自动求导

链式法则,如果扩展到向量,最最重要的还是看形状。
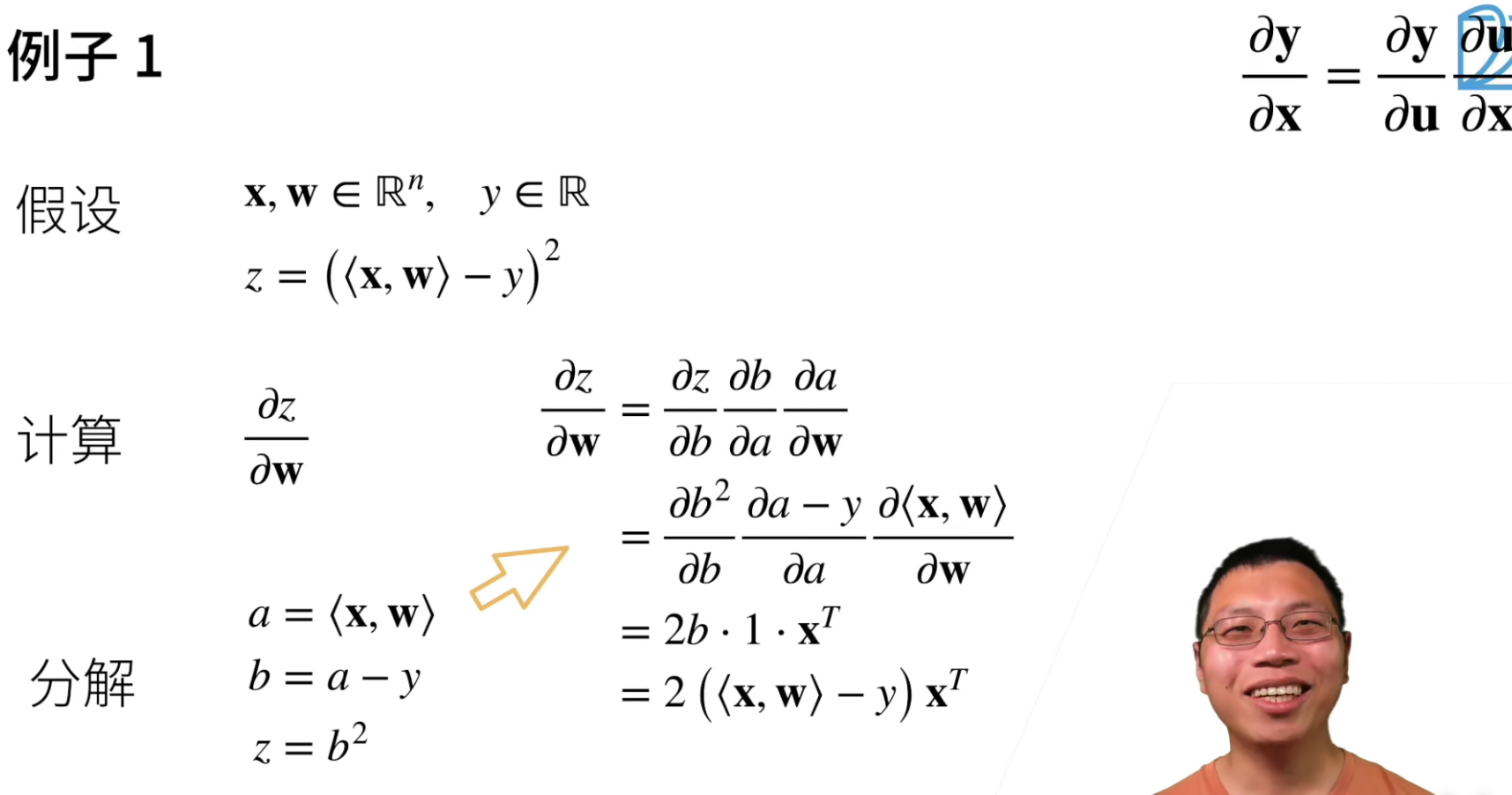
<x,w>这是内积的写法。


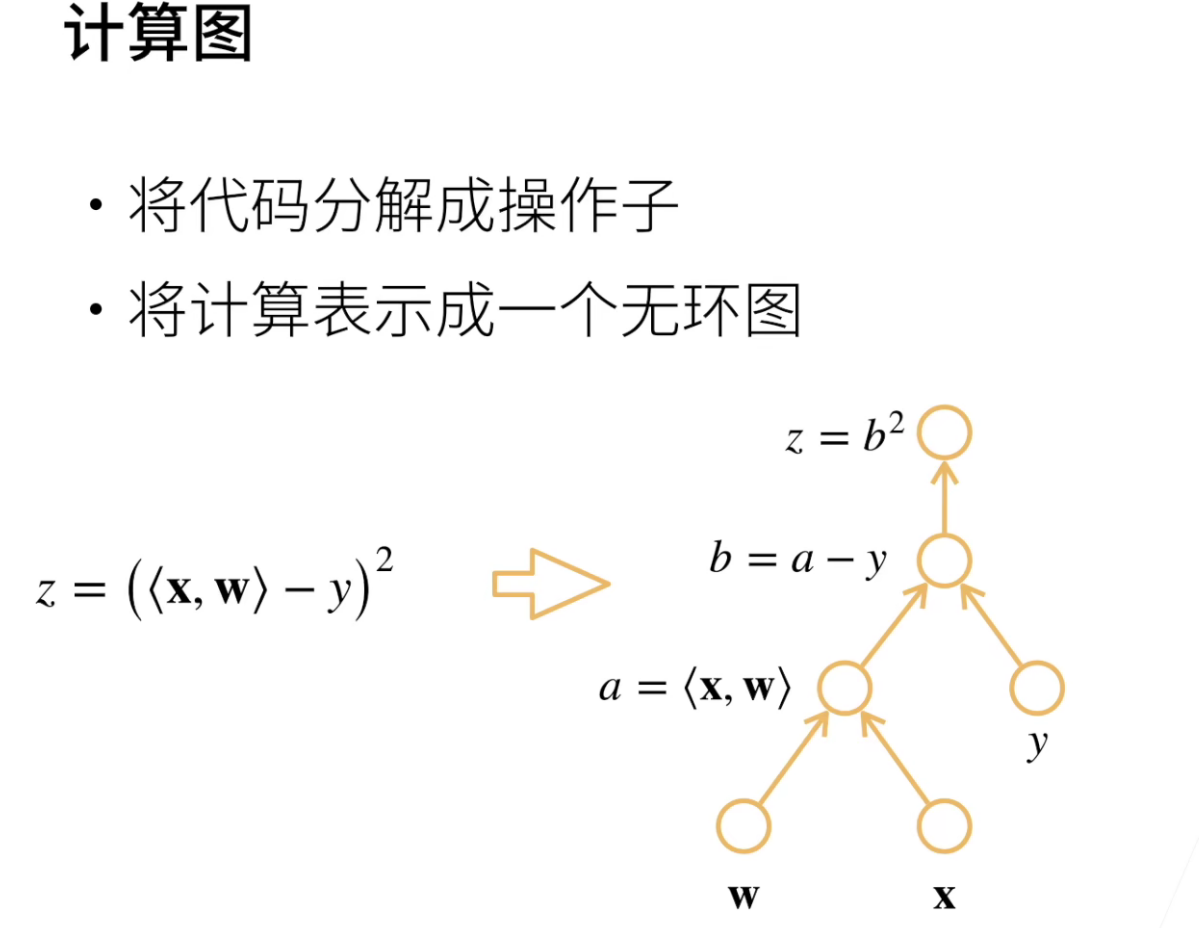
自动求导涉及到一个计算图的概念,虽然Pytorch不用要求大家理解计算图,但是理解了对使用TensorFlow等都是有好处的。
计算图其实本质上就和刚刚求导链式法则的过程。

显示构造,就是先构造好这个公式,然后再带入数值计算,一般数学上都是属于显示构造。


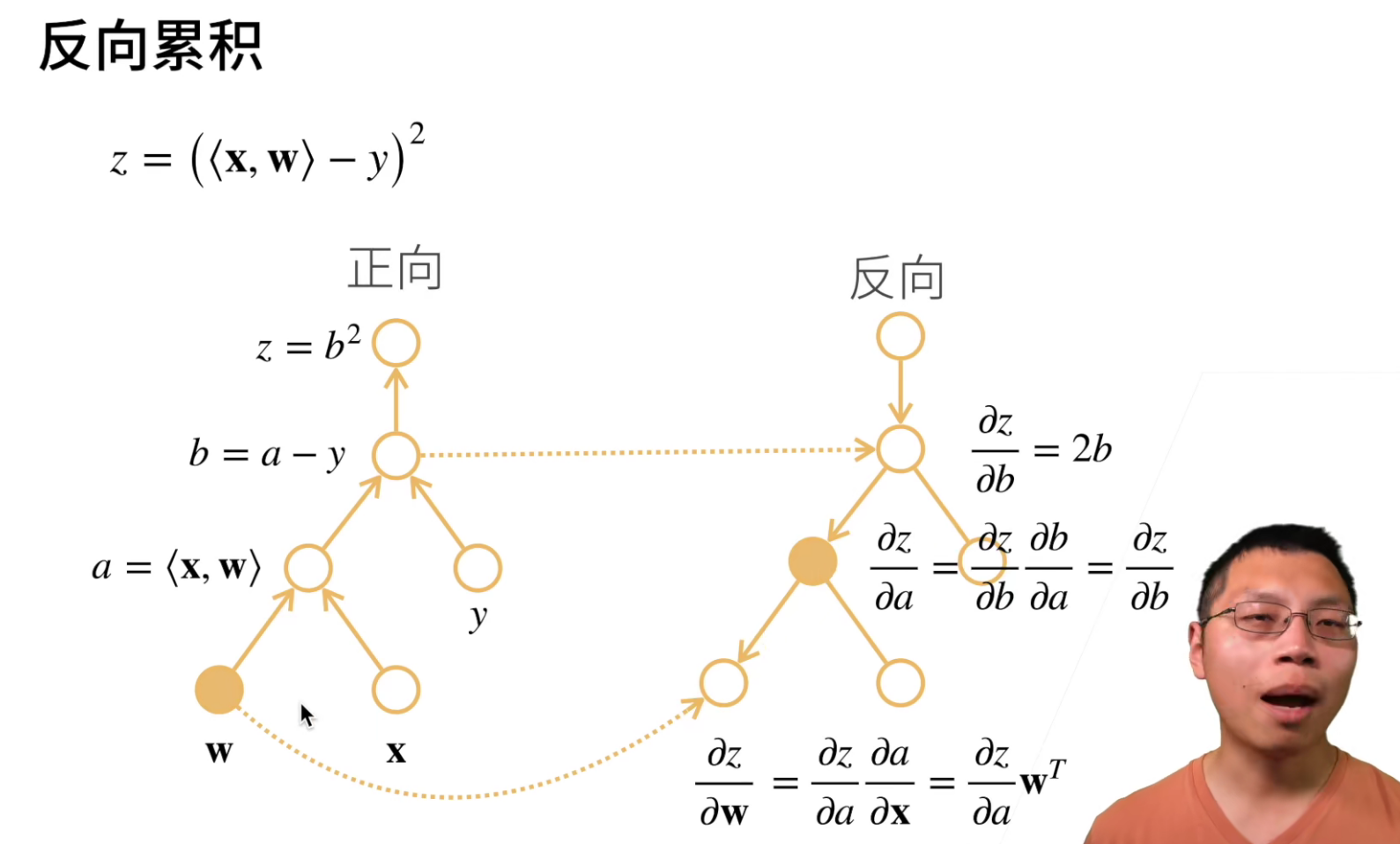
正向累积就是正常计算,反向传播是从结果不停的反向进行求导。
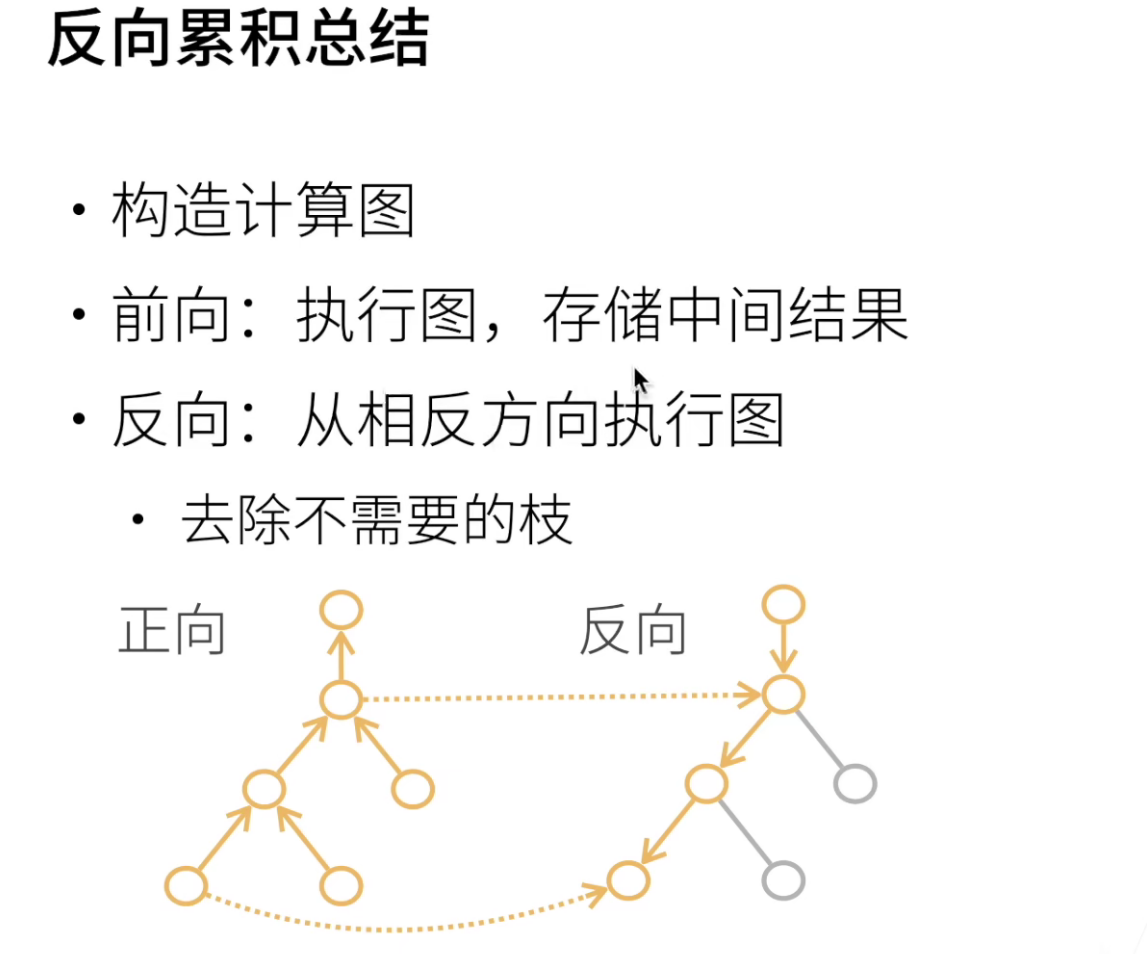

反向从根节点向下扫,可以保证每个节点只扫一次;
正向从叶节点向上扫,会导致上层节点可能需要被重复扫多次(正向中子节点比父节点先计算,因此也无法像反向那样把本节点的计算结果传给每一个子节点)
自动求导实现
操作总结
import torch
x = torch.arange(4.)
# 等价于 x = torch.arange(4.,requires_grad=True)
x.requires_grad_(True) # 需要存储中间结果
print(x.grad) # 查看x的梯度,默认为None
y = 2*torch.dot(x,x) # 点称
y # tensor(28., grad_fn=<MulBackward0>)
y.backward() # 对y进行反向传播
x.grad # 查看BP得到的梯度
# y=2x^2 y'=2x,可以判断BP得到的梯度是否是对的
4*x == x.grad
x.grad_zero_() # Pytorch的梯度会累积,这里是将0写入梯度中
y = x.sum() # sum() 相当于点乘一个全为1的向量
y.backward()
x.grad
x.grad_zero_()
y = x*x
# x*x == sum(y·y)
y.sum().backward()
x.grad
# 将计算移动到计算图之外
x.grad_zero_()
y = x*x
u = y.detach()
z = u*x
z.sum().backward()
x.grad,x.gard==u
# 及时构建函数的计算图需要通过Python控制流,我们仍然可以计算得到变量的梯度
def f(a):
b = a * 2
while b.norm() < 1000:
b = b * 2
if b.sum() > 0:
c = b
else:
c = 100 * b
return c
# size=() 标量
# a是一个随机变量,并且需要记录梯度
a = torch.randn(size=(), requires_grad=True)
d = f(a)
d.backward()
# f()可以理解成是一个计算图的流程,最终得到d
# 因为是标量,所以可以用斜率来验证得到的梯度是否是正确的
a.grad == d / a
QA
- PPT上的显示构造和隐式构造为什么看起来差不多?
显示构造:把整个计算图都先设计完成,然后再给值
隐式构造:就直接写程序流程,然后框架会在后台进行计算图的构建
实际使用过程中,显示构造计算图会麻烦很多!
- 为什么深度学习中一般对标量求导而不是对矩阵求导或者向量?如果我的loss是包含向量或者矩阵,那求导之前是不是要把他们变成标量?
loss通常是一个标量,精度也好,很多机器学习的loss都是一个标量,如果loss是一个向量的loss的话,那就会变得很麻烦。向量向下走就是就是矩阵,矩阵往下走四维矩阵,网络程度一深,那么就会成为一个非常大的张量。
- 多个loss分别反向的时候是不是需要累积梯度?
是的,如果后面你的神经网络有多个损失函数的话,你是需要做梯度累加的,这也是Pytorch默认累加梯度的一个理由。