�-out nodes in the end should remain as it is.
You may not alter the values in the nodes, only nodes itself may be changed.
Only constant memory is allowed.
For example, Given this linked list: 1->2->3->4->5
For k = 2, you should return: 2->1->4->3->5
For k = 3, you should return: 3->2->1->4->5
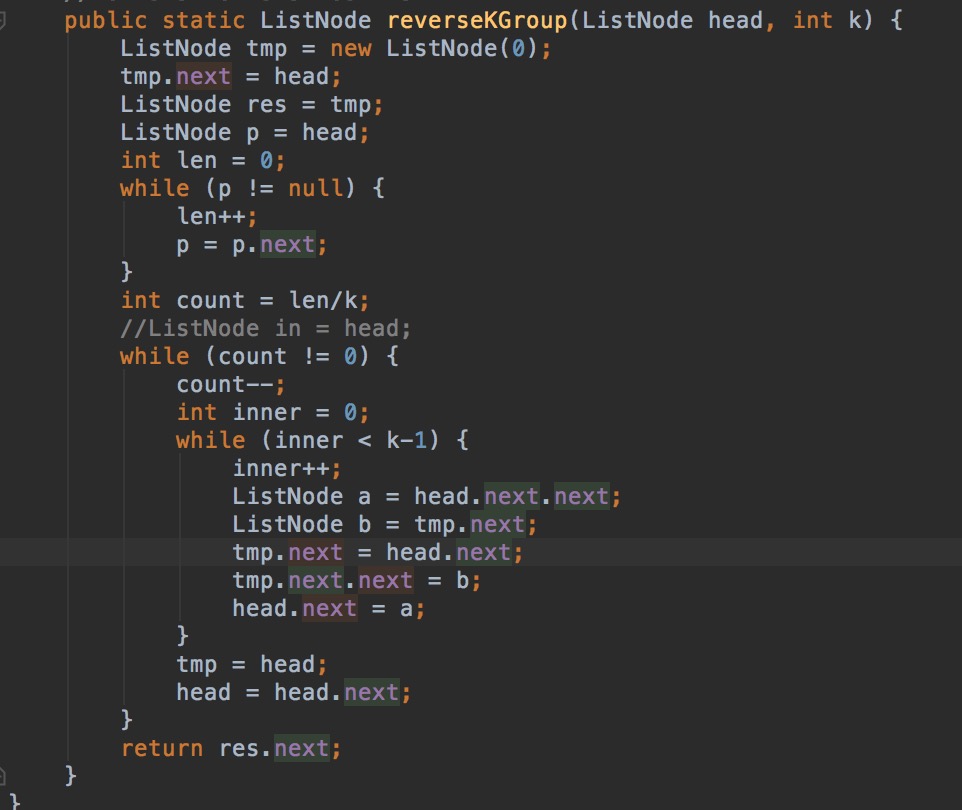
L10:Copy List with Random Pointer
A linked list is given such that each node contains an additional random pointer which could point to any node in the list or null.
Return a deep copy of the list.
链表深拷贝
解:
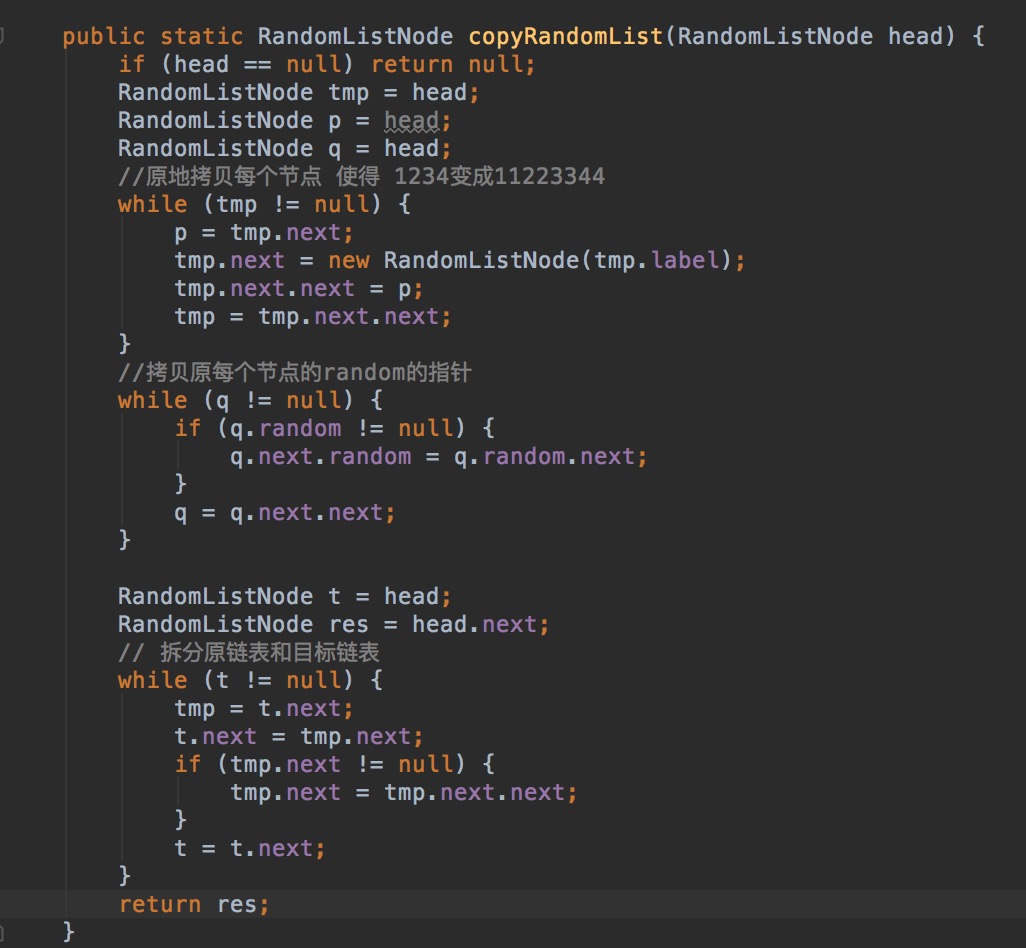
L11:Linked List Cycle
Given a linked list, determine if it has a cycle in it. Follow up: Can you solve it without using extra space?
分析:使用快慢指针,如果链表存在环,那么快慢指针一定会相交
解:
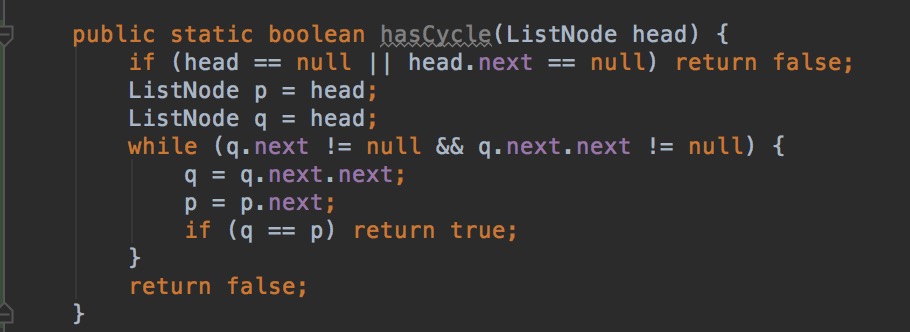
L12:Linked List Cycle II
Given a linked list, return the node where the cycle begins. If there is no cycle, return null. Follow up: Can you solve it without using extra space?
分析:在快慢指针交点开始,慢指针每次只走一步,快指针指向head,每次走一步,那么两个节点相交的点就是环入口点。因为环到入口点的距离a, 入口点到交点距离x, 交点再到入口点距离b有这样的关系: a = b + nl; a+x +nl = 2(a+x) -> a+x = nl = (n-1)l + b+x -> a = b + (n-1)l
解:
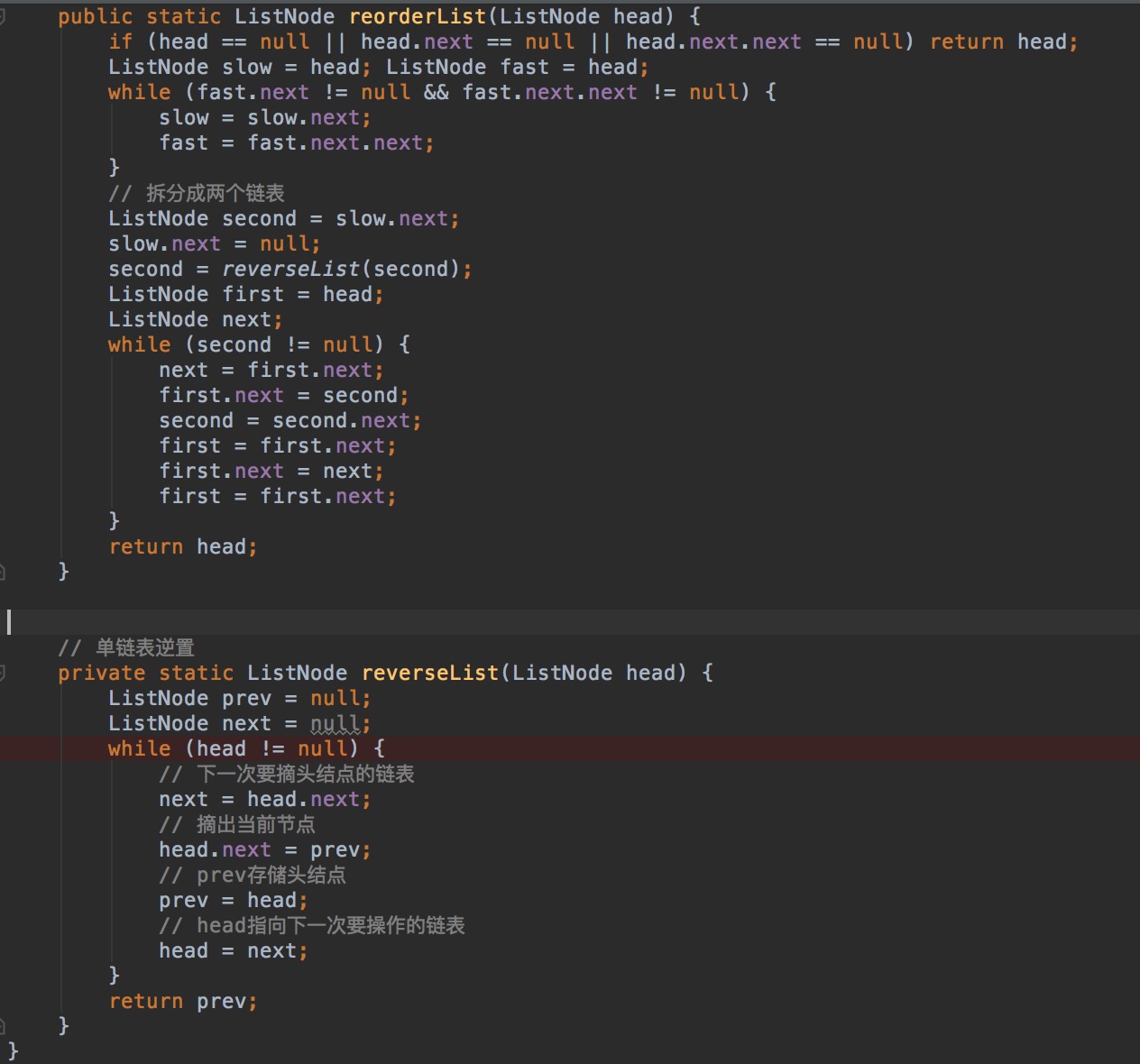
L13:Reorder List ,
GivenasinglylinkedlistL : L0 → L1 → ··· → Ln−1 → Ln,reorderitto: L0 → Ln → L1 → Ln−1 →L2 →Ln−2 →···
You must do this in-place without altering the nodes’ values. For example, Given {1,2,3,4}, reorder it to {1,4,2,3}.
要求使用O(1)空间复杂度。
分析:找到链表中点,断开,后半部分链表逆置,两个链表再合并。
解:
L14:LRU Ca�che,
Design and implement a data structure for Least Recently Used (LRU) cache. It should support the following operations: get and put.
get(key) - Get the value (will always be positive) of the key if the key exists in the cache, otherwise return -1.put(key, value) - Set or insert the value if the key is not already present. When the cache reached its capacity, it should invalidate the least recently used item before inserting a new item.
Could you do both operations in O(1) time complexity?
分析:使用两个数据结构,双向链表和HashMap, HashMap用于快速定位查找到的元素,双向链表用于操作移动最近访问的元素到链表头。查找一次,需要移动操作。插入过程要判断链表长度,超过capacity, 删除链表尾部。
解:
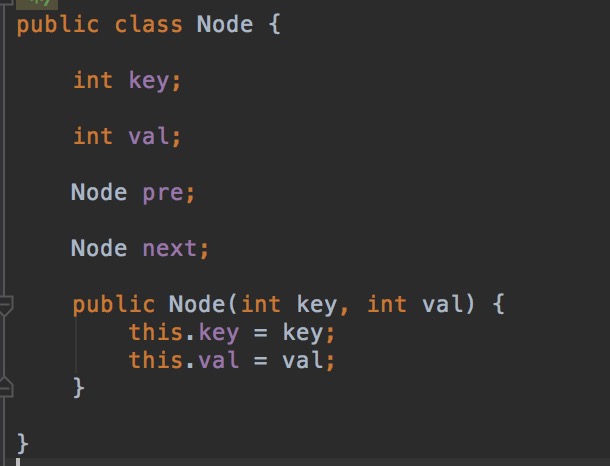
代码略长,直接贴出来:
1 public class LRUCache { 2 3 private int capacity; 4 private HashMap<Integer, Node> mHashMap = new HashMap<Integer, Node>(); 5 private Node head = null; 6 private Node end = null; 7 public LRUCache(int capacity) { 8 this.capacity = capacity; 9 } 10 public int get(int key) { 11 if (mHashMap.containsKey(key)) { 12 Node tmp = mHashMap.get(key); 13 remove(tmp); 14 setHead(tmp); 15 return tmp.val; 16 } else { 17 return -1; 18 } 19 } 20 public void put(int key, int value) { 21 if (mHashMap.containsKey(key)) { 22 Node tmp = mHashMap.get(key); 23 tmp.val = value; 24 remove(tmp); 25 setHead(tmp); 26 } else { 27 Node node = new Node(key, value); 28 if (mHashMap.size() >= capacity) { 29 // 要把hashMap中的元素也删除 30 