Python_selenium之获取当前页面的href属性,id属性,图片信息和截全屏
一、 获取当前页面的全部信息
1. 图片信息包括图片名称、图片大小等信息
2. 只需将图片信息打印出来(image.text image.size image.tag_name)
二、 获取页面元素的href属性(id同理)
1. 获取当前页面所有的链接信息(以百度首页为例)
2. 运用for循环,然后运用get_attribute(‘href’)
3. 然后将之打印出来即可
三、 截取全屏信息
1. 运用get_screenshot_file()进行截图即可
四、 测试脚本
1. 将以上三种代码写在一起,如下所示:
#coding:utf-8
from selenium import webdriver
import time
driver=webdriver.Firefox()
driver.maximize_window()
driver.implicitly_wait(8)
driver.get("https://www.baidu.com/")
for image in driver.find_elements_by_tag_name("img"):#获取当前页面的图片信息
print image.text
print image.size
print image.tag_name
print "================================"
time.sleep(2)
for link in driver.find_elements_by_xpath("//*[@href]"):#获取当前页面的href
print link.get_attribute('href')
print "================================"
for id in driver.find_elements_by_xpath("//*[@id]"):#获取当前页面的id
print id.get_attribute('id')
print "================================"
driver.get_screenshot_as_file("E:\work_study\One.png")#截取当前页面的图片(全屏)。括号里面的路径为保存到本地电脑上面的路径,可随意设置。
driver.quit()
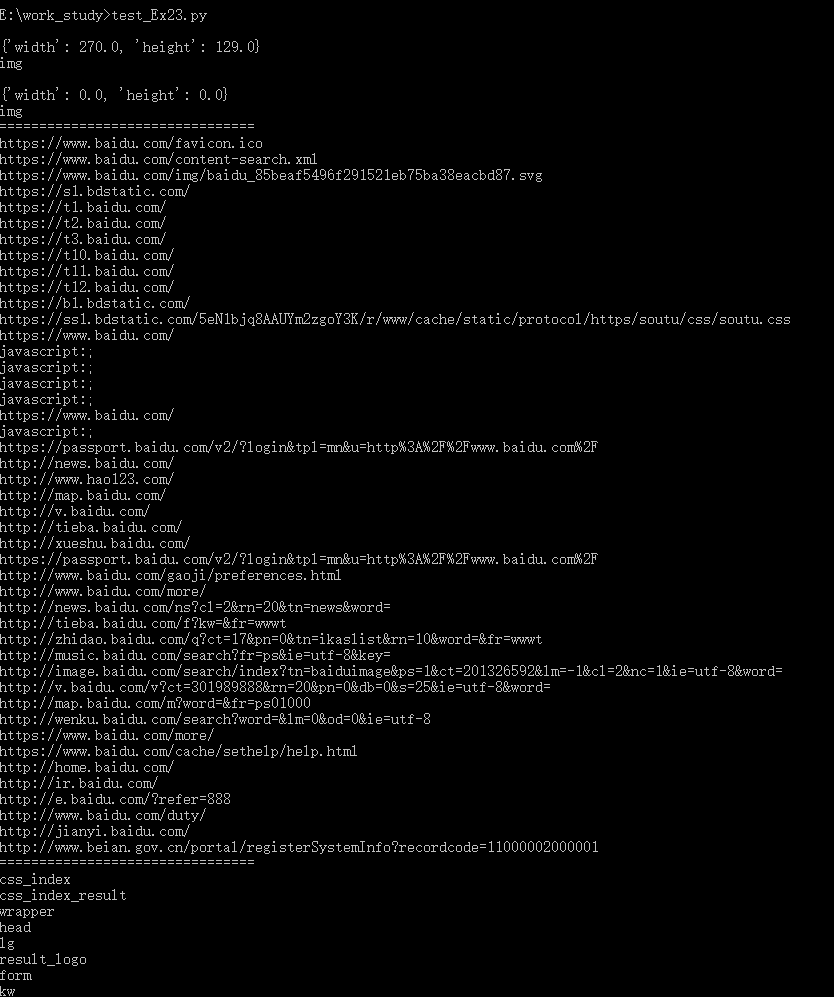
五、 测试结果
1. 如下图所示: