传输层篇 | 03
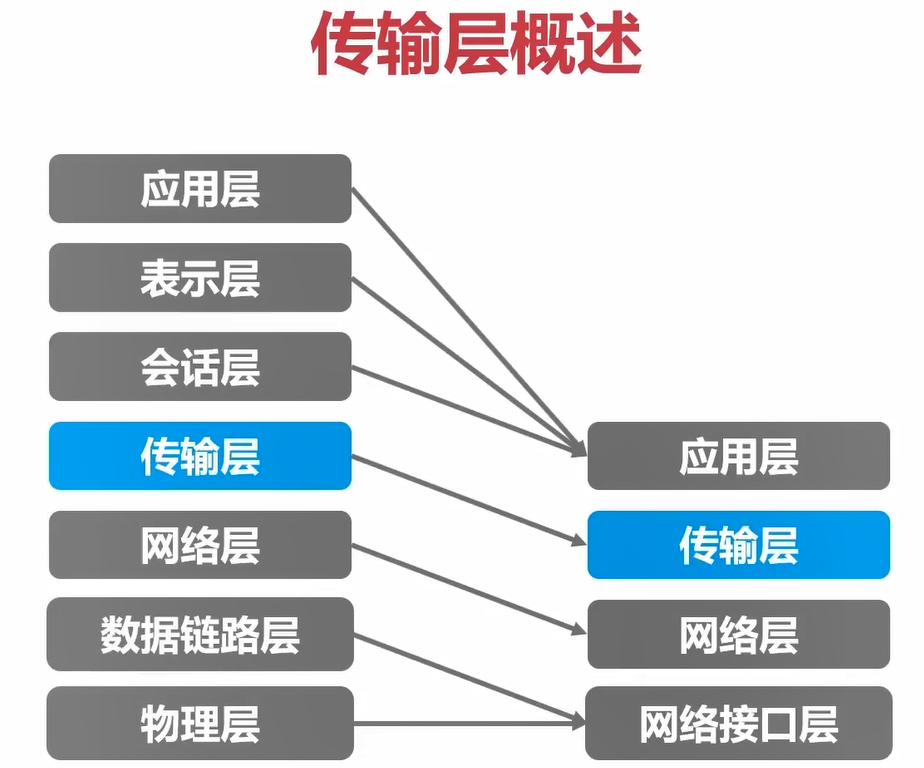
如果从信息的处理角度来看,主要使用应用层提供通信服务的。我们平时对网络进行编程的时候,很多时候都是直接对接传输层(使用传输层的接口来进行网络的编程)。因此我们说传输层是用户功能的最底层,但是属于面向通信部分的最高层。
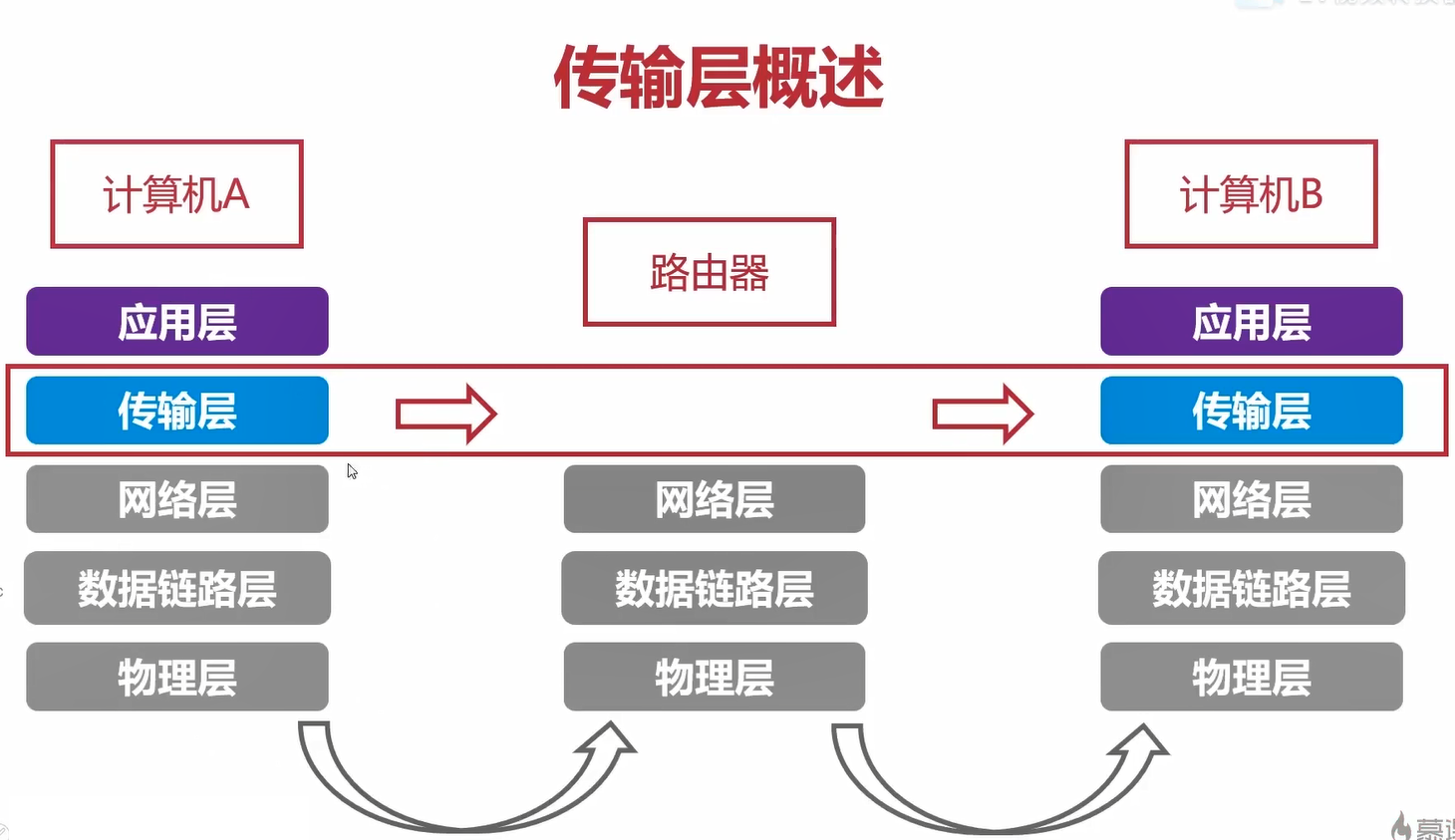
传输层的工作位置在计算机中。
对于网络中的路由器,并没有传输层在工作。也就是在通信的时候,传输层是工作在终端的设备。
传输层的作用:管理端到端的通信连接。

网络层的作用就是解决好虚拟的互联网络如何处理数据的路由,决定数据的走向。
网络层已经解决好了数据走向问题,那么在传输层就不关心了,重点关心的是两个端之间是如何进行通信的。
传输层的作用就是让两个进程建立可以在网络中建立通信。

操作系统中讲解的进程之间的通信是本机之间的进程通信,不能跨网络,跨设备。
计算机网络中将的进程通信是可以跨网络,跨设备的。
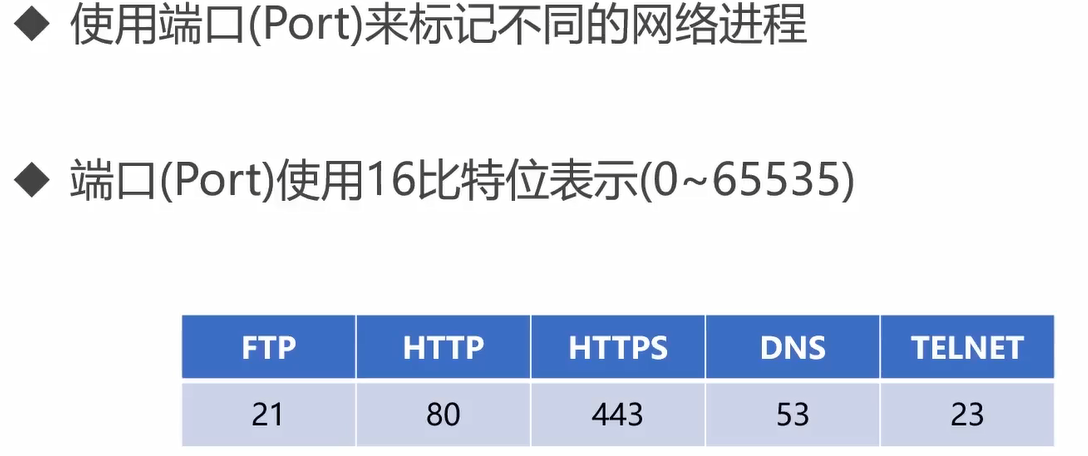
在计算机网络的传输层中需要引入端口的概念,用来标记不同的网络进程。
端口使用16bit表示(0~65535)


传输层主要就是学习两个协议: TCP & UDP
UDP协议详解
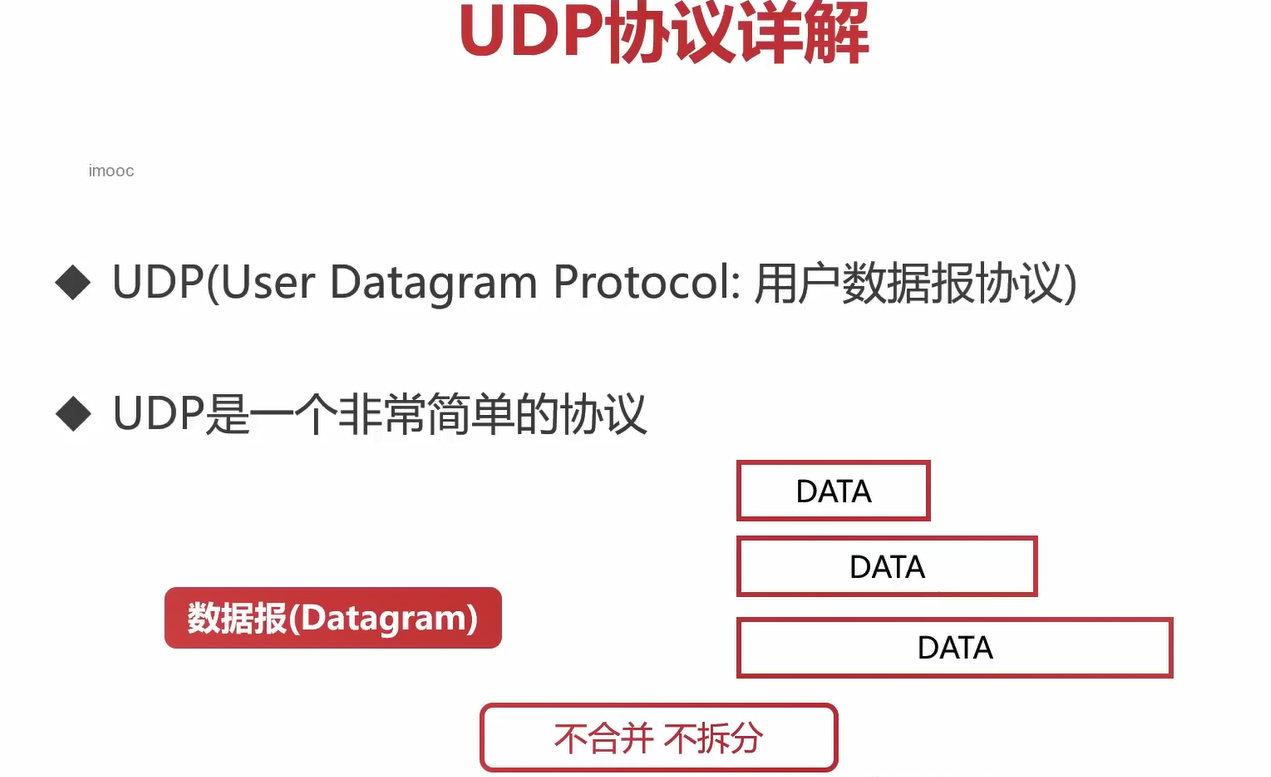
UDP相对于TCP来说是一个简单的协议。
UDP中比较重要的概念是数据表(Datagram)。数据报是UDP协议的一个重要特征。
数据报:应用层传输过来的完整数据。 UDP不会对该数据进行合并,也不会进行拆分,就是加上一个UDP头部就向下传递给网络层了。
UDP的数据长度主要由应用层传输的数据长度决定的,应用层传输的数据长度长,那么UDP的数据就长(应该仅仅加个UDP头部,不做任何其他处理)。
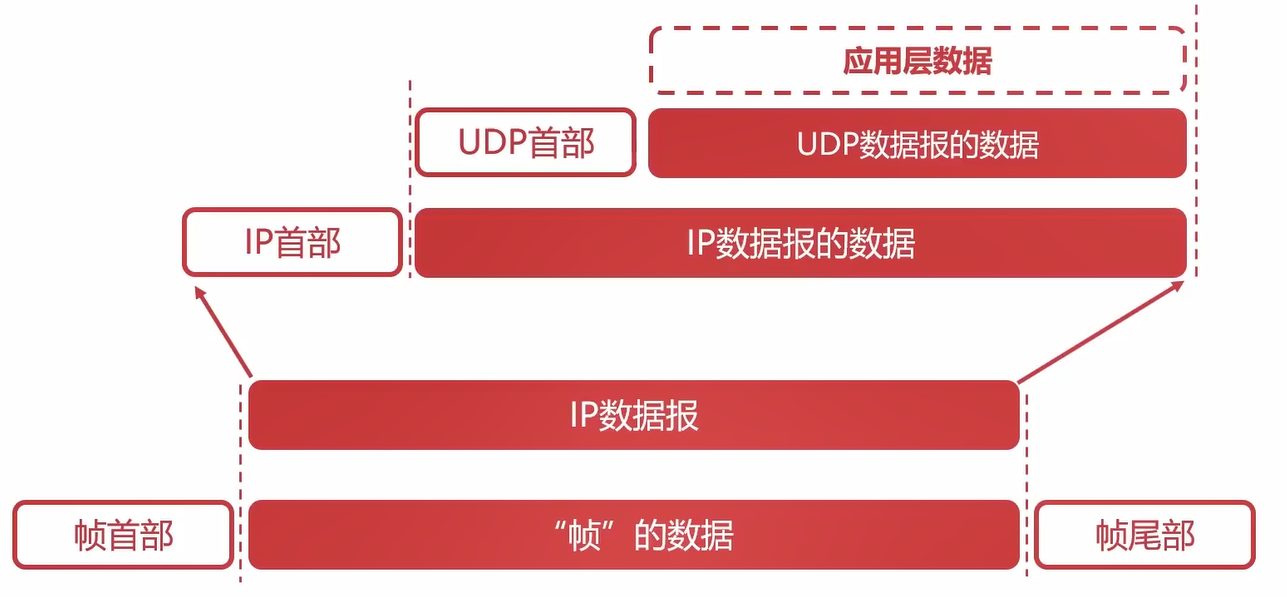
可以看出在各个网络层数据报的形式。
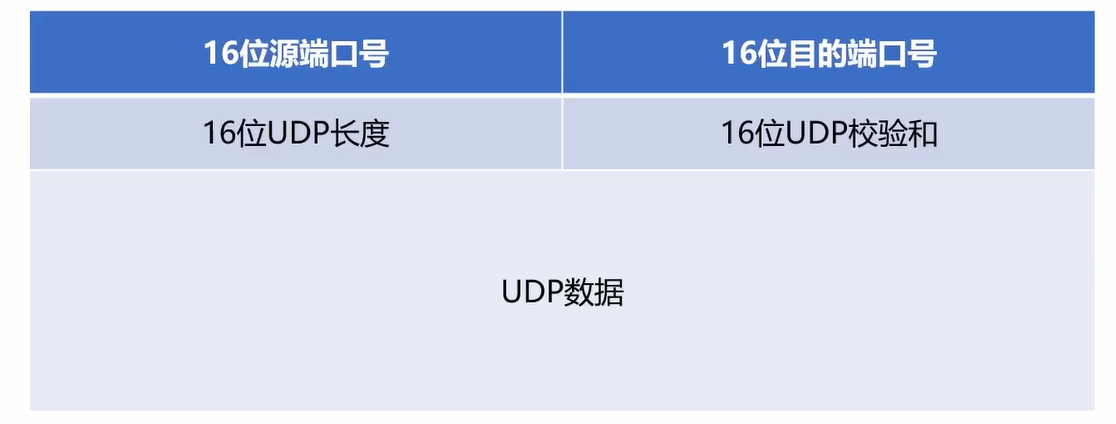
上图就是UDP数据报的格式。
可以看到,UDP的头部由四部分组成,将其和IP头部比对,UDP是一个简单的头部。


由于UDP的头部很简单,也没有办法保证数据会一定发送到,而且就算数据丢失了,也没有办法感知到。

UDP是面向报文传输的,它不会对报文进行任何的处理。而是直接塞进UDP的数据中,然后就发送出去了。
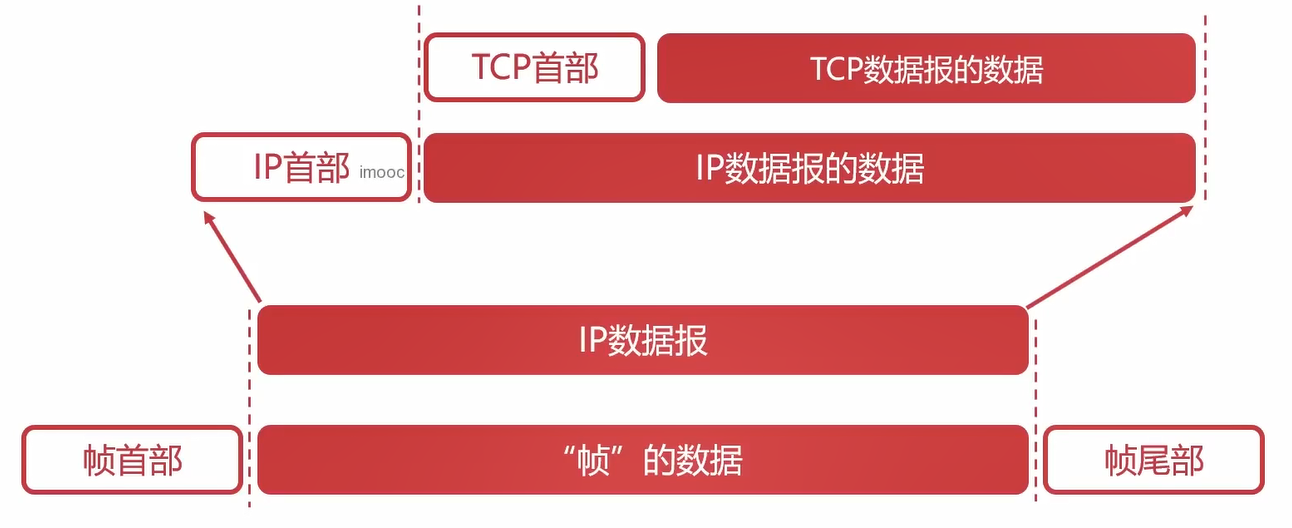
与之对应的TCP,这个后面会讲解。

上面就是UDP的特点
- UDP是无连接的
- UDP不能保证可靠的交付
- UDP是面向报文传输的
- UDP没有拥塞控制
- UDP的首部开销很小
TCP协议详解


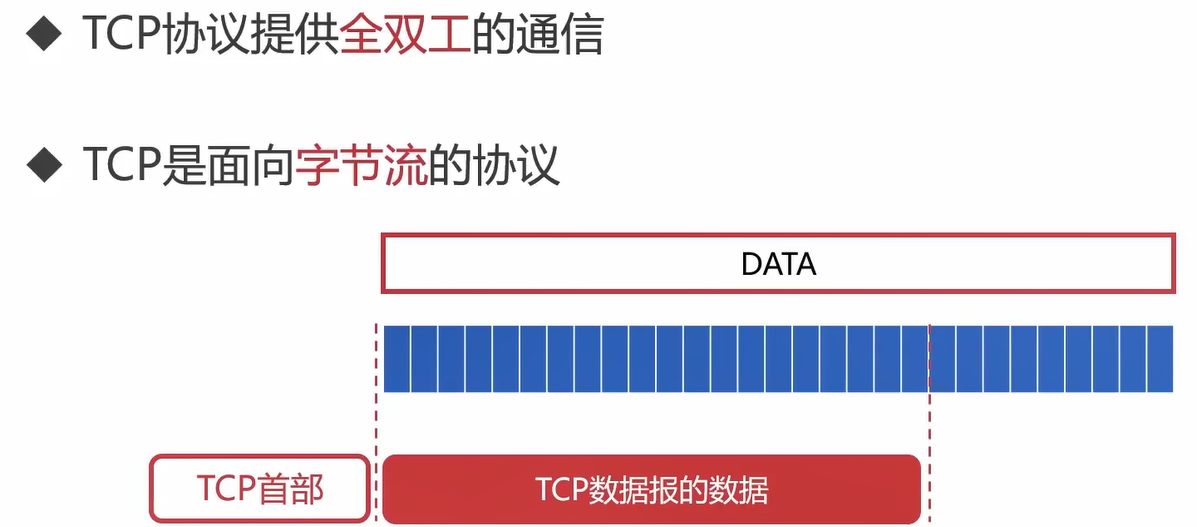
字节流:流入进程或流出进程的字节序列。
从应用层传输下来的数据,UDP将其看成是一块数据,而TCP不见其看成是一块数据,而是会将其拆分,看作是一系列的字节流。TCP不是面向一整块数据(面向数据报)而是面向一个字节一个字节来处理的。
所以在TCP中,可能先取出数据的某一段来进行传输,然后剩下的数据在放到第二个TCP报文来进行传输。
TCP会对用户的数据进行拆分和合并操作,以保证数据可以更好的传输出去。
上面就是TCP的五个特点(对比UDP来写)
- TCP是有连接的
- TCP提供可靠的交付
- TCP是面向字节流的
- TCP有拥塞控制
- TCP首部开销比较大
- TCP是全双工通信
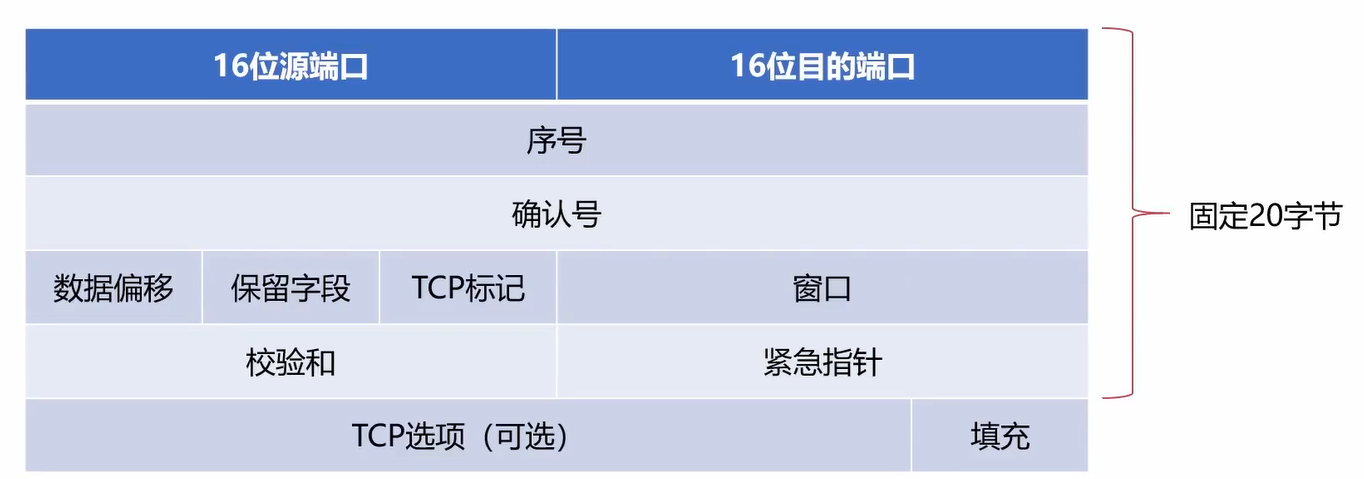
除了可选的,TCP头部的固定长度是20字节。

TCP给每一个字节都编号了,然后序号这里存储的就是这次TCP报文第一字节的序号。
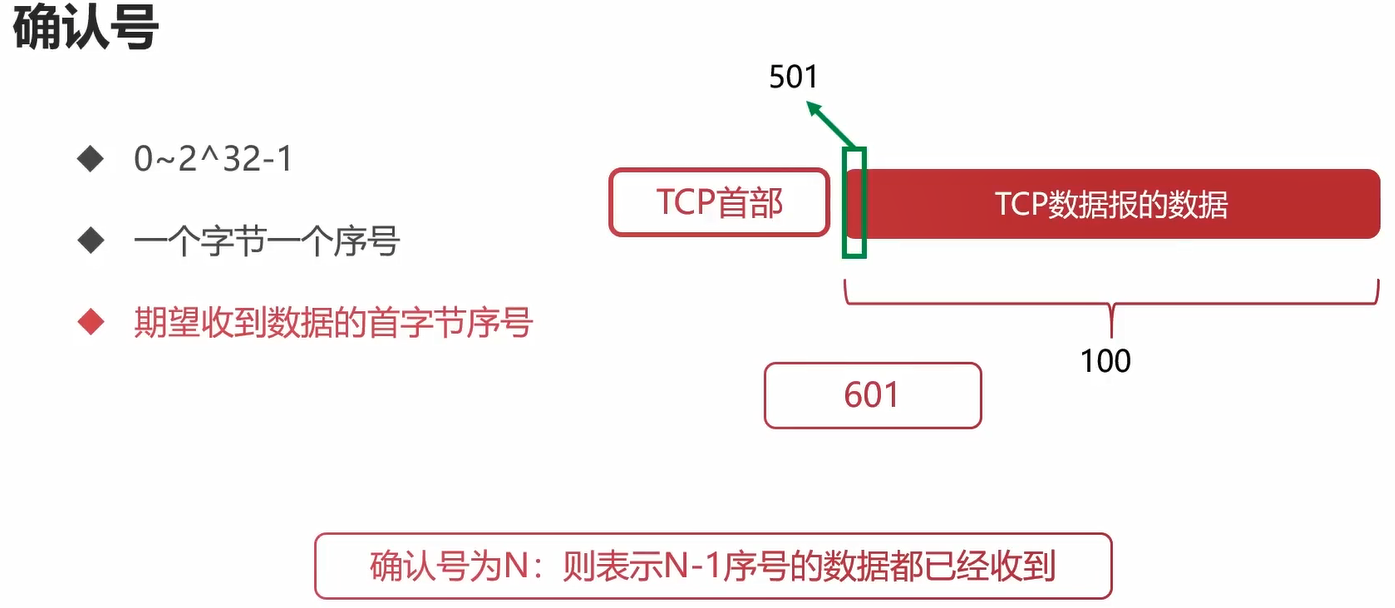
例子:
计算机收到的TCP报文的序号是501,然后数据的长度有100个字节。计算机收到数据后,也就是501~600的字节都收到了,那么期望下一个传递归来的序列号是601。
确认号需要配合序号一起使用。
结论:确认号为N,则表示N-1序号的数据都收到

数据偏移:真实的TCP数据偏离首部的距离
通过数据偏移,可以计算出TCP头部的长度范围,最少为20,4*15=60,所以TCP头部的长度为[20,60]字。
需要有数据偏移是因为有TCP选项这一块内容,所以要有数据偏移来记录TCP头部的长度。
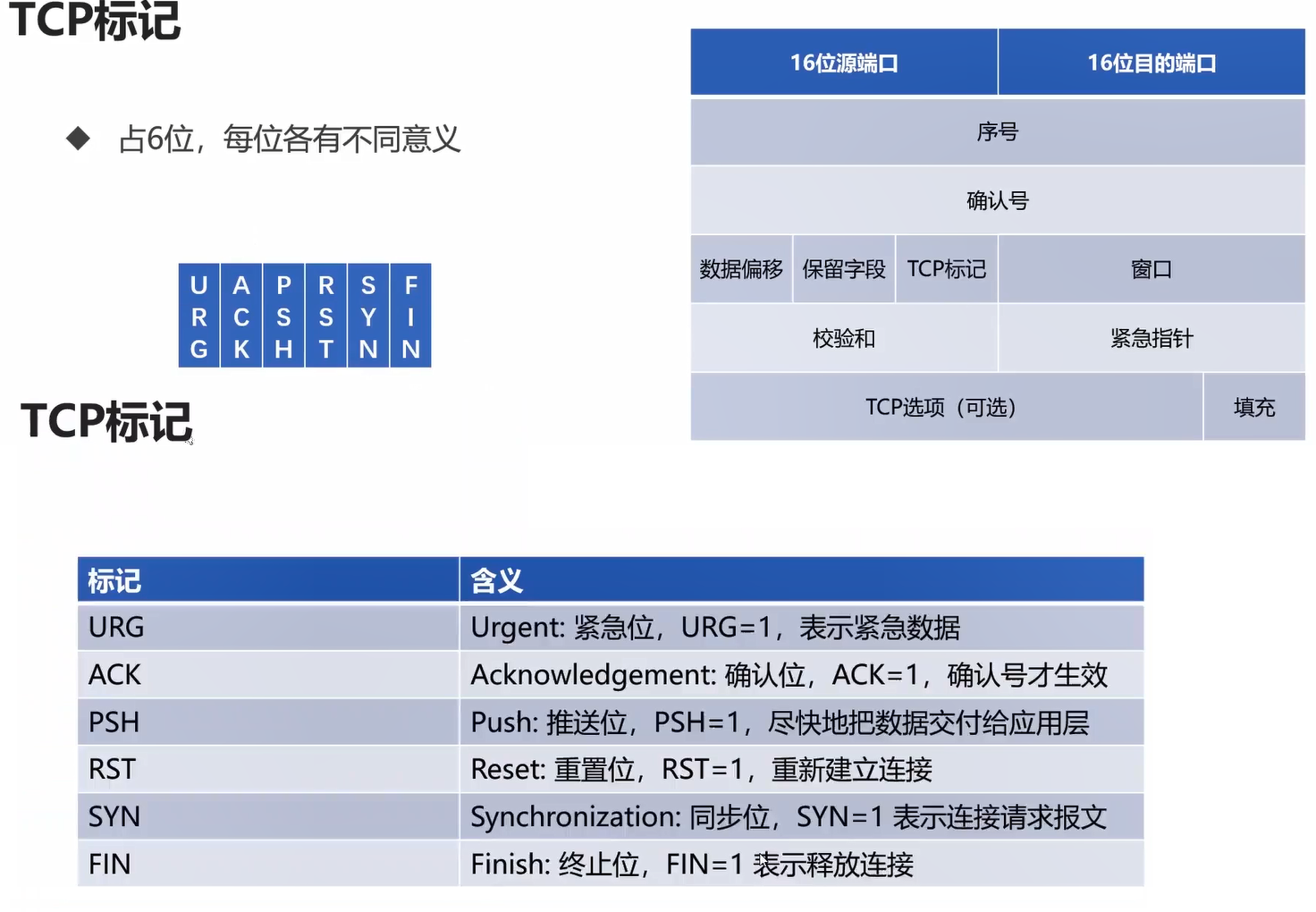
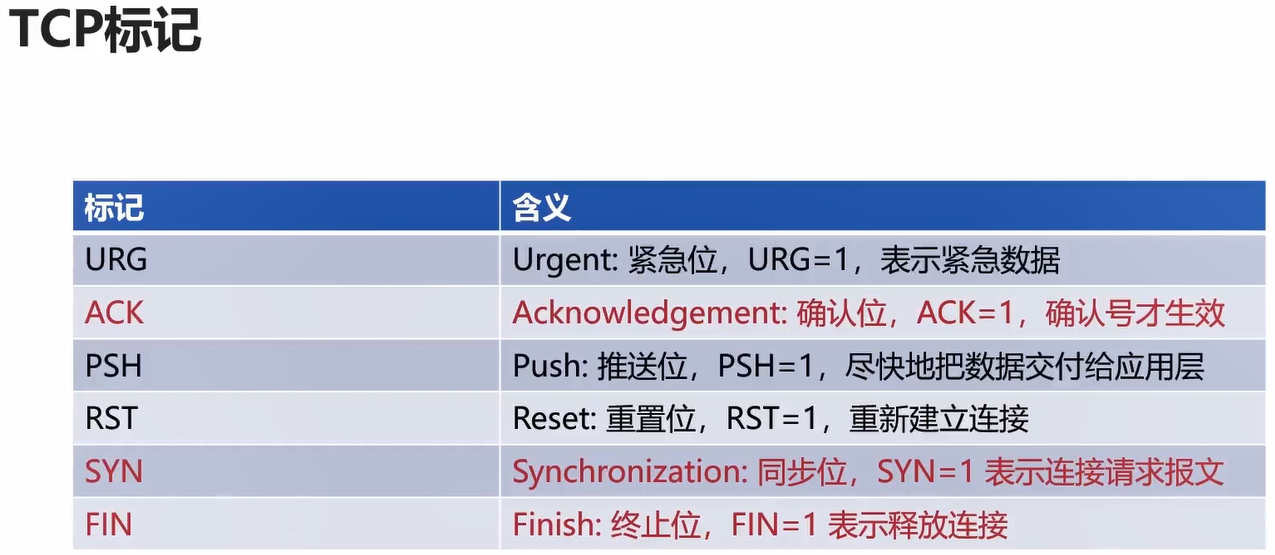
TCP标记是非常有用的, 包含后面的三次握手,四次挥手都要不断用到这里的TCP标记。

窗口指明允许对方发送的数据量,如果窗口的值为1000,那么就表示允许对方发送过来1000个字节。
窗口可以和确认好结合运算,比如确认号是501,窗口的值是1000,那么表示501~1500这么多个字节的数据都是可以接收的。


可靠传输协议的基本原理

可靠传输的基本原理,这里了解了两个协议:停止等待协议 & 连续ARQ协议
停止等待协议的核心是停止和等待。
连续ARQ协议的核心是滑动窗口和累计确认。
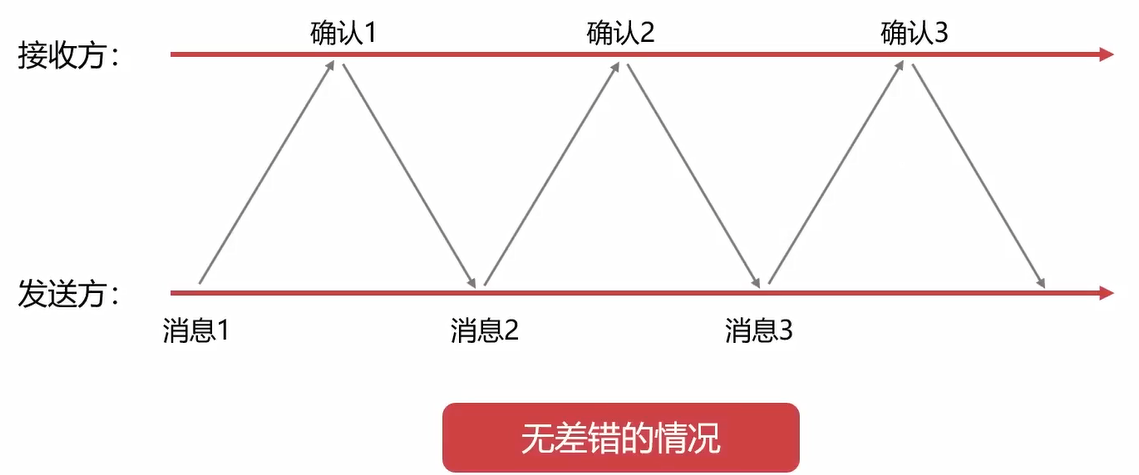
停止等待协议就如上图, 接收方和发送方一直处于停止等待,停止等待的过程。
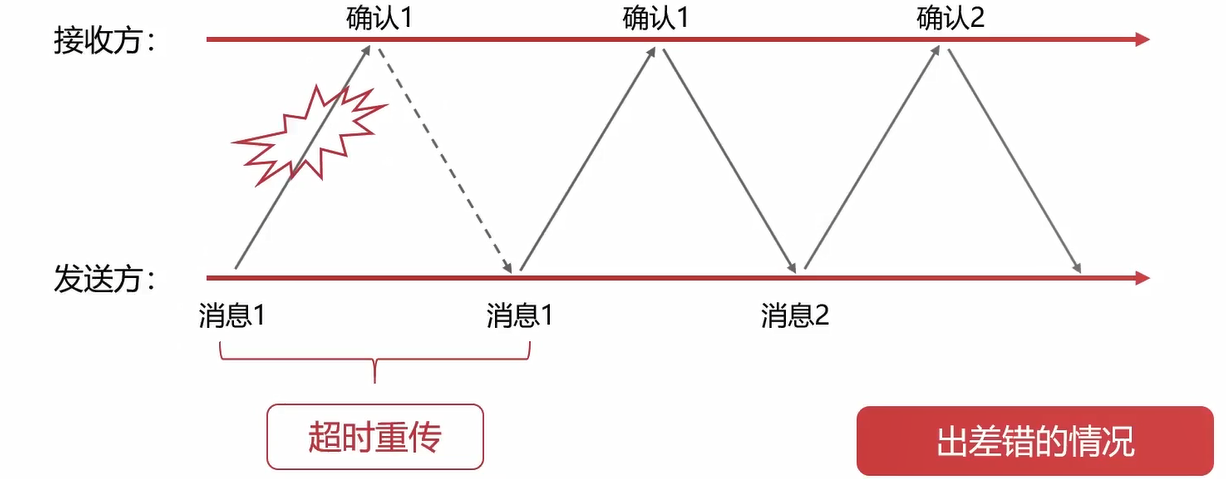
第一种差错情况: 发送方没有收到确认消息,可能是发送方发出去的消息丢失了,那么发送方就会重新发送数据。
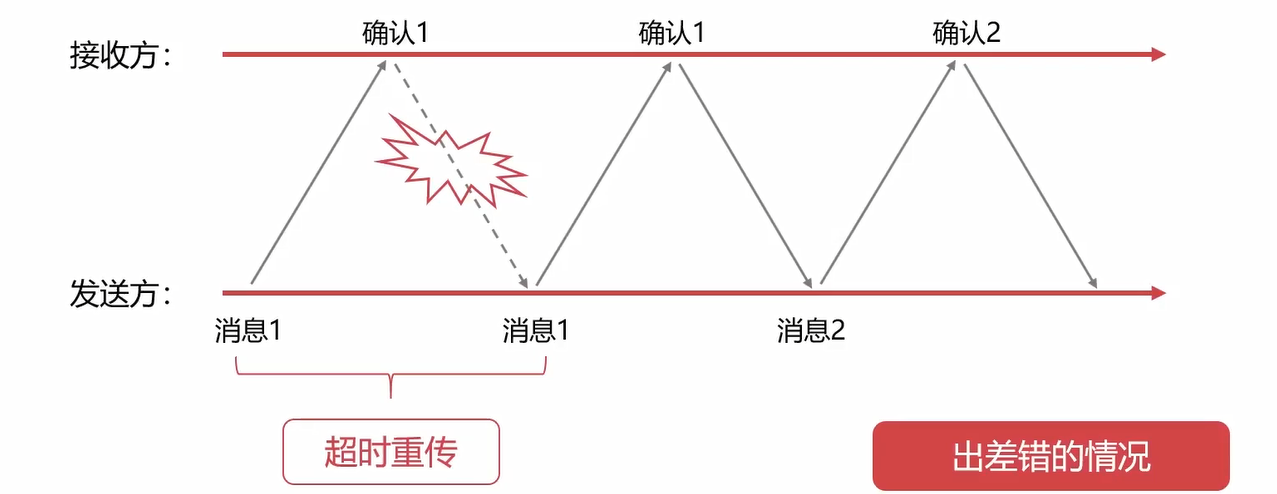
第二种差错情况:确认消息丢失,发送方没有收到确认消息,会超时重传。
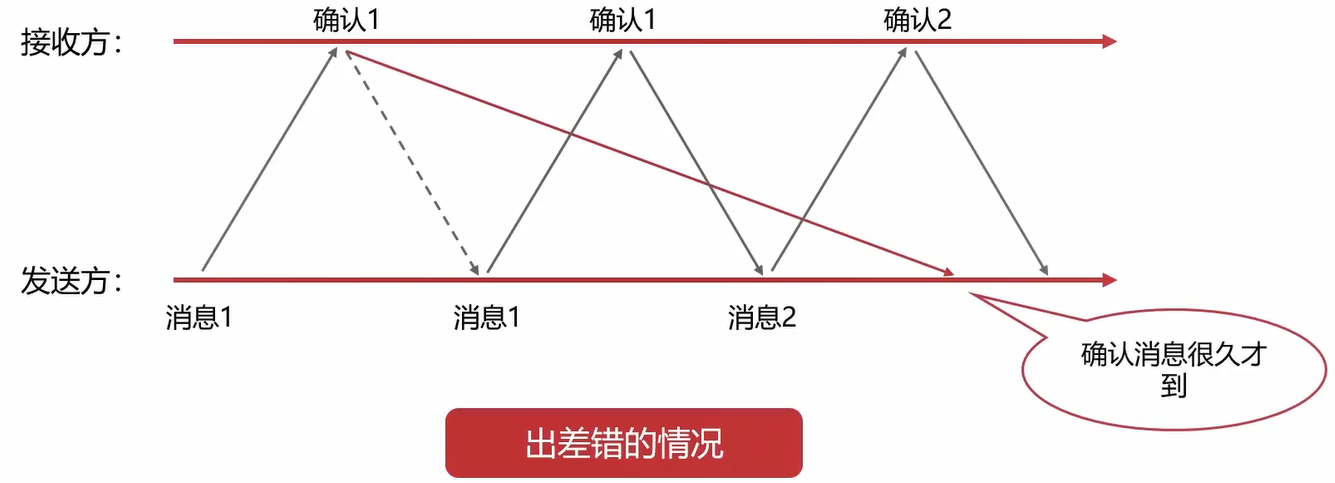
第三种差错情况:确认消息没有丢失,但是迟到了。

停止等待协议的三种可能查重情况
- 发送消息在路上丢失
- 确认消息在路上丢失
- 确认消息很久才到
 TCP中一共有四个定时器,这里学习第一个定时器——超时定时器。
TCP中一共有四个定时器,这里学习第一个定时器——超时定时器。


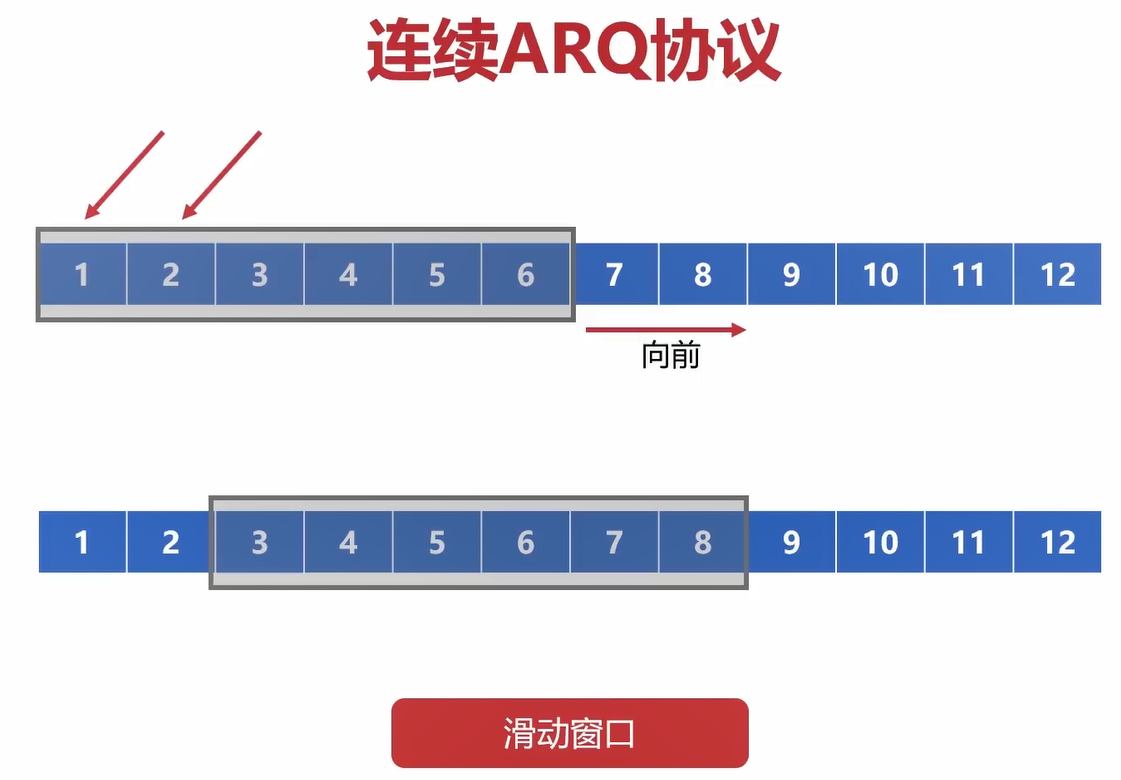
这里不再一个一个字节发送,而是直接把窗口中的6个字节一起发送。
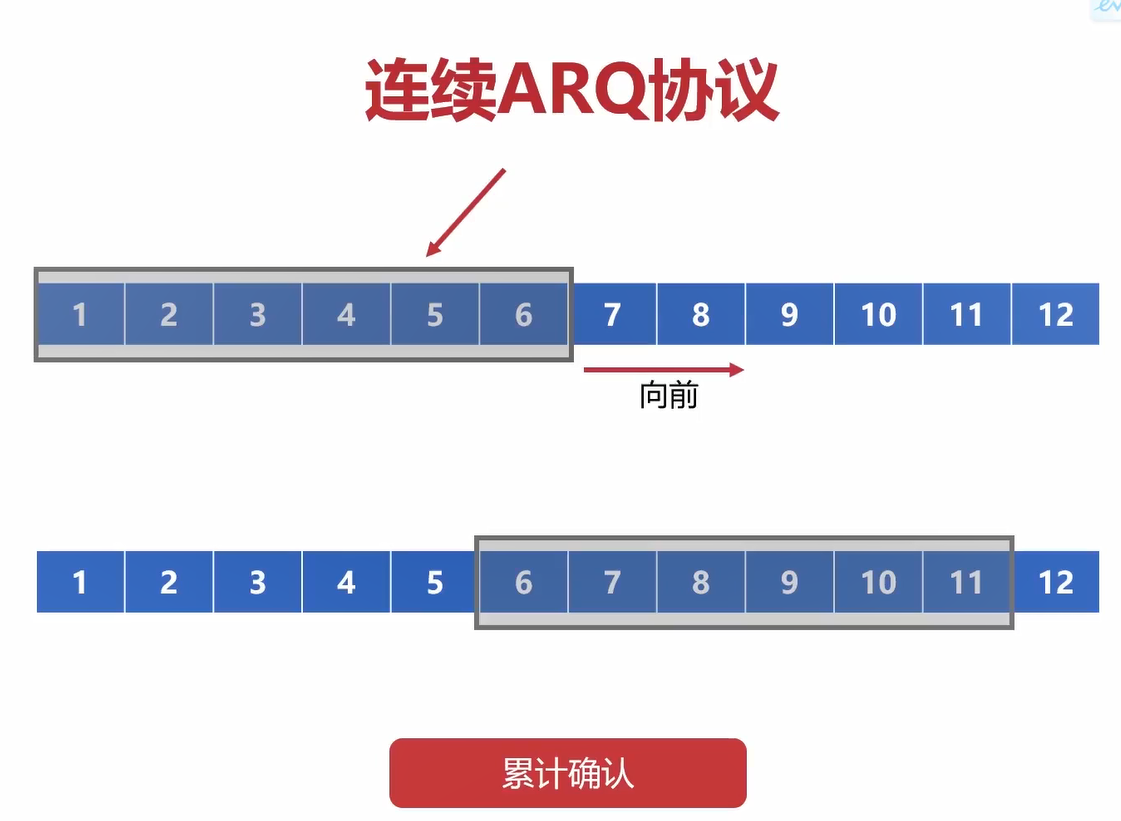
但是如果要一个字节一个字节确认的话,那么相当于是没有改进的。
例如上图,如果第5个字节收到了确认了,那么就表明序号5和之前的字节都收到了(这是确认号的作用)。
然后就可以直接向后推进,这样就省了很多次重复确认。
窗口控制与重发控制
-
确认报文丢失,这个其实是不要津的,可以通过后面的确认号来进行确认判断。
-
发送的报文丢失,那么接收方就会重复发送几次同样的一个确认号,接收方连续3次收到同一个确认号,就会将所对应的数据进行重发(快速重传)。
TCP协议的可靠传输


TCP的可靠传输是基于连续ARQ的。
选择重传重传的是一个边界,也就是一个范围,而不是某一个字节。

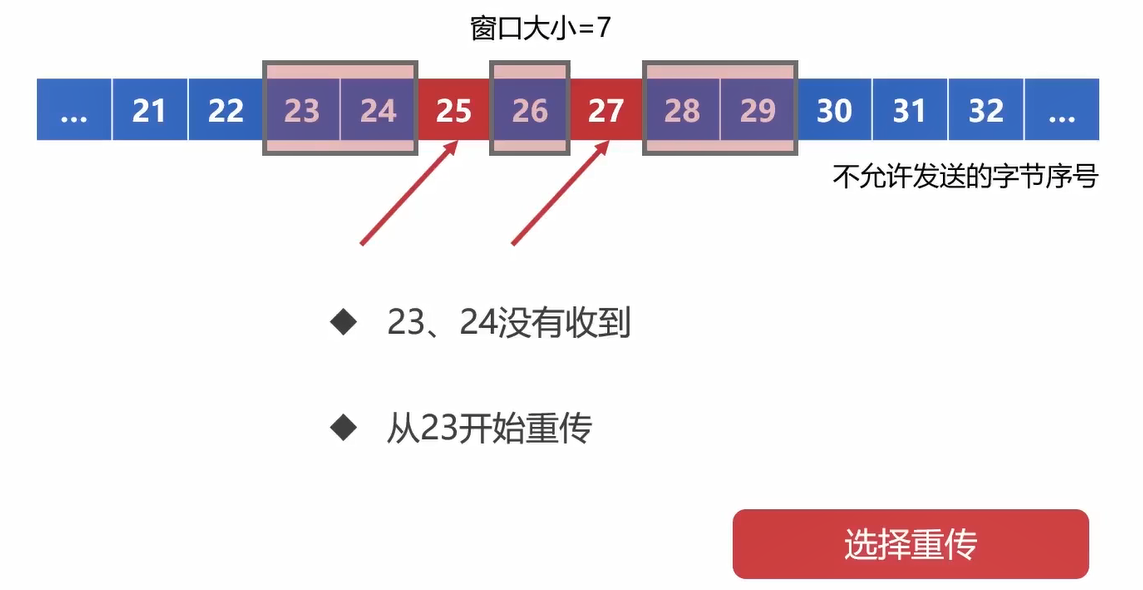
网络的速度不一定是按序的!如果先收到了25和27的确认应答,但是没有收到23,24的话,也要从23开始重传。
选择重传:TCP可以选择一些消息重新传输,而不是把所有消息重新传输。
(如果是按序收到的,那么就是连续ARQ协议,如果不是按序收到的,就可以选择重传!)
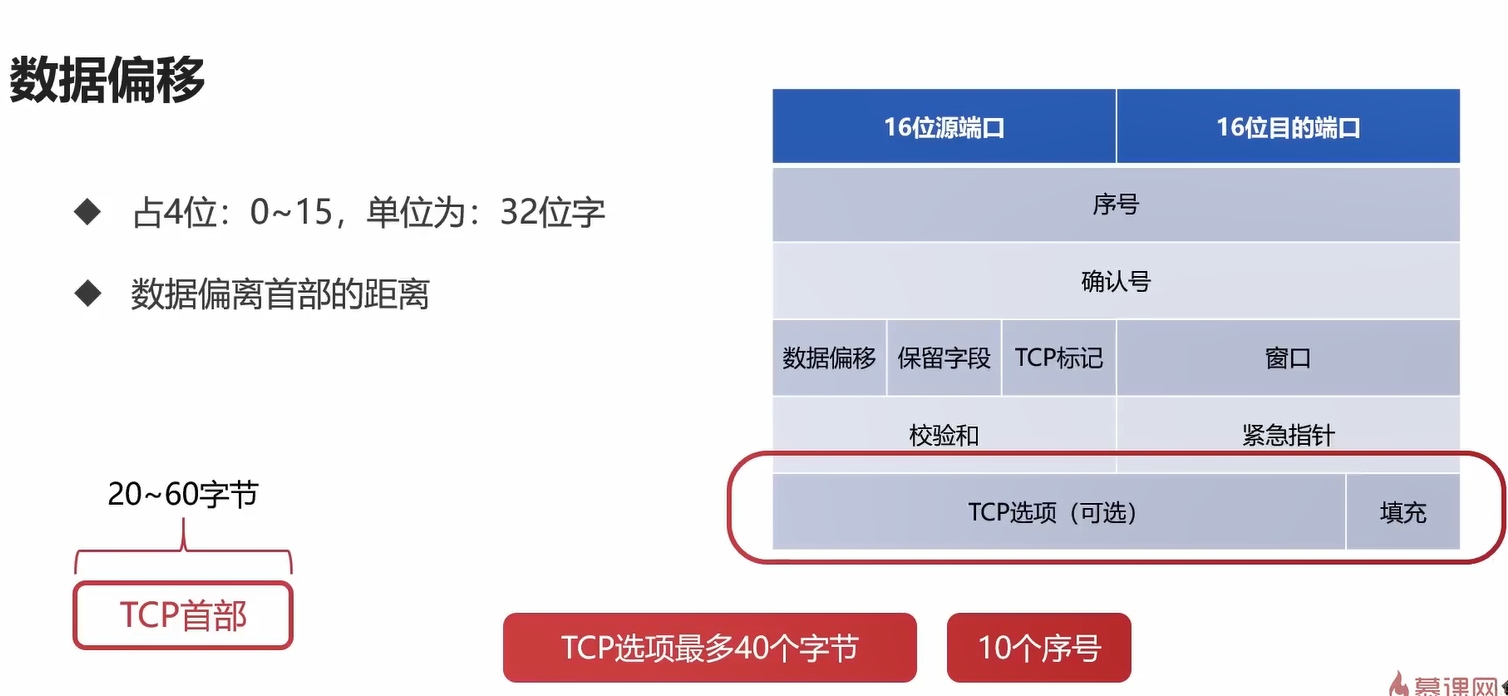
选择重传的重传序号存在TCP选项中,最多可以存放10个序号。
TCP协议的流量控制
流量控制是TCP协议的一个特有功能。

流量控制: 接收方通过控制窗口的大小,来约束发送方的发送速率


TCP协议的拥塞控制

流量控制和拥塞控制的差别。一个是考虑端到端的流量控制,一个是对网络全局的考虑。

拥塞控制主要有两个算法:慢启动算法 & 拥塞避免算法
慢启动先指数增长,增长到慢启动阈值就会停止,切换到拥塞避免算法。

网络拥塞的意思就是传输报文不会发生超时。
慢启动阈值一般都是告诉你的(怎么计算先不管了...)
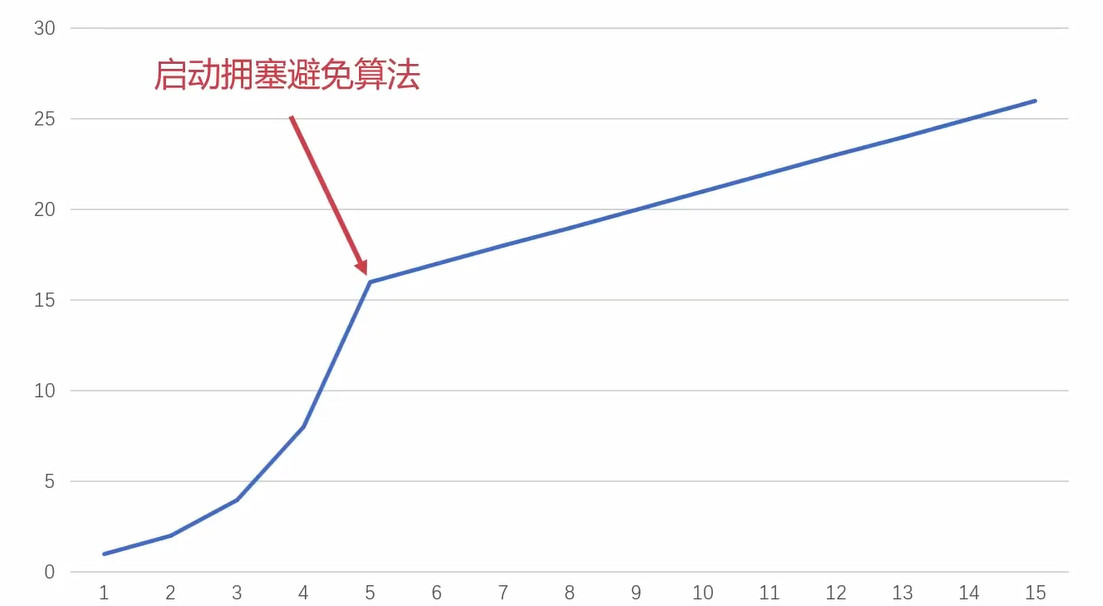
上图就是是先进行慢启动,达到阈值之后在进行拥塞避免算法,不断去+1试探。
TCP连接的三次握手
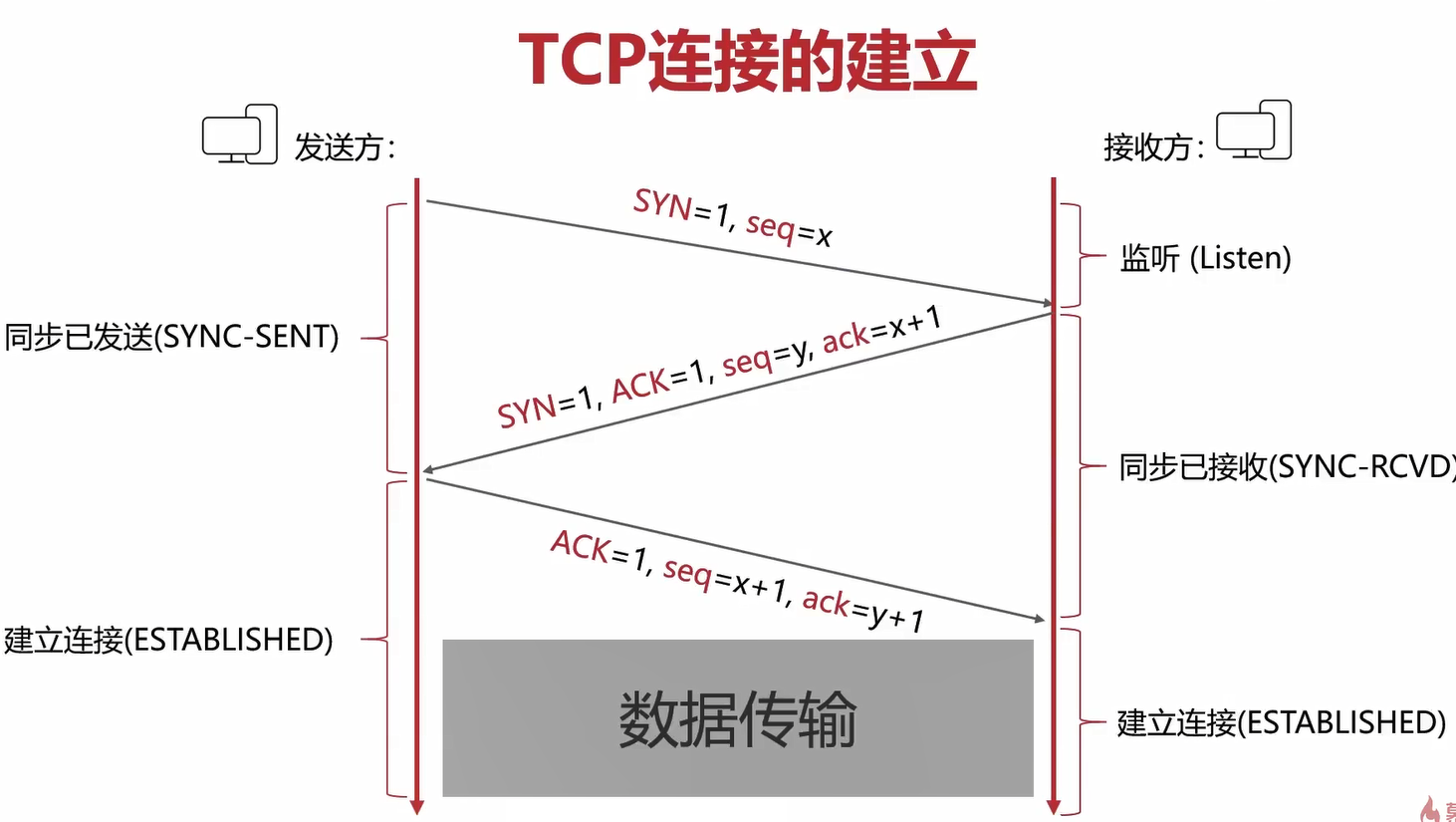
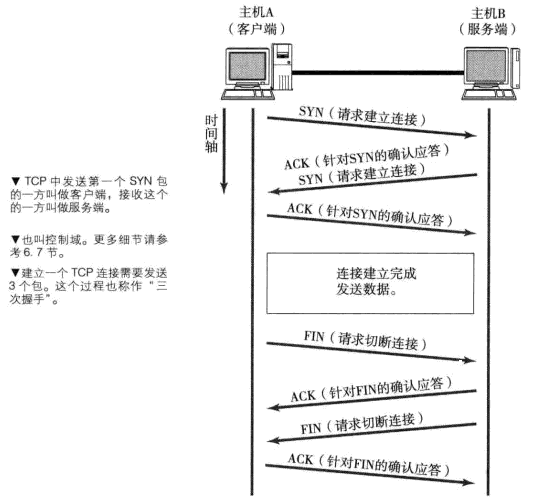
上面就是上次握手的过程
-> SYN=1,seq=x
<- SYN=1,ACK=1,seq=y,ack=x+1
-> ACK=1,seq=x+1,ack=y+1


TCP的三次握手最主要是防止已过期的连接再次传到被连接的主机。
上图所示,如果发送方的请求报文进行了超时重传, 第二个报文先到了,并得到接收方回应,如果是两次握手的话,那么接收方回应时就建立了连接,发送方收到应答报文也建立连接。
但是问题是,如果超时报文接收方回应了,那么发送方收到这个应答报文,也会建立连接,那么就会建立两次连接,这是不对的。
为了避免上述问题,发送方在收到接收方的应答后,可以建立连接,并再发送一次确认报文,这样后面收到的请求应答报文都是无效的。而接收方再收到第三次握手才开始建立连接。
TCP连接的四次挥手
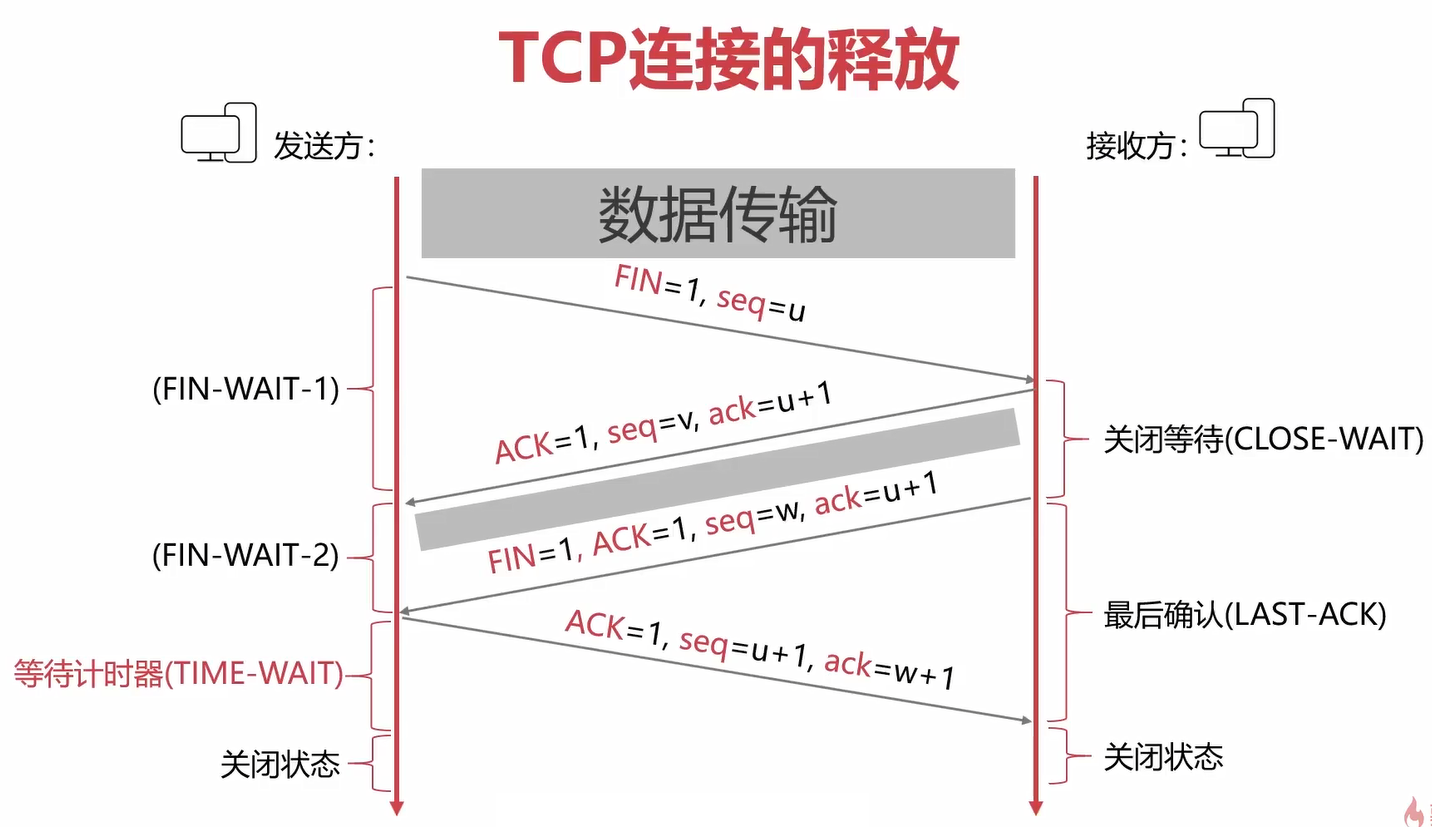
为什么接收方连续发送两次确认报文呢?因为结束连接是发送方主动请求的,发送方的数据是发送完成了,但是接收方可能还有数据需要接收,所以第一次应答报文是:好的,我知道了,等我收完数据先。然后接收方收完数据后就会发送第二条应答报文。
发送方收到第二次应答报文后,会进入一个等待时间2MSL(报文最长存活时间),防止应答报文没有发送出去,等待时间过了就进行关闭。
接收方收到发送方的应答报文就关闭了。
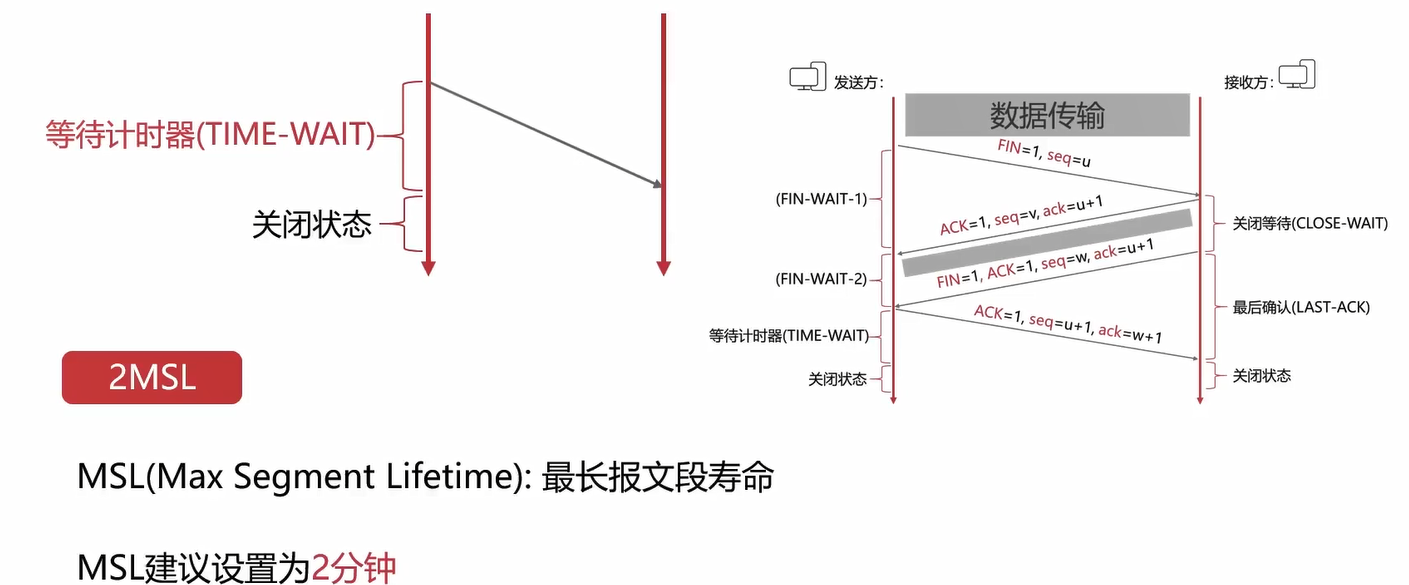
一般主动释放连接后,也是不能马上复用该端口的,就是因为有这个等待计时器的存在,要等待2MSL后才会释放端口(一般是4分钟左右)。
为什么要设置2MSL?
- 最后一个报文没有确认
- 确保发送方的ACK可以到达接收方
- 2MSL时间内没有收到,则接收方会重发
- 确保当前连接的所有报文都已经过期
套接字与套接字编程




服务端代码
import socket
def server():
# 创建套接字
s = socket.socket()
# 绑定套接字
host = 'localhost'
port = 6666
s.bind((host, port))
# 监听套接字
s.listen(5)
# 接收&处理消息
while True:
c, addr = s.accept()
print("Connect Addr: ", addr)
c.send(b"Welcome!")
c.close()
if __name__ == "__main__":
server()
客户端代码
import socket
def client(i):
# 创建套接字
s = socket.socket()
# 连接套接字
host = 'localhost'
port = 6666
s.connect((host, port))
# 发送信息
print("Recv msg:%s, Clinet: %d" % (s.recv(1024), i))
s.close()
if __name__ == "__main__":
for i in range(10):
client(i)

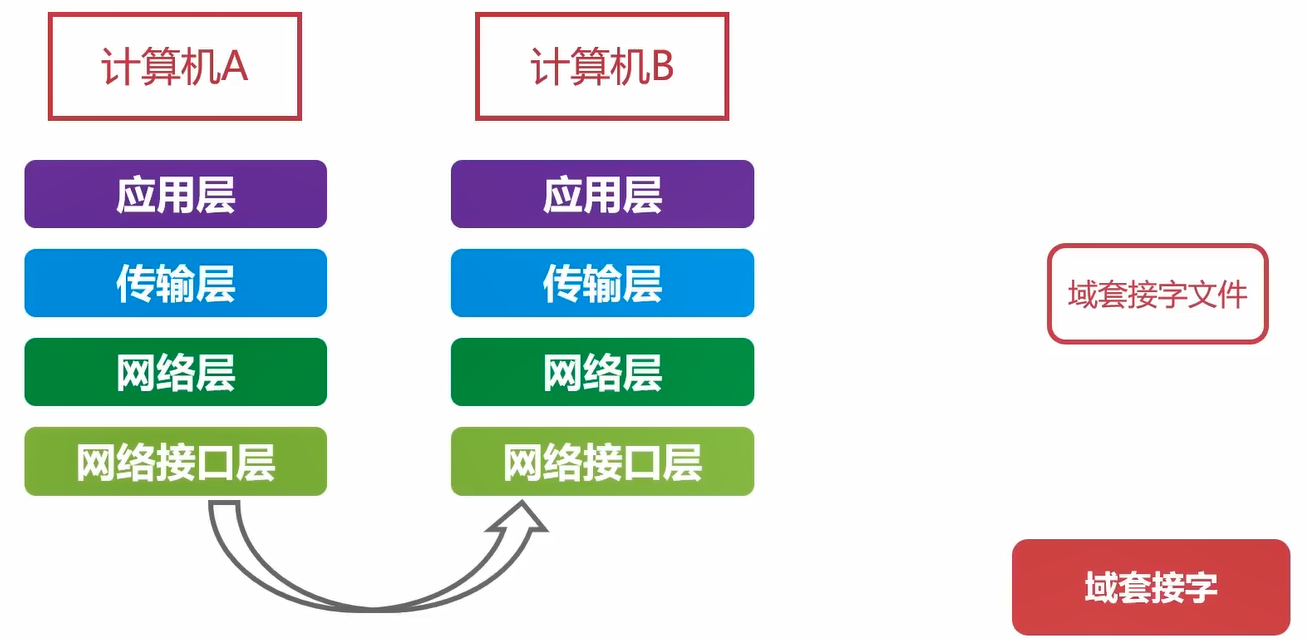
网络套接字的话,不管是不是本机,都要完整的走完整个协议栈。
域套接字本适合本机的进程之间通信,对系统资源消耗也小。