mHashMap.remove(end.key); 31 remove(end); 32 } 33 setHead(node); 34 mHashMap.put(key, node); 35 } 36 37 } 38 // 保证node的指向正确 39 public void remove(Node tmp) { 40 if (tmp.pre != null) { 41 tmp.pre.next = tmp.next; 42 } else { 43 head = tmp.next; 44 } 45 46 //双向链表 要保证两个方向的指向正常 47 if (tmp.next != null) { 48 tmp.next.pre = tmp.pre; 49 } else { 50 end = tmp.pre; 51 } 52 53 } 54 // 保证node指向正确 55 public void setHead(Node tmp) { 56 tmp.next = head; 57 tmp.pre = null; 58 if (head != null) { 59 head.pre = tmp; 60 } 61 head = tmp; 62 if (end == null) { 63 end = head; 64 } 65 } 66 public static void main(String[] args) { 67 68 } 69 }
二、字符串
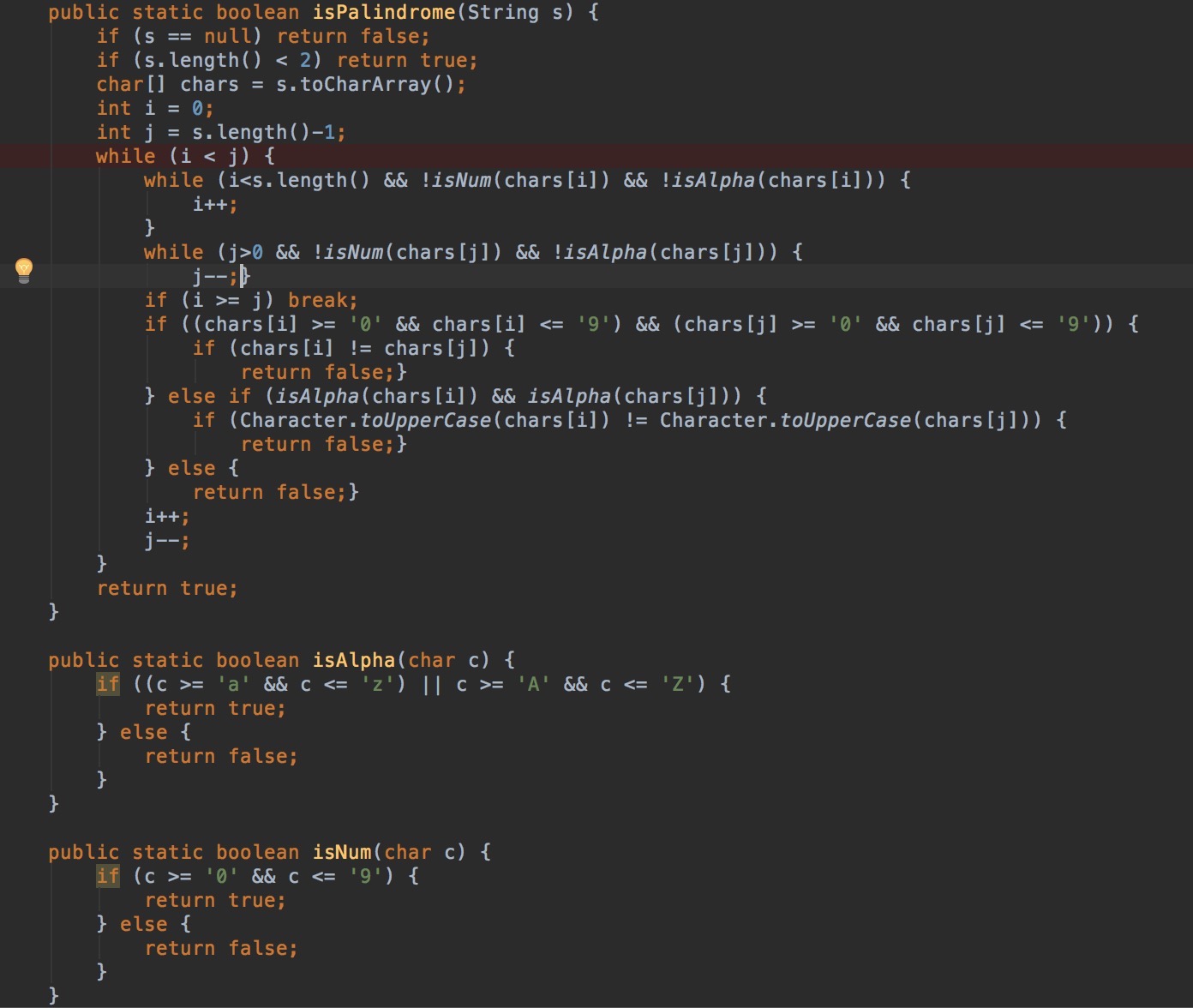
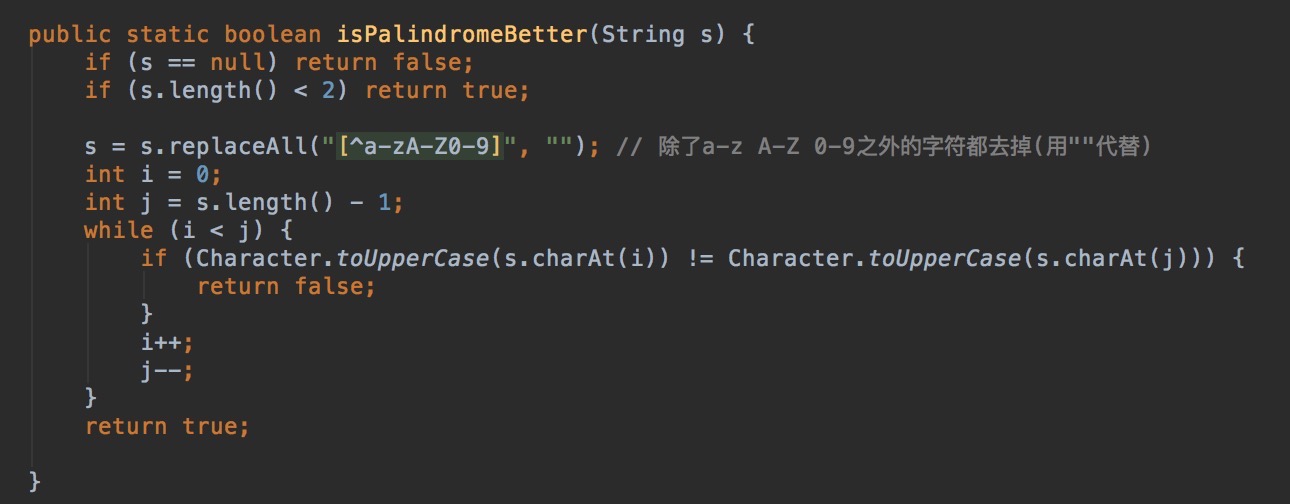
A1:Valid Palindrome ,求一个字符串是否是回文串,字符串中只考虑大小写26个字母以及数组,其他的符号或者空格可以忽略。
分析:
方法一:直接求解,每次取出两个字符,去除无效字符,比较。
方法二:先整理字符串,然后求解。先将取消字符去除,然后求解。
使用系统接口Charccter.toUpperCase以及s.toCharArray.
