最近被种草SK-II,本着学工科的严谨态度,决定用数据说话
爬取数据
参数解析
itemId是商品ID, sellerId 是卖家ID, currentPage是当前页码,目标url是https://rate.tmall.com/list_detail_rate.htm?itemId=15332134505&spuId=294841&sellerId=917264765&order=3¤tPage=1
正则解析
1.cnt字符串不要随便换行(否则可能报错:SyntaxError: EOL while scanning string literal),
2.findall(正则规则,字符串) 方法能够以列表的形式返回能匹配的字符串
#coding=utf-8 import re cnt = '"aliMallSeller":False,"anony":True,"appendComment":"","attributes":"","attributesMap":"","aucNumId":"","auctionPicUrl":"","auctionPrice":"","auctionSku":"化妆品净含量:75ml","auctionTitle":"","buyCount":0,"carServiceLocation":"","cmsSource":"天猫","displayRatePic":"","displayRateSum":0,"displayUserLink":"","displayUserNick":"t***凯","displayUserNumId":"","displayUserRateLink":"","dsr":0.0,"fromMall":True,"fromMemory":0,"gmtCreateTime":1504930533000,"goldUser":False,"id":322848226237,"pics":["//img.alicdn.com/bao/uploaded/i3/2699329812/TB2hr6keQ.HL1JjSZFlXXaiRFXa_!!0-rate.jpg"],"picsSmall":"","position":"920-11-18,20;","rateContent":"送了面膜 和晶莹水 skii就是A 不错","rateDate":"2017-09-09 12:15:33","reply":"一次偶然的机会,遇见了亲,一次偶然的机会,亲选择了SK-II,生命中有太多的选择,亲的每一次选择都是一种缘分。让SK-II与您形影不离,任岁月洗礼而秀美如初~每日清晨拉开窗帘迎来的不仅止破晓曙光,还有崭新的自己~【SK-II官方旗舰店Lily】","sellerId":917264765,"serviceRateContent":"","structuredRateList":[],"tamllSweetLevel":3,"tmallSweetPic":"tmall-grade-t3-18.png","tradeEndTime":1504847657000,"tradeId":"","useful":True,"userIdEncryption":"","userInfo":"","userVipLevel":0,"userVipPic":""' nickname = [] regex = re.compile('"displayUserNick":"(.*?)"') print regex nk = re.findall(regex,cnt) for i in nk: print i nickname.extend(nk) print nickname ak = re.findall('"auctionSku":"(.*?)"',cnt) for j in ak: print j rc = re.findall('"rateContent":"(.*?)"',cnt) for n in rc: print n rd = re.findall('"rateDate":"(.*?)"',cnt) for m in rd: print m
输出:

完整源码
参考:http://www.jianshu.com/p/632a3d3b15c2
#coding=utf-8 import requests import re import sys reload(sys) sys.setdefaultencoding('utf-8') #urls = [] #for i in list(range(1,500)): # urls.append('https://rate.tmall.com/list_detail_rate.htm?itemId=15332134505&spuId=294841&sellerId=917264765&order=1¤tPage=%s'%i) tmpt_url = 'https://rate.tmall.com/list_detail_rate.htm?itemId=15332134505&spuId=294841&sellerId=917264765&order=1¤tPage=%d' urllist = [tmpt_url%i for i in range(1,100)] #print urllist nickname = [] auctionSku = [] ratecontent = [] ratedate = [] headers = '' for url in urllist: content = requests.get(url).text nk = re.findall('"displayUserNick":"(.*?)"',content) #findall(正则规则,字符串) 方法能够以列表的形式返回能匹配的字符串 #print nk nickname.extend(nk) auctionSku.extend(re.findall('"auctionSku":"(.*?)"',content)) ratecontent.extend(re.findall('"rateContent":"(.*?)"',content)) ratedate.extend(re.findall('"rateDate":"(.*?)"',content)) print (nickname,ratedate) for i in list(range(0,len(nickname))): text =','.join((nickname[i],ratedate[i],auctionSku[i],ratecontent[i]))+' ' with open(r"C:UsersHPDesktopcodesDATASK-II_TmallContent.csv",'a+') as file: file.write(text+' ') print("写入成功")
注:url每次遍历,正则匹配的数据都不止一个,所以使用extend追加而不是append
输出:
数据分析
1.要不要买——评论分析
import pandas as pd from pandas import Series,DataFrame import jieba from collections import Counter df = pd.read_csv(r'C:/Users/HP/Desktop/codes/DATA/SK-II_TmallContent.csv',encoding='gbk') #否则中文乱码 #print df.columns df.columns = ['useName','date','type','content'] #print df[:10] tlist = Series.as_matrix(df['content']).tolist() text = [i for i in tlist if type(i)!= float] #if type(i)!= float一定得加不然报错 text = ' '.join(text) #print text wordlist_jieba = jieba.cut(text,cut_all=True) stoplist = {}.fromkeys([u'的', u'了', u'是',u'有']) #自定义中文停词表,注意得是unicode print stoplist wordlist_jieba = [i for i in wordlist_jieba if i not in stoplist] #and len(i) > 1 #print u"[全模式]: ", "/ ".join(wordlist_jieba) count = Counter(wordlist_jieba) #统计出现次数,以字典的键值对形式存储,元素作为key,其计数作为value。 result = sorted(count.items(), key=lambda x: x[1], reverse=True) #key=lambda x: x[1]在此表示用次数作为关键字 for word in result: print word[0], word[1] from pyecharts import WordCloud data = dict(result[:100]) wordcloud = WordCloud('高频词云',width = 800,height = 600) wordcloud.add('ryana',data.keys(),data.values(),word_size_range = [30,300]) wordcloud
输出:

好用的频率占据榜首,只是不明白为什么要切分
2.买什么——类型分析
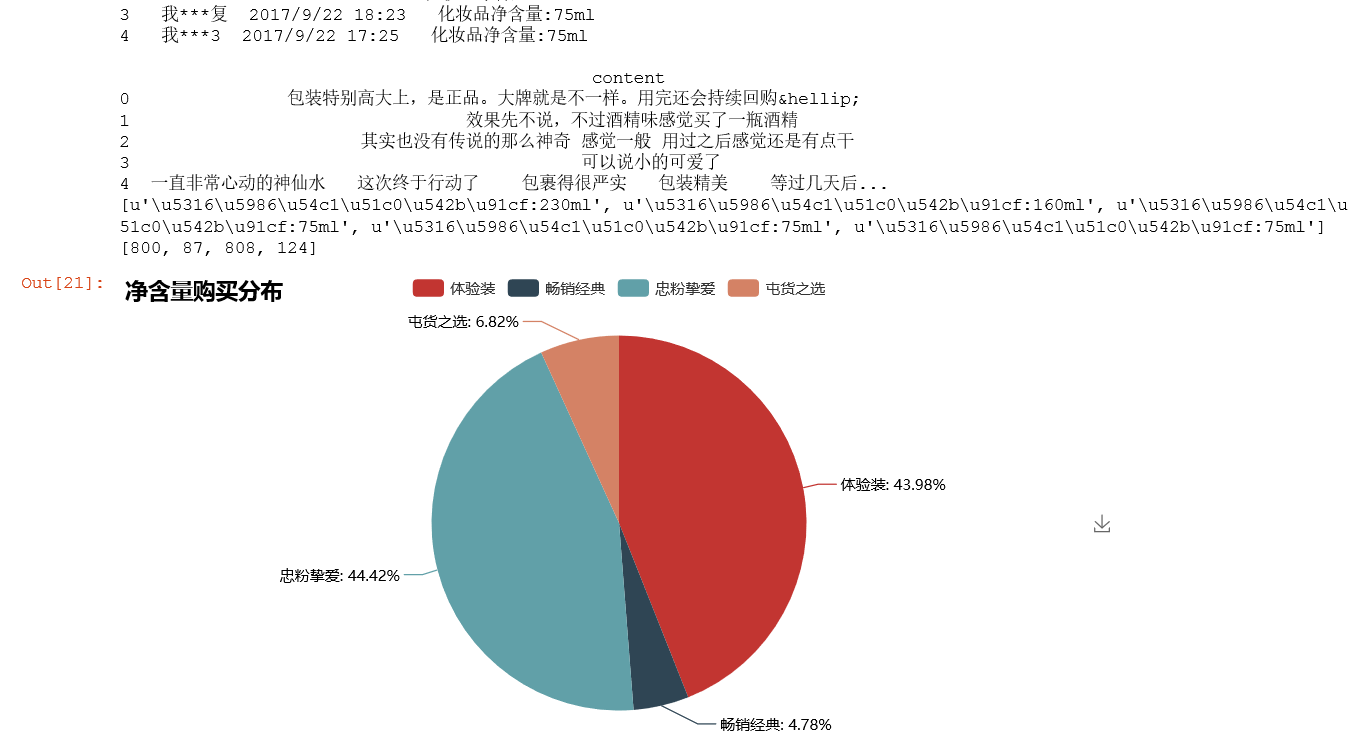
import pandas as pd from pandas import Series,DataFrame df = pd.read_csv(r'C:/Users/HP/Desktop/codes/DATA/SK-II_TmallContent.csv',encoding='gbk') #否则中文乱码 #print df.columns df.columns = ['useName','date','type','content'] print df[:5] from pyecharts import Pie pie = Pie('净含量购买分布') v = df['type'].tolist() print v[:5] #n1 = v.count(u'u5316u5986u54c1u51c0u542bu91cf:230ml') n1 = v.count(u'化妆品净含量:75ml') n2 = v.count(u'化妆品净含量:160ml') n3 = v.count(u'化妆品净含量:230ml') n4 = v.count(u'化妆品净含量:330ml') #print n1,n2,n3,n4 #800 87 808 124 N = [n1,n2,n3,n4] #print N #[800,87,808,124] attr = ['体验装','畅销经典','忠粉挚爱','屯货之选'] pie.add('ryana',attr,N,is_label_show = True) pie
输出: