- #remoting:远程通讯基础,提供对多种NIO框架抽象封装,包括“同步转异步”和“请求-响应”模式的信息交换方式。
- #cluster: 服务框架核心,提供基于接口方法的远程过程调用,包括多协议支持,并提供软负载均衡和容错机制的集群支持。
-
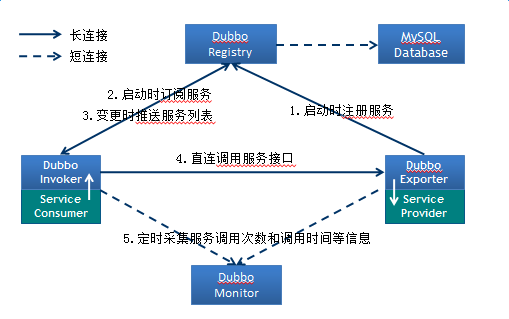
#registry: 服务注册中心,使服务消费方能动态的查找服务提供方,使地址透明,使服务提供方可以平滑增加或减少机器。

当服务调用失败时(比如响应超时),根据我们的业务不同,可以使用不同的策略来应对这种失败。比如我们调用的服务是一个查询服务,不会修改数据库,那么可以给该服务设置容错方式为failover <失败重试方式>,当调用失败时,自动切换到其他服务提供者去调用,当失败次数超过指定重试次数,那么就抛出错误。如果服务是更新数据的服务,那就不能使用失败重试的方式了, 因为这样可能产生数据重复修改的问题,比如调用提供者A的插入用户方法,但是该方法业务逻辑复杂,执行过程很慢,导致响应超时,那么此时如果再去调用另外一个服务提供者的插入用户方法,将会又重复插入同一个用户。对于这种类型的服务,可以使用容错方式为failfast,如果第一次调用失败,立即报错,不需要重试。
另外还有下面几种容错类型,failsafe 出现错误,直接忽略,不重试也不报错; failback 失败后不报错,会将该失败请求,定时重发,适合消息通知类型的服务。forking,并行调用多个服务器,只要在某一台提供者上面成功,那么方法返回,适合实时性要求较高的查询服务,但是要牺牲性能。因为每台服务器会做同一个操作;broadcast 广播调用所有服务提供者,逐个调用,任意一台报错则报错。适合与更新每台提供者上面的缓存,这种类型的服务。
案例:我们在点我吧的APP消息推送就是采用的failback方式,点我吧的短信通知则采用的是failover方式。

如上图所示,是环形的hash空间,按照常用的hash算法来将对应的key哈希到一个具有2^32次方个桶的空间中,即0~(2^32)-1的数字空间中。现在我们可以将这些数字头尾相连,想象成一个闭合的环形。我们把数据通过hash算法处理后映射到环上,现在我们将object1、object2、object3、object4四个对象通过特定的Hash函数计算出对应的key值,然后散列到Hash环上。Hash(object1) = key1;Hash(object2) = key2;Hash(object3) = key3;Hash(object4) = key4;


1 public interface SolrSearchService { 2 String search(String collection, String q, ResponseType type, int start, int rows); 3 public enum ResponseType {JSON, XML} 4 }

1 package org.shirdrn.platform.dubbo.service.rpc.server; 2 3 import java.io.IOException; 4 import java.util.HashMap; 5 import java.util.Map; 6 7 import org.apache.commons.logging.Log; 8 import org.apache.commons.logging.LogFactory; 9 import org.shirdrn.platform.dubbo.service.rpc.api.SolrSearchService; 10 import org.shirdrn.platform.dubbo.service.rpc.utils.QueryPostClient; 11 import org.springframework.context.support.ClassPathXmlApplicationContext; 12 13 public class SolrSearchServer implements SolrSearchService { 14 15 private static final Log LOG = LogFactory.getLog(SolrSearchServer.class); 16 private String baseUrl; 17 private final QueryPostClient postClient; 18 private static final Map<ResponseType, FormatHandler> handlers = new HashMap<ResponseType, FormatHandler>(0); 19 static { 20 handlers.put(ResponseType.XML, new FormatHandler() { 21 public String format() { 22 return "&wt=xml"; 23 } 24 }); 25 handlers.put(ResponseType.JSON, new FormatHandler() { 26 public String format() { 27 return "&wt=json"; 28 } 29 }); 30 } 31 public SolrSearchServer() { 32 super(); 33 postClient = QueryPostClient.newIndexingClient(null); 34 } 35 public void setBaseUrl(String baseUrl) { 36 this.baseUrl = baseUrl; 37 } 38 public String search(String collection, String q, ResponseType type, 39 int start, int rows) { 40 StringBuffer url = new StringBuffer();
url.append(baseUrl).append(collection).append("/select?").append(q);
url.append("&start=").append(start).append("&rows=").append(rows); 41 url.append(handlers.get(type).format()); 42 LOG.info("[REQ] " + url.toString()); 43 return postClient.request(url.toString()); 44 } 45 interface FormatHandler { 46 String format(); 47 } 48 public static void main(String[] args) throws IOException { 49 String config = SolrSearchServer.class.getPackage().getName().replace('.', '/') + "/search-provider.xml"; 50 ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext(config); 51 context.start(); 52 System.in.read(); 53 } 54 }
1 <?xml version="1.0" encoding="UTF-8"?> 2 <beans xmlns="http://www.springframework.org/schema/beans" 3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:dubbo="http://code.alibabatech.com/schema/dubbo" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd 4 http://code.alibabatech.com/schema/dubbo http://code.alibabatech.com/schema/dubbo/dubbo.xsd"> 5 <dubbo:application name="search-provider" /> 6 <dubbo:registry address="zookeeper://slave1:2188?backup=slave3:2188,slave4:2188" /> 7 <dubbo:protocol name="dubbo" port="20880" /> 8 <bean id="searchService" class="org.shirdrn.platform.dubbo.service.rpc.server.SolrSearchServer"> 9 <property name="baseUrl" value="http://nginx-lbserver/solr-cloud/" /> 10 </bean> 11 <dubbo:service interface="org.shirdrn.platform.dubbo.service.rpc.api.SolrSearchService" ref="searchService" /> 12 </beans>
上面,Dubbo服务注册中心指定ZooKeeper的地址:zookeeper://slave1:2188?backup=slave3:2188,slave4:2188,使用Dubbo协议。配置服务接口的时候,可以按照Spring的Bean的配置方式来配置,注入需要的内容,我们这里指定了搜索集群的Nginx反向代理地址http://nginx-lbserver/solr-cloud/。
/* * 使用Dubbo服务接口 */ // 首先,在API包中定义服务接口,同时部署于Provider端和Consumer端 public interface HelloService { public String sayHello(); } // 其次,在服务端的Provider实现代码 public class HelloServiceImpl implements HelloService { public String sayHello() { return "Welcome to dubbo!"; } } // 配置:提供者暴露服务;消费者消费服务 /*provider端服务实现类*/ <bean id="helloService" class="com.alibaba.hello.impl.HelloServiceImpl" /> /*provider端暴露服务*/ <dubbo:service interface="com.alibaba.hello.HelloService" version="1.0.0" ref="helloService"/> /*consumer端引入服务*/ <dubbo:reference id="helloService" interface="com.alibaba.hello.HelloService" version="1.0.0" /> /*consumer端使用服务*/ <bean id="xxxAction" class="com.alibaba.xxx.XxxAction" ><property name="helloService" ref="helloService" /></bean>