解:
方法一:
方法二:
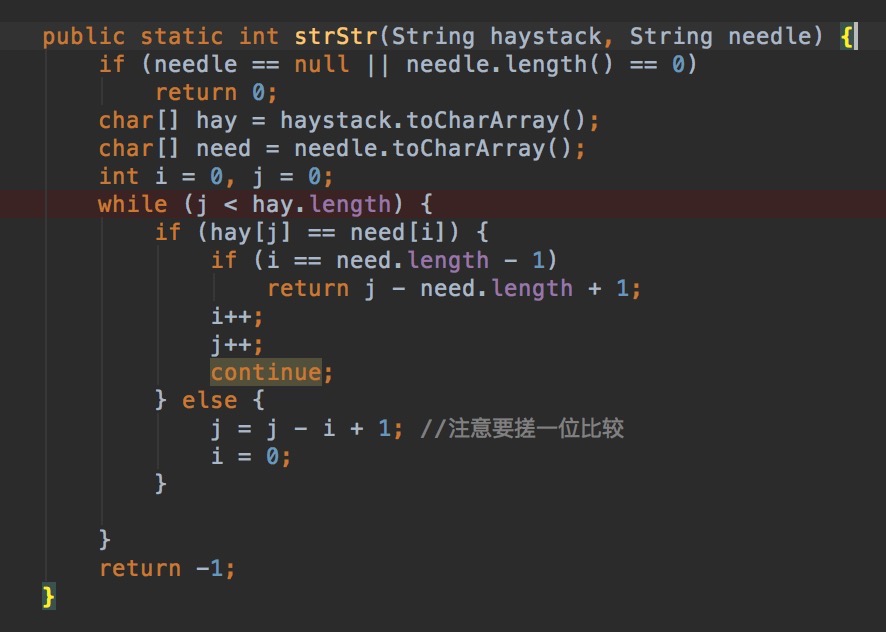
A2:经典题目,Implement strStr() 目标串中查找子串并返回index值,如果没有返回-1.
分析:使用原始的方式,当前不匹配,目标串挪一位比较,直到找到子串index.
解:
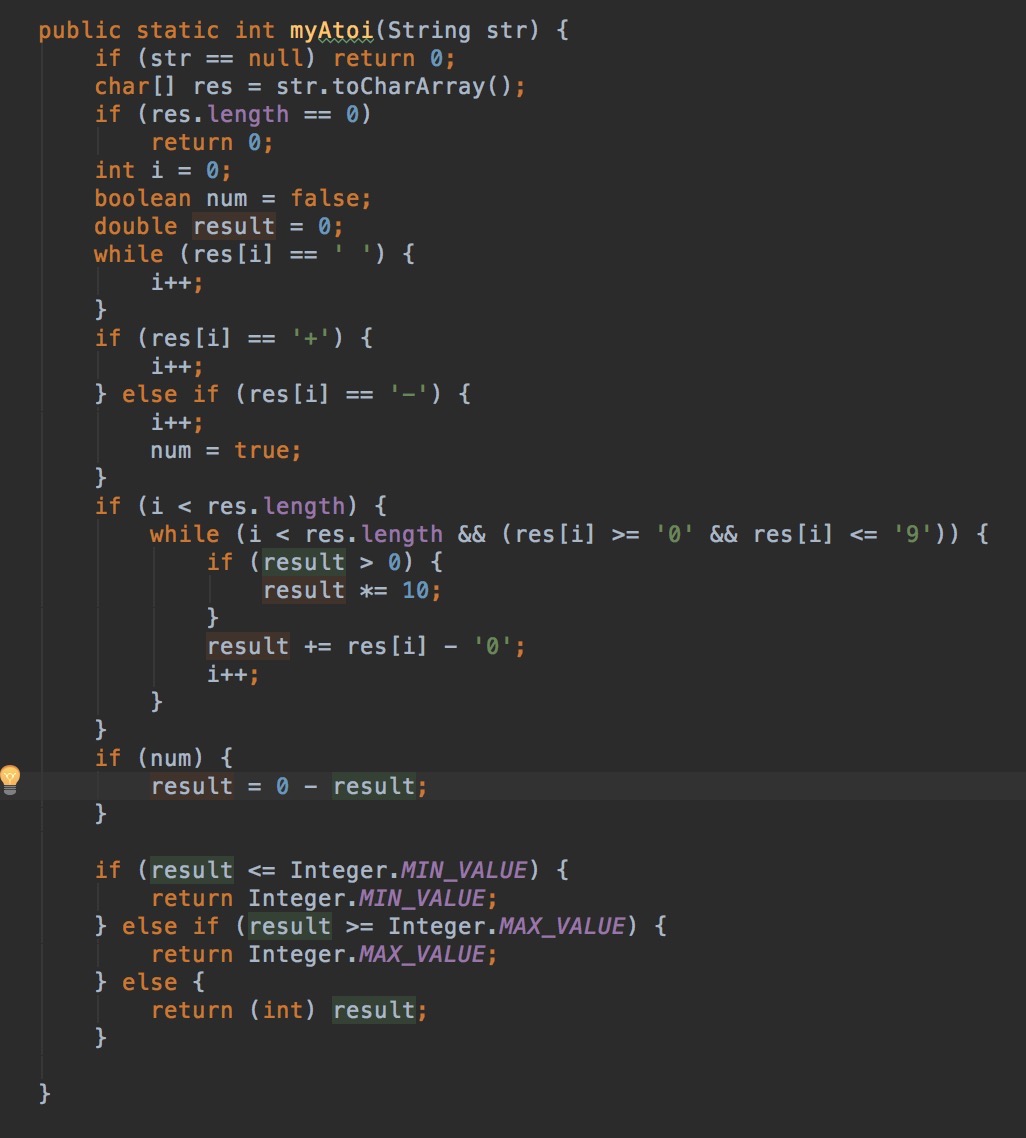
A3:String to Integer (atoi),字符串转化成数字,字符串中遇见非数字字符可直接越过,要考虑情况的比较多,空格开头或者+-号开头的字符串等等。还要考虑下数字的正负。
要求:如果可转换,返回转换整形值,如果不合法字符串,返回0,如果超过INT_MAX、INT_MIN。则返回这两个值。
分析:情况需要考虑的全面一些,还有,返回值需要使用一个范围更大的类型去存储,选择double能通过,long就有各种问题。查询发现,虽然long和double都是64位的,但是double能表示的范围要大于long表示的范围(double是n*2^m(n乘以2的m次方)这种形式存储的,只需要记录n和m两个数就行了,m的值影响范围大,所以表示的范围比long大。但是m越大,n的精度就越小,所以double并不能把它所表示的范围里的所有数都能精确表示出来,而long就可以)。
解:
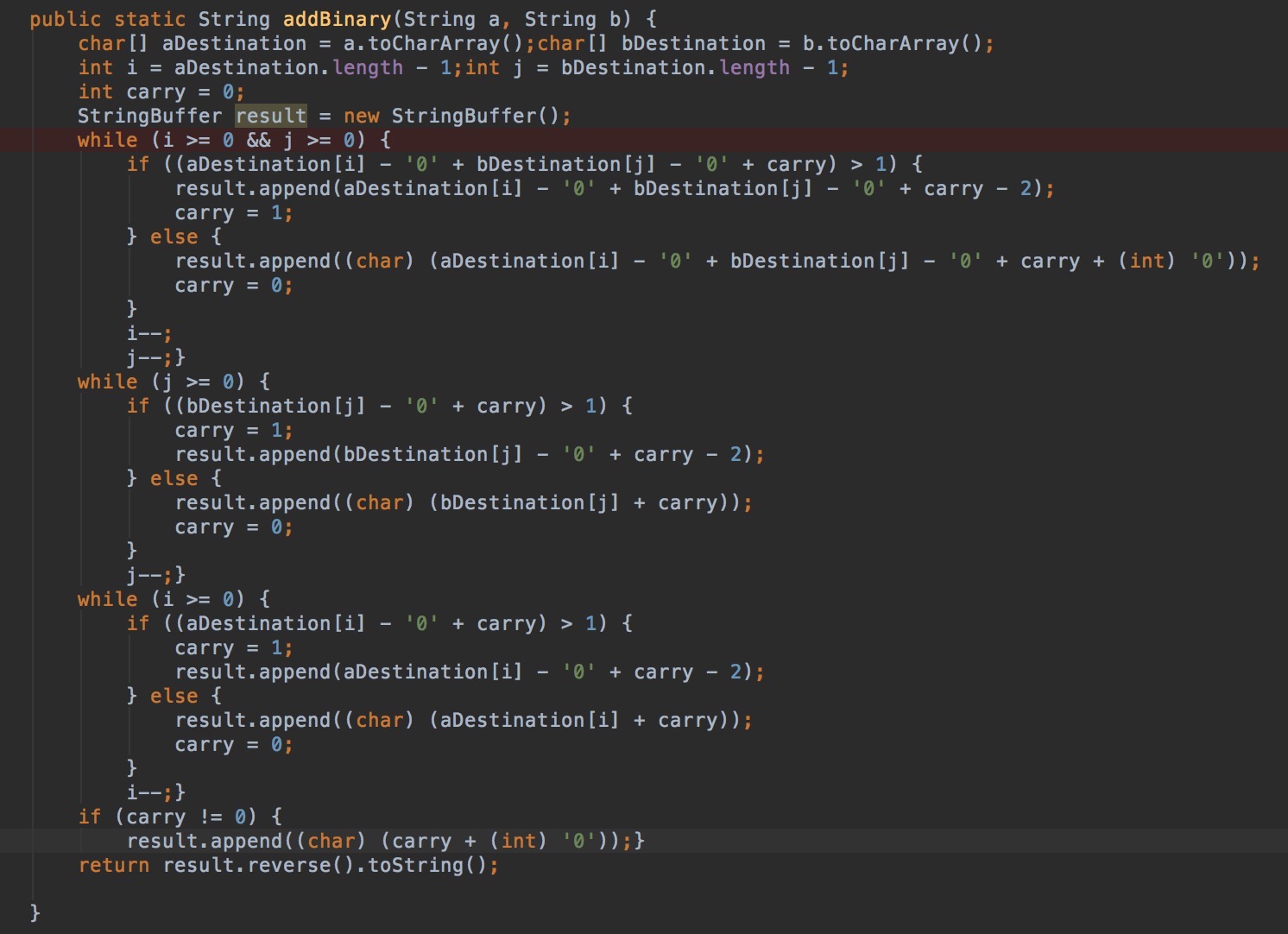
A4:Add Binary, 二进制字符串相加,返回相加结果的二进制字符串。
分析:注意进位,使用StringBuffer, 从后往前相加。一次append到字符串末尾,最后reverse字符串。
解:
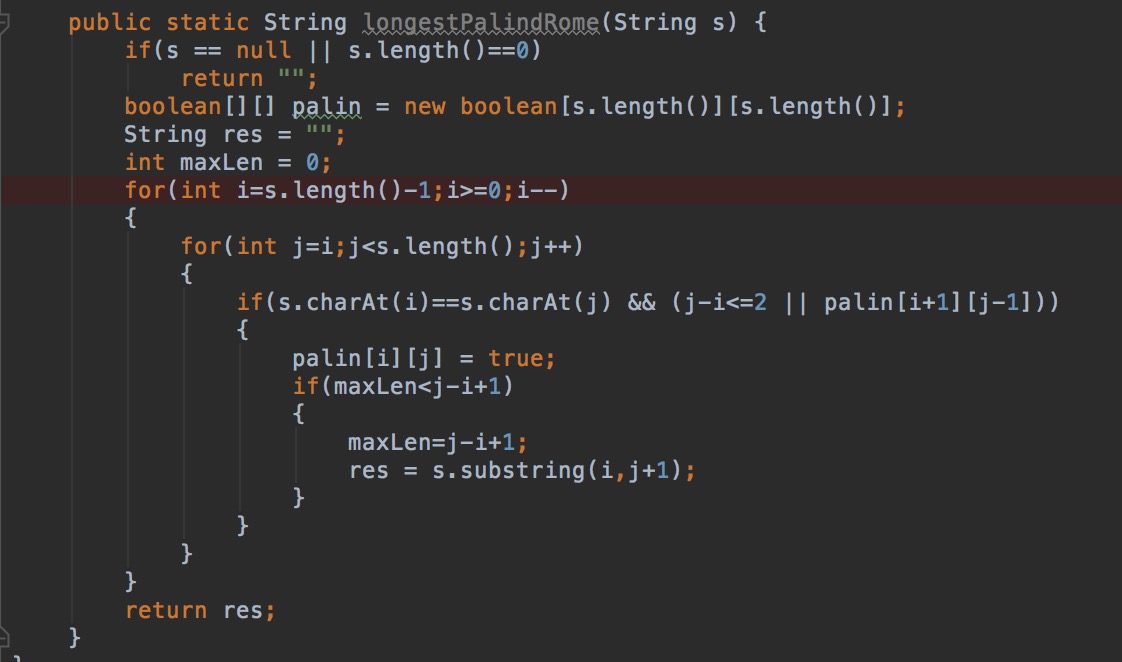
A5:Longest Palindromic Substring
Given a string s, find the longest palindromic substring in s. You may assume that the maximum length of s is 1000.
Example:
Input: "babad" Output: "bab" Note: "aba" is also a valid answer.
Input: "cbbd" Output: "bb"
分析:一种暴力破解法,一种动态规划。
动态规划没想到。
解:

A6: