重点 4567,Special 4,5
3道编程题,分值 35(基本书上,不超纲)
选填各 20分,简答 5 题/25分,编程题 3题/35分、
简答题参考每章课后习题
第 1 章简答题
1. 请阐述大数据处理的基本流程。
数据采集与预处理
数据存储与管理
数据处理与分析
数据可视化
2. 请阐述大数据的计算模式及其代表产品。(记 Title)
- 批处理计算
- 流计算
- 图计算
- 查询分析计算
3. 请列举 Hadoop 生态系统的各个组件及其功能。
-
HDFS:分布式文件系统,适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭 之后就不需要改变。
-
YARN:分布式资源管理系统,用于同一管理集群中的资源(内存等)
-
MapReduce:Hadoop的编程框架,用map和reduce方式实现分布式程序设计,类似于Spring。
-
Hbase:Hadoop下的分布式数据库,类似于NoSQL
-
Hive:数仓工具,Hive进行数据离线批量处理时,需将查询语言先转换成MR任务,由MR批量处理返回结果,所以Hive没法满足数据实时查询分析的需求。
4.分布式文件系统 HDFS 的名称节点和数据节点的功能分别是什么?
-
名称节点:作为中心服务器,负责管理文件系统的命名空间及客户端对文件的访问。
-
数据节点一般是一个节点运行一个数据节点的进程,负责处理文件系统客户端的读写请求。
5. 试阐述 MapReduce 的基本设计思想。
!!!!!!!!!!!!!!!!!!
6.YARN的主要功能是什么?使用 YARN 可以带来哪些好处?
- 负责集群资源调度管理的组件,“一个集群多个框架”、即在一个集群上部署一个统一的资源调度管理框架 YARN,实现集群资源共享和资源弹性收缩,有效提高了集群的利用率。降低企业运维成本
7.试阐述 Hadoop 生态系统中 HBase 与其他部分的关系。
8.数据仓库 Hive 的主要功能是什么?
- 对存储在 HDFS 中的数据集进行数据整理、特殊查询和分析处理;
- 同时提供 HiveQL(已被 Spark SQL 替代)可以快速实现简单的 MapReduce 统计,本身也可转换成 MapReduce 任务进行运行。
9.Hadoop 主要有哪些缺点?相比之下, Spark 具有哪些优点?
-
缺点
表达能力有限:计算必须转化成map和reduce两个操作。
磁盘io开销大:每次要从磁盘读取数据。
延迟高。
-
优点:
Spark 的计算模式也属于 MapReduce ,但还提供了多种数据集操作类型。
Spark 提供了内存计算,带来了更高的迭代运算效率
Spark 基于 DAG 的任务调度执行机制,要优于mapreduce的迭代执行机制。
第 2 章简答题
-
Spark 是基于内存计算的大数据计算平台,请阐述 Spark 的主要特点。
1)运行速度快:基于内存的计算比 MapReduce 快 100 倍,基于磁盘快 10 倍。
2)容易使用:编写一个 spark 的应用程序可以使用 Java, Scala, Python, R,这就使得我们的开发非常地灵活。
3)通用性 spark提供了完整强大的技术栈,能够应对复杂的计算。
4)运行模式多样 可运行在独立集群模式,或hadoop中,也可运行在amazon等云环境中。
-
Spark 的出现是为了解决 Hadoop MapReduce 的不足,试列举 Hadoop MapReduce 的几个缺陷,并说明 Spark 具备哪些优点。
-
美国加州大学伯克利分校提出的数据分析的软件栈 BDAS 认为目前的大数据处理可以分为哪3个类型?
复杂的批量数据处理:时间跨度通常在数十分钟到数小时之间;
基于历史数据的交互式查询:时间跨度通常在数十秒到数分钟之间;
基于实时数据流的数据处理:时间跨度通常在数百毫秒到数秒之间
-
Spark 已打造出结构一体化、功能多样化的大数据生态系统,请阐述 Spark 的生态系统。
Spark的设计遵循“一个软件栈满足不同应用场景”的理念,逐渐形成一套完整生态系统,既能够提供内存计算框架,也可以支持SQL即席查询、实时流式计算、机器学习和图计算等。Spark可以部署在资源管理器YARN之上,提供一站式的大数据解决方案。因此,Spark所提供的生态系统同时支持批处理、交互式查询和流数据处理。
-
从 Hadoop + Storm 架构转向 Spark 架构可带来哪些好处?
实现一键式安装和配置、线程级别的任务监控和告警;
降低硬件集群、软件维护、任务监控和应用开发的难度;
便于做成统一的硬件、计算平台资源池。
-
请阐述“ Spark on YARN ”的概念。
Spark可以运行与YARN之上,与Hadoop进行统一部署,即“Spark on YARN”,其架构如图所示,资源管理和调度以来YARN,分布式存储则以来HDFS。
-
请阐述 Spark 的如下几个主要概念: RDD 、 DAG 、阶段、分区、窄依赖、宽依赖。
RDD:是弹性分布式数据集(Resilient Distributed Dataset)的英文缩写,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型。
DAG:是Directed Acyclic Graph(有向无环图)的英文缩写,反映RDD之间的依赖关系。
阶段:是作业的基本调度单位,一个作业会分为多组任务,每组任务被称为“阶段”,或者也被称为“任务集”。
分区:一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可以分成多个分区,每个分区就是一个数据集片段。
窄依赖:父RDD的一个分区只被一个子RDD的一个分区所使用就是窄依赖。
宽依赖:父RDD的一个分区被一个子RDD的多个分区所使用就是宽依赖。
-
Spark 对 RDD 的操作主要分为行动( Action )和转换( Transformation )两种类型,两种操作区别是什么?
转换操作,并不会马上开始计算,而是记录转换的轨迹;只有到行动操作时,才会触发从头到尾的计算。
第 3 章简答题
-
请阐述 Spark 的4种部署模式。
local模式 standalone模式 yarn模式 mesos模式
-
请阐述 Spark 和 Hadoop 的相互关系。
1)Hadoop和Spark都是并行计算,两者都是用MR模型进行计算
2)Hadoop一个作业称为一个Job,Job里面分为Map Task和Reduce Task阶段,每个Task都在自己的进程中运行,当Task结束时,进程也会随之结束;
3)Spark用户提交的任务称为application,一个application对应一个SparkContext,app中存在多个job,每触发一次action操作就会产生一个job。这些job可以并行或串行执行,每个job中有多个stage,stage是shuffle过程中DAGScheduler通过RDD之间的依赖关系划分job而来的,每个stage里面有多个task,组成taskset,由TaskScheduler分发到各个executor中执行;executor的生命周期是和app一样的,即使没有job运行也是存在的,所以task可以快速启动读取内存进行计算。
-
请阐述 pyspark 在启动时,< master - url >分别采用 local 、 local [*]和 local [ k ]时,具体有什么区别。
local 使用一个worker线程本地化运行spark
local [*]使用与逻辑cpu个数相同数量的线程来本地化运行。
localk 使用k个worker线程本地化运行spark。
-
pyspark 在启动时,采用 yarn - client 和 yarn - cluster 这两种模式有什么区别?
Yarn-client中,Application Master仅仅从Yarn中申请资源给Executor,之后client会跟container通信进行作业的调度。
在Yarn-cluster模式下,driver运行在Appliaction Master上,Appliaction Master进程同时负责驱动Application和从Yarn中申请资源,该进程运行在Yarn container内,所以启动Application Master的client可以立即关闭而不必持续到Application的生命周期。
-
请总结开发 Spark 独立应用程序的基本步骤。
安装编译打包工具,如sbt,Maven;
编写Spark应用程序代码;
编译打包;
通过 spark-submit 运行程序
# Spark 对象创建
from pyspark import *
from pyspark.sql import *
import pyspark.sql.functions as func
from pyspark import SparkConf, SparkContext
# 创建方法一 : SparkSession
sc = SparkSession.builder.config(conf = SparkConf()).getOrCreate()
# 创建方法二 : SparkConf
# 建议使用第二种
conf = SparkConf().setMaster("local").setAppName("Code")
sc = SparkContext(conf = conf)
第 4 章 RDD 编程
4.1 RDD 创建
-
从文件系统中加载数据
Spark 采用
textFile()方法来从文件系统中加载数据创建 RDD该方法把文件的 URL 作为参数,这个 URL 可以是:
- 本地文件系统的地址
- 或者是分布式文件系统的 HDFS 的地址
# textFile 收录于 SparkContext 类中 url = "" lines = sc.textFile("file://" + url) lines.foreach(print) -
从分布式文件系统 HDFS 中加载数据
首先需启动 HDFS 并上传一个文件作为测试
# 创建输入目录 hdfs dfs -mkdir /user/hadoop # http://192.168.0.129:9870/explorer.html#/user/hadoop # 本地路径 -> HDFS 路径 hadoop fs -put localFilePath /user/hadoop # 搜索文件 hadoop fs -ls ./word.txtPySpark 创建 RDD
lines = sc.textFile("hdfs://localhost:9000/user/hadoop/word.txt") lines = sc.textFile("/user/hadoop/word.txt") lines = sc.textFile("word.txt") -
通过并行集合(列表)创建 RDD
调用
SparkContext.parallelize方法,从一个以存在的集合(列表)上创建 RDD,从而可以做到并行化处理list = [1,2,3,4,5] rdd = sc.parallelize(list) rdd.foreach(print)返回简答题:Click Here
4.2 RDD 操作
-
转换操作
lines = sc.textFile("word.txt") # filter(func) 筛选出满足函数func的元素,并返回一个新的数据集 rdd = lines.filter(lambda line : "Spark" in line) # map(func) 将每个元素传递到函数func中,并将结果返回为一个新的数据集 rdd1 = sc.parallelize(list) rdd2 = rdd1.map(lambda x : x + 10) # 另一个实例 words = lines.map(lambda line : line.split(" ")) # flatMap(func) 与map()相似,但每个输入元素都可以映射到0或多个输出结果 # Hadoop is Good -> Hadoop "\n" is "\n" Good words = lines.flatMap(lambda line : line.split(" ")) # groupByKey() 应用于(K,V)键值对的数据集时,返回一个新的(K, Iterable)形式的数据集 >>> words = sc.parallelize([("Hadoop",1),("is",1),("good",1), \ ... ("Spark",1),("is",1),("fast",1),("Spark",1),("is",1),("better",1)]) word = words.groupByKey() ('Hadoop', <pyspark.resultiterable.ResultIterable object at 0x7fb210552c88>) ('better', <pyspark.resultiterable.ResultIterable object at 0x7fb210552e80>) ... # reduceByKey(func) 应用于(K,V)键值对的数据集时,返回一个新的(K, V)形式的数据集,其中每个值是将每个key传递到函数func中进行聚合后的结果 word = words.reduceByKey(lambda a,b : a + b) ('is', 3) ('Spark', 2)返回简答题:Click Here
-
行动操作
# count() 返回数据集中的元素个数 rdd = sc.parallelize([1,2,3,4,5]) rdd.count() # first() 返回数据集中的第一个元素 rdd.first() # reduce(func) 通过函数func(输入两个参数并返回一个值)聚合数据集中的元素 rdd.reduce(lambda a,b : a + b) # 15 # collect() 以数组的形式返回数据集中的所有元素 rdd.collect() # [1, 2, 3, 4, 5] # foreach(func) 将数据集中的每个元素传递到函数func中运行 rdd.foreach(lambda elem : print(elem)) # take(n) 以数组的形式返回数据集中的前n个元素 print(rdd.take(3)) # [1, 2, 3] # ===================================== # -
惰性机制
所谓的“惰性机制”是指,整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,只有遇到行动操作时,才会触发“从头到尾”的真正的计算
# Example 1 lines = sc.textFile("word.txt") lineLengths = lines.map(lambda s : len(s)) # 只有到了 reduce 这个行动操作,才会触发真正的计算 totalLength = lineLengths.reduce(lambda a,b : a + b) print(totalLength) # 46# Example 2 list = ["Hadoop" , "Spark", "Hive"] rdd = sc.parallelize(list) print(rdd.count()) # 行动操作,触发一次真正从头到尾的计算 print(",".join(rdd.collect())) # 行动操作,触发一次真正从头到尾的计算 -
持久化
针对惰性机制,可以通过持久化(缓存)机制避免这种重复计算的开销
可以使用persist()方法对一个RDD标记为持久化之所以说“标记为持久化”,是因为出现
persist()语句的地方,并不会马上计算生成RDD并把它持久化,而是要等到遇到第一个行动操作触发真正计算以后,才会把计算结果进行持久化持久化后的 RDD 将会被保留在计算节点的内存中被后面的行动操作重复使用
list = ["Hadoop" , "Spark", "Hive"] rdd = sc.parallelize(list) rdd.cache() # 会调用 persist(MEMORY_ONLY) 但是语句执行到这并不会缓存 RDD print(rdd.count()) # 真正执行并放入缓存 print(",".join(rdd.collect())) # 第二次行动操作,不会从头到尾的计算,重复使用上面缓存的 rdd返回简答题:Click Here
-
分区
RDD 是弹性分布式数据集,通常 RDD 很大,会被分成很多个分区,分别保存在不同的节点上,从而增加并行度键少通信开销
分区原则:使得分区个数尽量等于集群中 CPU Core 数目。对于Spark 部署模式
Local Model,Standalone Model,YARN,Mesos都可设计spark.default.parallelism的参数- Local:默认为本地 CPU 数目,若设置了
local[N]则默认为 N - Standadlone 和 YARN:
max(集群中所有 CPU 核心数总和, 2) - Mesos:默认分区为 \(8\)
手动设置分区个数
# sc.textFile("url",paratitionNum) # 对于 parallelize 而言 paratitionNum default 为 spark.dafault.parallelism # 对于 textFile 而言 默认为 spark.dafault.parallelism # 对于 HDFS 中文件,分区数为文件分片数,eg: 128MB/片 list = [1,2,3,4,5] rdd = sc.parallelize(list, 2)使用
repartition方法重设置分区个数rdd = sc.parallelize([1,2,3,4,5], 3) print(len(rdd.glom().collect())) # 显示 rdd 的分区数量 rdd = rdd.repartition(2) # 重分区 print(len(rdd.glom().collect())) # 显示 rdd 的分区数量自定义分区方法
def MyPartitioner(key): print("MyPartitioner is running") print('The key is %d' % key) return key%10 def main(): print("The main function is running") sc = SparkSession.builder.config(conf = SparkConf()).getOrCreate() data = sc.sparkContext.parallelize(range(10),5) data.map(lambda x:(x,1)) \ .partitionBy(10,MyPartitioner) \ .map(lambda x:x[0]) \ .saveAsTextFile("file:///usr/local/spark/mycode/Final-Exam/04.RDD/data/partitioner") if __name__ == '__main__': main()返回简答题:Click Here
- Local:默认为本地 CPU 数目,若设置了
RDD 综合案例:词频统计
>>> lines = sc. \
... textFile("word.txt")
>>> wordCount = lines.flatMap(lambda line:line.split(" ")). \
... map(lambda word:(word,1)).reduceByKey(lambda a,b:a+b)
>>> print(wordCount.collect())
4.3 键值对 RDD
创建方法:
-
从文件中加载
map(lambda word : (word, 1))取出 RDD 的每个元素,然后赋给 word 然后转化为
(word , 1)>>> lines = sc.textFile("word.txt") >>> pairRDD = lines.flatMap(lambda line : line.split(" ")). \ ... map(lambda word : (word, 1)). \ ... reduceByKey(lambda a,b : a + b) >>> pairRDD.foreach(print) -
通过并行集合(列表)创建 RDD
>>> list = ["Hadoop", "Spark", "Hive", "Spark"] >>> rdd = sc.parallelize(list) >>> pairRDD = rdd.map(lambda word : (word, 1 )) >>> pairRDD.foreach(print)
常见的键值对转换操作
-
reduceByKey(func),使用func函数合并具有相同键的值>>> rdd = sc.parallelize([("Hadoop",1),("Spark",1),("Hive",1),("Spark",1)]) >>> rdd.reduceByKey(lambda a, b : a + b).foreach(print) -
groupByKey(),对具有相同键的值进行分组>>> list = [("spark",1),("spark",2),("hadoop",3),("hadoop",5)] >>> rdd = sc.parallelize(list) >>> rdd.groupByKey() >>> rdd.groupByKey().foreach(print)
reduceByKey 与 groupByKey 的区别
- reduceByKey 用于对每个 Key 对应的多个 value 进行 merge 操作,并且聚合操作可以通过 func 函数进行自定义;
- groupByKey 也是对每个 Key 进行操作,但是对每个 Key 只会生成一个 value-list,groupByKey 本身不能自定义函数,需要先用 groupByKey 生成RDD后通过map进行函数自定义操作
# 区别 Example
>>> words = ["one", "two", "two", "three", "three", "three"]
>>> rdd = sc.parallelize(words).map(lambda a:(a,1))
>>> CountWithReduce = rdd.reduceByKey(lambda a,b:a+b)
>>> CountWithReduce.foreach(print)
# 输出
# groupByKey 转成 (key,value-list)
>>> CountWithGroup = rdd.groupByKey().\
... map(lambda t:(t[0],sum(t[1])))
>>> CountWithGroup.foreach(print)
- keys ,只会把 rdd 的key返回形成一个新的 RDD
- values,只会把 rdd 中的key返回形成一个新的RDD
>>> list = [("spark",1),("spark",2),("hadoop",3),("hadoop",5)]
>>> rdd = sc.parallelize(list)
>>> rdd.keys().foreach(print)
>>> rdd.values().foreach(print)
- sortByKey,功能是返回一个根据键排序的 RDD
>>> list = [("spark",1),("spark",2),("hadoop",3),("hadoop",5)]
>>> rdd = sc.parallelize(list)
>>> rdd.sortByKey(False).foreach(print) # False 表示降序排序
- sortBy() 返回一个根据 Key 排序的 RDD,而 sortBy 可以根据其他字段排序
>>> d1 = sc.parallelize([("c",8),("b",25),("c",17),("a",42), \
... ("b",4),("d",9),("e",17),("c",2),("f",29),("g",21),("b",9)])
>>> d1.reduceByKey(lambda a,b:a+b).sortByKey(False).collect()
>>> print(d1.reduceByKey(lambda a,b:a+b).sortBy(lambda x:x,False).collect())
>>> print(d1.reduceByKey(lambda a,b:a+b).sortBy(lambda x:x[0],False).collect())
>>> print(d1.reduceByKey(lambda a,b:a+b).sortBy(lambda x:x[1],False).collect())
- mapValues(func), 对键值对 RDD 中每个 value 都应用一个函数,但是 Key 不发生变化
>>> list = [("spark",1),("spark",2),("hadoop",3),("hadoop",5)]
>>> rdd = sc.parallelize(list)
>>> rdd = rdd.mapValues(lambda a:a+1)
>>> rdd.foreach(print)
- join(),内连接,对于给定的两个输入数据集 (K,V1) 和 (K,V2)只有在两个数据集都存在的 key 才会被输出,最终得到一个 (K,(V1,V2))类型的数据集
>>> rdd1 = sc.parallelize([("spark",1),("spark",2),("hadoop",3),("hadoop",5)])
>>> rdd2 = sc.parallelize([("spark","fast")])
>>> rdd3 = rdd1.join(rdd2)
>>> rdd3.foreach(print)
-
combineByKey
combineByKey(createCombiner,mergeValue,mergeCombiners,partitioner,mapSideCombine)参数含义:- createCombiner:在第一次遇到 key 时创建组合器函数,将 RDD 数据集中 V 类型值转化成 C 类型 (V => C)
- mergeValue:合成值函数,再次遇到相同 key 值,将 createCombiner 的 C类型值与这次传入的 V 类型值合并成一个 C 类型值 (C,V) =》C
- mergeCombiners:合并组合器函数,将 C 类型值两两合并成一个 C 类值
- partitioner:使用已有的或自定义的分区函数,默认是 HashPartitioner
- mapSideCombine:是否在 map 端进行 Combine 操作,默认为 True
# 以下通过实例讲解 P77 # 销售数据,采用键值对<公司,当月收入,要求使用 CombineByKey 操作求出每个公司的总收入和每月平均收入,并保存在本地文件 >>> data = sc.parallelize([("company-1",88),("company-1",96),("company-1",85), \ ("company-2",94),("company-2",86),("company-2",74), \ ("company-3",86),("company-3",88),("company-3",92)],3) >>> ans = data.combineByKey(\ lambda income:(income,1),\ lambda acc,income:(acc[0]+income,acc[1]+1),\ lambda acc1,acc2:(acc1[0]+acc2[0],acc1[1]+acc2[1]) ).\ map(lambda x:(x[0],x[1][0],x[1][0]/float(x[1][1]))) >>> ans.repartition(1). \ ... saveAsTextFile("file:///usr/local/spark/mycode/Final-Exam/04.RDD/data/comnbineresult")
RDD 综合案例:图书销量统计
>>> rdd = sc.parallelize([("spark",2),("hadoop",6),("hadoop",4),("spark",6)])
>>> rdd.mapValues(lambda x:(x,1)).\
... reduceByKey(lambda x,y:(x[0]+y[0],x[1]+y[1])).\
... mapValues(lambda x:x[0]/x[1]).collect()
# [('spark', 4.0), ('hadoop', 5.0)]
4.4 数据读写
主要面向 文件读写 & HBase 读写
4.4.1 本地文件系统的数据读写
读取文件
# >>> lines = sc.\
# ... textFile("filePath+FileName")
>>> lines = sc.textFile("word.txt")
>>> lines.first()
# 'Hadoop is Good'
# 注意 Spark 的惰性机制,在执行转化操作时,即使输入了错误的语句,PySpark 也不会马上报错,而是等到执行 “行动” 类型的语句启动真正的计算。
写入文件
>>> lines = sc.textFile("word.txt") # 分布式文件系统 HDFS 读文件
>>> lines.saveAsTextFile("file:///usr/local/spark/mycode/Final-Exam/04.RDD/data/word_backup")
# 写之前删除文件, -rf 强制删除, -r 就是向下递归
# rm -rf word_backup/
>>> lines.saveAsTextFile("word_backup")
# hadoop fs -rm -r /word_backup
# hadoop fs -ls word_backup
4.4.2 HBase 读写数据 (鸽了)
# 先启动 Hadoop、 HBase
# 启动 HBase 和 HBase Shell
cd /usr/local/hbase
./bin/start-hbase.sh
./bin/hbase shell
# bin/stop-hbase.sh
./bin/stop-hbase.sh
hbase> disable 'student'
hbase> drop 'student'
...
综合案例
Case01:求 Top 值
file0.txt
orderid userid payment productid
1,1734,43,155
2,4323,12,34223
3,5442,32,3453
4,1243,34,342
5,1223,20,342
6,542,570,64
7,122,10,123
8,42,30,345
9,152,40,1123
hadoop fs -put /usr/local/spark/mycode/Final-Exam/04.RDD/data/file0 # 推送 file0 文件
>>> lines = sc.textFile("file:///usr/local/spark/mycode/Final-Exam/04.RDD/data/file0")
# len 外括号
>>> rdd1 = lines.filter(lambda line : (len(line.strip()) > 0) and (len(line.split(",")) == 4))
# 提取列
>>> rdd2 = rdd1.map(lambda x:x.split(",")[2]) # 0 ~ 3, 4 列元素
# 转化成整型,并生成 Key-Value 的新 RDD,是因为 sortByKey 操作要求 RDD 必须是 key-value 形式
>>> rdd3 = rdd2.map(lambda x:(int(x),""))
# 使所有元素在一个分区
>>> rdd4 = rdd3.repartition(1)
>>> rdd5 = rdd4.sortByKey(False)
# 提取数字列
>>> rdd6 = rdd5.map(lambda x:x[0])
# 选取前 top 5 个元素
>>> rdd7 = rdd6.take(5)
>>> for a in rdd7:
... print(a)
Case02:文件排序
index = 0
def getindex():
global index
index += 1
return index
>>> lines = sc.textFile("file:///usr/local/spark/mycode/Final-Exam/04.RDD/data/file*")
>>> index = 0
>>> rdd1 = lines.filter(lambda x:(len(x.strip()) > 0))
>>> rdd2 = rdd1.map(lambda x:(int(x.strip()),""))
>>> rdd3 = rdd2.repartition(1)
>>> rdd4 = rdd3.sortByKey(True)
>>> rdd5 = rdd4.map(lambda x:x[0])
>>> rdd6 = rdd5.map(lambda x:(getindex(),x))
>>> rdd6.foreach(print)
>>> rdd6.\
... saveAsTextFile("file:///usr/local/spark/mycode/Final-Exam/04.RDD/data/filesortresult")
Case03:二次排序
# 定义类 SecondarySortKey 用于实现自定义排序 Key
from operator import gt
class SecondarySortKey():
def __init__(self, k):
self.column1 = k[0]
self.column2 = k[1]
def __gt__(self, other):
if other.column1 == self.column1:
return gt(self.column2, other.column2)
else:
return gt(self.column1, other.column1)
# 将要进行二次排序的文件加载进来生成 (K,V) 键值对类型的 RDD
>>> file = "file:///usr/local/spark/mycode/Final-Exam/04.RDD/data/file4"
>>> rdd1 = sc.textFile(file)
>>> rdd2 = rdd1.filter(lambda x:(len(x.strip()) > 0))
# Import ("5 3") => ((5,3),"5,3")
>>> rdd3 = rdd2.map(lambda x:((int(x.split(" ")[0]), int(x.split(" ")[1])), x))
# 使用 sortByKey(func) 基于 SecondarySortKey 进行二次排序
# ((5,3),"5,3") => (SecondarySortKey((1,6)), "1 6")
>>> rdd4 = rdd3.map(lambda x:(SecondarySortKey(x[0]), x[1]))
>>> rdd5 = rdd4.sortByKey(False)
# 去除排序的 Key,只保留结果
>>> rdd6 = rdd5.map(lambda x:x[1])
>>> rdd6.foreach(print)
实验 3 RDD 编程初级实践
Ubuntu 20.04,Spark 3.1.3,Python 3.8.10
# Case1.1 该系总共有多少学生
>>> file = "file:///usr/local/spark/mycode/Final-Exam/04.RDD/data/chapter4-data01.txt"
>>> lines = sc.textFile(file) # 数据格式 'Aaron,OperatingSystem,100'
# 获取每行数据的 第一列
>>> rdd1 = lines.map(lambda x:x.split(",")).map(lambda x:x[0])
>>> distinct_rdd1 = rdd1.distinct()
>>> print(distinct_rdd1.count()) # 265
# Case1.2 该系一共开设了多少门课程
# 获取每列数据的 第二列即可
>>> rdd2 = lines.map(lambda x:x.split(",")).map(lambda x:x[1])
>>> distinct_rdd2 = rdd2.distinct()
>>> print(distinct_rdd2.count()) # 8
# Case1.3 Tom 总成绩平均分, 筛选Tom的成绩信息
>>> rdd3 = lines.map(lambda x:x.split(",")).filter(lambda x:x[0] == "Tom")
>>> rdd3.foreach(print)
# Case1.4 求每名同学的选修的课程门数;
# 学生每门课程都对应(学生姓名,1),学生有n门课程则有n个(学生姓名,1)
>>> rdd4 = lines.map(lambda x:x.split(",")).map(lambda x:(x[0],1))
# 按学生姓名获取每个学生的选课总数
>>> total_rdd4 = rdd4.reduceByKey(lambda x,y:x+y)
>>> total_rdd4.foreach(print)
# Case1.5 该系DataBase课程共有多少人选修;
>>> rdd5 = lines.map(lambda x:x.split(",")).filter(lambda x:x[1] == "DataBase")
>>> print(rdd5.count()) # 126
# Case1.6 各门课程的平均分是多少;
>>> rdd6 = lines.map(lambda x:x.split(",")).map(lambda x:(x[1],(int(x[2]),1)))
>>> tmp = rdd6.reduceByKey(lambda x,y:(x[0]+y[0],x[1]+y[1]))
>>> avg = tmp.map(lambda x:(x[0],round(x[1][0]/x[1][1],2)))
>>> avg.foreach(print)
# Case1.7使用累加器计算共有多少人选了DataBase这门课。
>>> rdd7 = lines.map(lambda x:x.split(",")).filter(lambda x:x[1] == "DataBase")
>>> acc = sc.accumulator(0) # 定义一个 从0开始的累加器
>>> rdd7.foreach(lambda x:acc.add(1))
>>> acc.value
# Case 2.0 编写独立应用程序实现数据去重
>>> line1 = sc.\
... textFile("file:///usr/local/spark/mycode/Final-Exam/04.RDD/data/inputA")
>>> line2 = sc.\
... textFile("file:///usr/local/spark/mycode/Final-Exam/04.RDD/data/inputB")
>>> line = line1.union(line2)
>>> print(line.first()) # 20170101 x
>>> distinct_line = line.distinct()
>>> rdd = distinct_line.sortBy(lambda x:x)
>>> file = "file:///usr/local/spark/mycode/Final-Exam/04.RDD/data/remdup/result"
>>> rdd.repartition(1).saveAsTextFile(file)
# Case 3.0 编写独立应用程序实现求平均值问题
>>> line1 = sc.\
... textFile("file:///usr/local/spark/mycode/Final-Exam/04.RDD/data/Algorithm")
>>> line2 = sc.\
... textFile("file:///usr/local/spark/mycode/Final-Exam/04.RDD/data/Database")
>>> line3 = sc.\
... textFile("file:///usr/local/spark/mycode/Final-Exam/04.RDD/data/Python")
>>> line = line1.union(line2).union(line3)
>>> print(line.first()) # '小明 92'
# map 化千万小心格式问题 map(lambda x : (x[0], (int(x[1]), 1)))
>>> data = line.map(lambda x : x.split(" ")).map(lambda x:(x[0],(int(x[1]),1)))
>>> rdd = data.reduceByKey(lambda x,y:(x[0] + y[0], x[1] + y[1]))
>>> result = rdd.map(lambda x:(x[0], round(x[1][0] / x[1][1], 2)))
>>> result.foreach(print)
第四章简答题
-
请阐述 RDD 有哪几种创建方式
从文件系统中加载数据,本地文件系统或者分布式文件系统 HDFS
通过并行集合(列表)创建 RDD
其他 RDD 转化衍生而来
-
请给出常用的 RDD 转换操作 API 并说明其作用
操作 含义 filter(func) 筛选出满足函数func的元素,并返回一个新的数据集 map(func) 将每个元素传递到函数func中,并将结果返回为一个新的数据集 flatMap(func) 与map()相似,但每个输入元素都可以映射到0或多个输出结果 groupByKey() 应用于(K,V)键值对的数据集时,返回一个新的(K, Iterable)形式的数据集 reduceByKey(func) 应用于(K,V)键值对的数据集时,返回一个新的(K, V)形式的数据集,其中每个值是将每个key传递到函数func中进行聚合后的结果 -
请说明为何使用
persist()方法对一个 RDD 持久化时,会将其称为 “标记为持久化”之所以说“标记为持久化”,是因为出现
persist()语句的地方,并不会马上计算生成RDD并把它持久化,而是要等到遇到第一个行动操作触发真正计算以后,才会把计算结果进行持久化 -
请阐述 RDD 分区的作用
RDD的分区设计主要是用来支持分布式并行处理数据的。在使用分区来并行处理数据时, 是要做到尽量少的在不同的 Executor 之间使用网络交换数据, 所以当使用 RDD 计算时,会尽可能地把计算分配到在物理上靠近数据的位置。
由于分区是逻辑概念;可以理解为,当分区划分完成后,在计算调度时会根据不同分区所对应的数据的实际物理位置,会将相应的计算任务调度到离实际数据存储位置尽量近的计算节点
RDD 是弹性分布式数据集,通常 RDD 很大,会被分成很多个分区,分别保存在不同的节点上,从而增加并行度键少通信开销
-
请阐述在各模式下默认 RDD 分区数目是如何确定的
-
请举例说明 reduceByKey 和 groupByKey 的区别
-
请阐述为了让 Spark 顺利 读/写 HBase 数据,需要做哪些工作
第 5 章 Spark SQL 编程
5.1 DataFrame 创建
由于 Spark 2.0 之后版本开始,Spark 的全新接口 SparkSession 接口替代 Spark 1.6 中的 SQLContext 和 HiveContext 接口来实现其对数据的加载、转换、处理等功能。
from pyspark import SparkContext,SparkConf
from pyspark.sql import SparkSession
spark = SparkSession.builder.config(conf = SparkConf()).getOrCreate()
>>> df = spark.read.json("file:///usr/local/spark/examples/src/main/resources/people.json")
>>> df.select("name","age").write.format("json").\
... save("file:///usr/local/spark/examples/src/main/resources/people_backup00.json")
spark.read.format("text/json/parquet").load("filePath")
spark.write.text/json/parquet("filePath")
spark.write.("text/json/parquet").save("filePath")
5.2 DataFrame 常用操作
>>> df.printSchema() # 打印输出 DataFrame 的模式 (Schema)
root
|-- age: long (nullable = true)
|-- name: string (nullable = true)
# --------------------------- #
# 2. select() 从 DataFrame 中
>>> df.select(df["name"], df["age"] + 1).show()
# filter() 实现按条件查询,找到满足条件要求的记录
>>> df.filter(df['age'] > 20).show()
# groupBy() 用于对记录进行分组
>>> df.groupBy("age").count().show()
# sort() 对记录进行排序 desc() 降序, asc() 升序
>>> df.sort(df["age"].desc()).show()
>>> df.sort(df["age"].desc(),df["name"].asc()).show() # 注意先后次序
5.3 利用反射机制推断 RDD 模式
# 把 people.txt 加载到内存中生成一个 DataFrame
>>> from pyspark.sql import Row
>>> file = "file:///usr/local/spark/examples/src/main/resources/people.txt"
>>> people = spark.sparkContext.textFile(file).\
... map(lambda line:line.split(",")).\
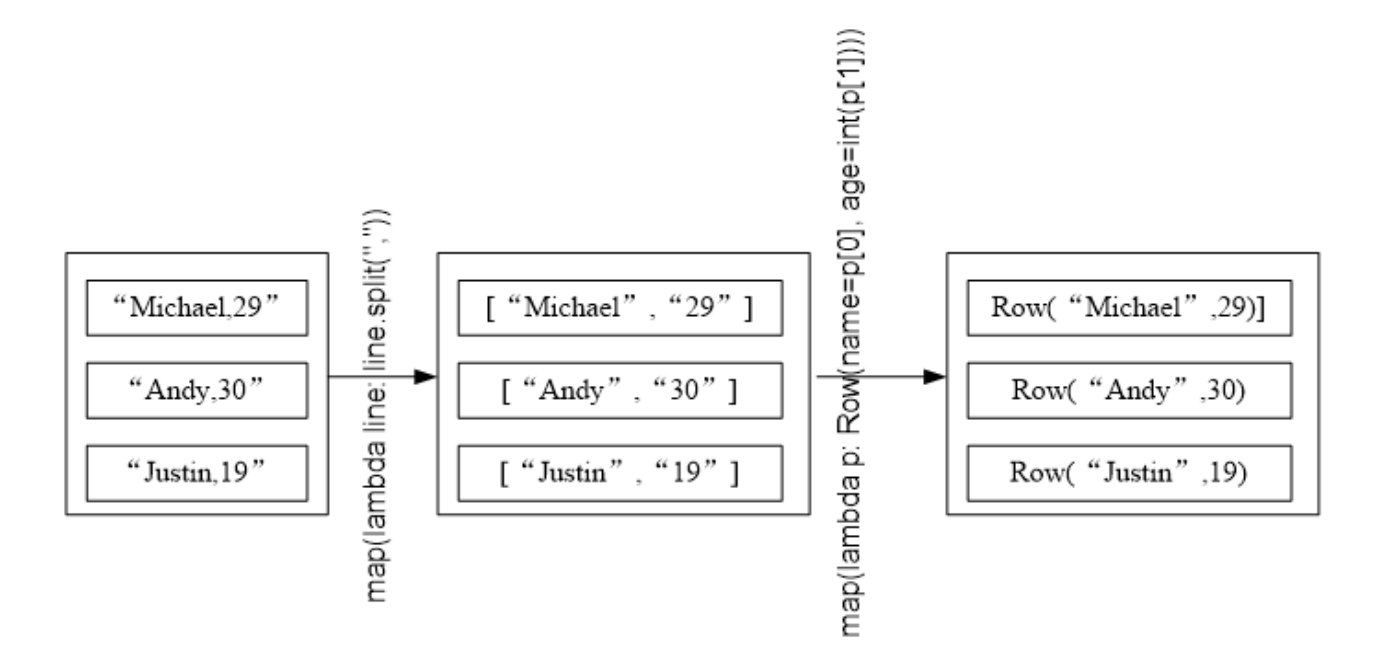
... map(lambda p:Row(name=p[0],age=int(p[1])))
# 查询数据
>>> schemaPeople = spark.createDataFrame(people)
# 必须注册成临时表才能使用下面的查询
>>> schemaPeople.createOrReplaceTempView("people")
>>> sql = "select name,age from people where age > 20"
>>> personsDF = spark.sql(sql)
# >>> personsDF.show() # 也可输出记录
# 格式化为 RDD 后在输出
>>> personRDD = personDF.rdd.map(lambda p : "Name: " + p.name + "," + "Age: " + str(p.age))
>>> personRDD.foreach(print)
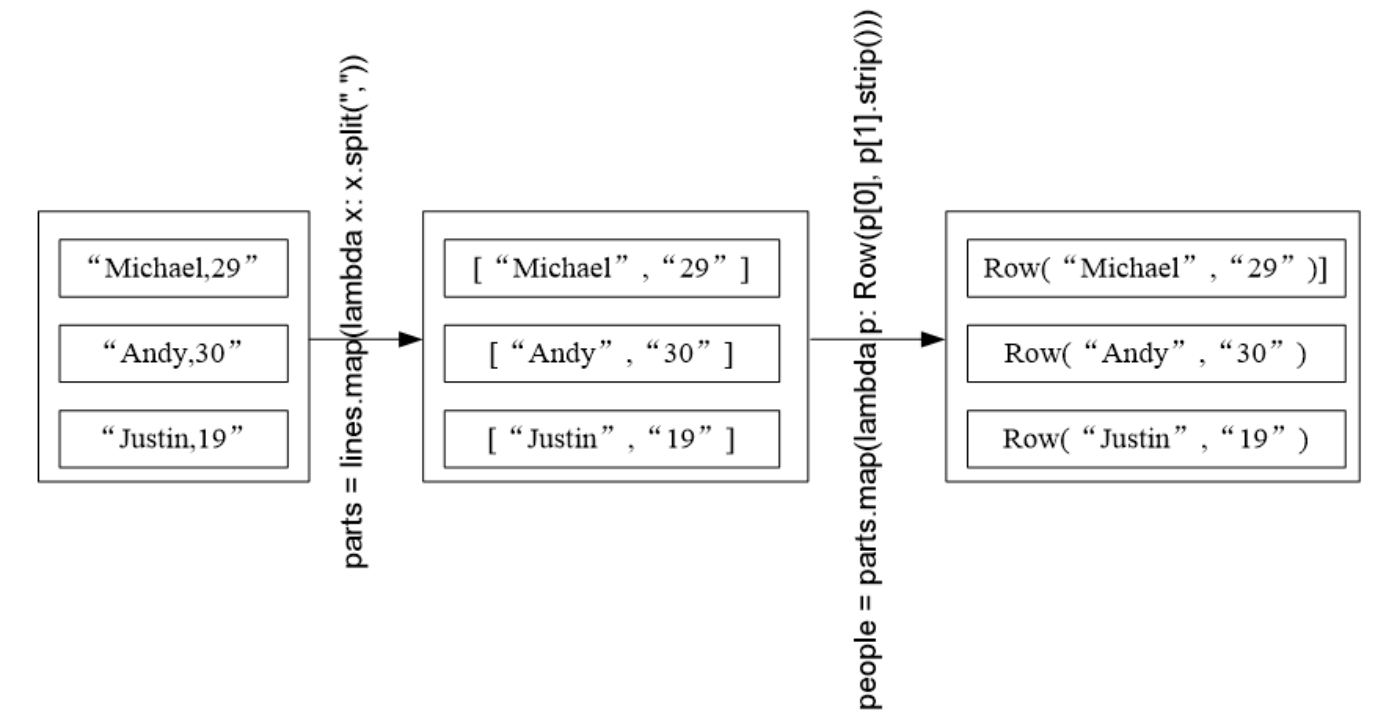
5.4 使用编程方式定义 RDD 模式
当无法提前获知 DS 时,就需要采用编程的方式定义 RDD 模式。
加载 people.txt 至 DataFrame,并完成 SQL 查询
>>> from pyspark.sql import *
>>> from pyspark.sql.types import *
# Step 1: Create table name
>>> schemaString = "name age"
>>> fields = [StructField(field_name, StringType(), True) for field_name in schemaString.split(" ")]
>>> schema = StructType(fields)
# Step 2: Add Record
>>> file = "file:///usr/local/spark/examples/src/main/resources/people.txt"
>>> lines = spark.sparkContext.textFile(file)
>>> parts = lines.map(lambda x:x.split(","))
>>> people = parts.map(lambda p:Row(p[0],p[1].strip()))
# Step 3: joint
>>> schemaPeople = spark.createDataFrame(people, schema)
>>> schemaPeople.createOrReplaceTempView("people")
>>> sql = "select name, age from people"
>>> rdd = spark.sql(sql)
>>> rdd.show()
返回简答题:Click Here
5.5 使用 Spark SQL 读写数据库
-
准备工作,安装和开启 MySQL 服务并使用 SQL 语句完成数据库和表的创建
sudo service mysql start mysql -u root -pmysql> create database spark; mysql> use spark; mysql> create table student (id int(4), name char(20), gender char(4), age int(4)); mysql> insert into studet values(1, 'RioTian', 'M', 22); mysql> insert into student values(1, 'Riv', 'F', 28); mysql> select * from student; +------+---------+--------+------+ | id | name | gender | age | +------+---------+--------+------+ | 1 | RioTian | M | 22 | | 1 | Riv | F | 28 | +------+---------+--------+------+ 2 rows in set (0.00 sec) -
MySQL 读取数据
>>> url = 'jdbc:mysql://localhost:3306/spark?useSSL=false' >>> table = 'spark' >>> auth_mysql = {"user": "root", "password": "kokoro"} # ------------------- 用下面即可,如果报错说明没导入 Jar 包 --------------- # # MySQL5.x 使用的是 com.mysql.jdbc.Driver >>> jdbcDF = spark.read.\ ... format("jdbc").\ ... option("driver","com.mysql.cj.jdbc.Driver").\ ... option("url", "jdbc:mysql://localhost:3306/spark").\ ... option("dbtable", "student").\ ... option("user", "root").\ ... option("password", "kokoro").\ ... load() >>> jdbcDF.show() -
MySQL 写入数据
>>> from pyspark.sql import * >>> from pyspark.sql.types import * >>> from pyspark import SparkContext, SparkConf # Step 1: 设置模式信息 >>> schema = StructType([StructField("id", IntegerType(), True), \ ... StructField("name", StringType(), True), \ ... StructField("gender", StringType(), True), \ ... StructField("age", IntegerType(), True)]) # Step 2: 下面设置两条数据,表示两个学生的信息 >>> studentRDD = spark.\ ... sparkContext.\ ... parallelize(["3 Rongcheng M 26","4 Guanhua M 27"]).\ ... map(lambda x:x.split(" ")) # Step 3: 下面创建Row对象,每个Row对象都是rowRDD中的一行 >>> rowRDD = studentRDD.map(lambda p:Row(int(p[0].strip()), p[1].strip(), p[2].strip(), int(p[3].strip()))) # Step 4: 建立起Row对象和模式之间的对应关系,也就是把数据和模式对应起来 >>> studentDF = spark.createDataFrame(rowRDD, schema) # Step 5: 写入数据库 >>> prop = {} >>> prop['user'] = 'root' >>> prop['password'] = 'kokoro' >>> prop['driver'] = "com.mysql.cj.jdbc.Driver" >>> studentDF.write.jdbc("jdbc:mysql://localhost:3306/spark",'student','append', prop) +------+-----------+--------+------+ | id | name | gender | age | +------+-----------+--------+------+ | 1 | RioTian | M | 22 | | 1 | Riv | F | 28 | | 4 | Guanhua | M | 27 | | 3 | Rongcheng | M | 26 | +------+-----------+--------+------+ 4 rows in set (0.00 sec)
5.6 Spark SQL 编程初级实践
Ubuntu 20.04,Spark 3.1.3,Python 3.8.10 数据库 MySQL 8.0
# Case 1 Spark SQL 基本操作
# 先读入 json 文件
>>> spark = SparkSession.builder().getOrCreate()
>>> file = "file:///usr/local/spark/mycode/Final-Exam/05.DataFrame/Data/employee.json"
>>> df = spark.read.json(file)
# Case 1.1 查询DataFrame的所有数据
>>> df.show()
# Case 1.2 查询DataFrame的所有数据
>>> df.distinct().show()
# Case 1.3 查询所有数据,打印时去除id字段
>>> df.drop("id").show()
# Case 1.4 筛选age>20的记录
>>> df.filter(df["age"] > 20).show()
>>> df.filter(df.age > 20).show()
# Case 1.5 将数据按name分组
>>> df.groupBy(df["name"]).count().show()
# Case 1.6 将数据按name升序排列
>>> df.sort(df["name"].asc()).show()
>>> df.sort(df.name.asc()).show()
# Case 1.7 取出前3行数据
>>> df.take(3)
>>> df.head(3)
# Case 1.8 查询所有记录的name列,并为其取别名为username
>>> df.select(df.name.alias("username")).show()
# Case 1.9 查询年龄age的平均值
>>> df.agg({"age": "mean"}).show()
# Case 1.10 查询年龄age的最大值
>>> df.agg({"age": "max"}).show()
# Case 2 编程实现将 RDD 转换 DataFrame
# 读入 employee.txt
>>> file = "file:///usr/local/spark/mycode/Final-Exam/05.DataFrame/Data/employee.txt"
>>> peopleRDD = peopleRDD = spark.sparkContext.textFile(file)
>>> rowRDD = peopleRDD.map(lambda line:line.split(",")).\
... map(lambda x:Row(int(x[0]),x[1],int(x[2]))).toDF()
>>> rowRDD.createOrReplaceTempView("employee")
>>> sql = "select * from employee"
>>> df = spark.sql(sql)
>>> df.rdd.map(lambda t : "id:" + str(t[0]) + "," + "Name:" + t[1] + "," + "age" + str(t[2])).foreach(print)
# Case 3 编程实现利用 DataFrame 读写 MYSQL 数据
# Case 3.1 创建数据库 sparktest 并加入数据
mysql> create database sparktest;
mysql> use sparktest;
mysql> create table employee (id int(4), name char(20), gender char(4), age int(4));
mysql> insert into employee values(1,'Alice','F',22);
mysql> insert into employee values(2,'kirito','M',25);
mysql> insert into employee values(2,'RioTian','M',25);
# Case 3.2 连接 MYSQL 并插入数据
>>> jdbcDF = spark.read.\
... format("jdbc").\
... option("driver","com.mysql.cj.jdbc.Driver").\
... option("url", "jdbc:mysql://localhost:3306/sparktest").\
... option("dbtable", "employee").\
... option("user", "root").\
... option("password", "kokoro").\
... load()
>>> jdbcDF.filter(jdbcDF.age > 20).collect() # 检查是否连接成功
>>> studentRDD = spark.sparkContext.parallelize(["3 Mary F 26","4 Tom M 23"]).map(lambda line : line.split(" "))
>>> schema = StructType([StructField("id",IntegerType(),True),StructField("name", StringType(), True),StructField("gender", StringType(), True),StructField("age",IntegerType(), True)])
>>> rowRDD = studentRDD.\
... map(lambda p : Row(int(p[0]),p[1].strip(),p[2].strip(),int(p[3])))
>>> employeeDF = spark.createDataFrame(rowRDD, schema)
>>> prop = {}
>>> prop['user'] = 'root'
>>> prop['password'] = 'kokoro'
>>> prop['driver'] = "com.mysql.cj.jdbc.Driver"
>>> employeeDF.write.jdbc("jdbc:mysql://localhost:3306/sparktest", "employee", "append", prop)
>>> jdbcDF.collect()
>>> jdbcDF.agg({"age" : "max"}).show()
>>> jdbcDF.agg({"age" : "sum"}).show()
第五章简答题
-
请阐述 Hive 中 SQL 查询转化为 MapReduce 作业的具体过程。
\[SQL \to 抽象语法树 \to 查询快 \to 逻辑查询计划\to 重写逻辑查询计划\to 物理计划 \to 选择最佳的优化查询策略 \] -
请分析 Spark SQL 出现的原因。
满足因关系数据库在大数据时代无法满足各种新增用户需求:
- 要在不同数据源执行各种操作,包括结构化和非结构化数据
- 用户需执行高级分析,eg:ML和图像处理
- 融合关系查询和复杂分析算法
-
RDD 和 DataFrame 有什么区别?
RDD 一般支持 Spark MLib 同时使用,但不支持 Spark SQL 操作,而 DataFrame 相反
此外在结构上 RDD是分布式的 Java对象的集合、但对象内部结构对 RDD 而言是不可知的,DataFrame是以 RDD 为基础的分布式数据集、提供了详细的结构信息,就相当于关系数据库的一张表。

-
Spark SQL 支持读写哪些类型的数据?
支持任何 Hive 支持的存储格式:TXT、JSON、parquet、JDBC等...
-
从 RDD 转换得到 DataFrame 可以有哪两种方式?
- 利用反射机制推断 RDD 模式
- 使用编程方法定义 RDD 模式
-
使用编程方式定义 RDD 模式的基本步骤是什么?
- 制作 “表头”
- 制作 “表中的记录”
- 把 “表头” 和 “表中记录” 拼装在一起
-
为了使 Spark SQL 能够访间 MySQL 数据库,需要做哪些准备工作?
- 安装 MySQL 数据库并在 Linux 中启动 MYSQL 服务
- 提前在数据库中完成 DB 和 Table 的创建
第 6 章简答题
-
请阐述静态数据与流数据的区别。
静态数据是静止不动的,而流数据是指在时间分布和数量上无限的一系列动态数据集合体,数据记录是流数据的最小单位。
-
请阐述批量计算与实时计算的区别。
批量计算以静态数据为对象,可以在很充裕的时间内对海量数据进行处理,计算得到有价值的信息。
实时计算是需要能够实时得到计算结果,一般要求响应时间为秒级。
-
对于一个流计算系统而言,在功能设计上应该满足哪些需求?
高性能,这是基本要求,如每秒处理几十万条数据
海量式,支持tb级甚至pb级
实时性,保证低延迟
分布式,支持大数据的基本框架,必须能够平滑扩展
易用性,能够快速进行开发和部署。
可靠性,能够可靠的处理数据。
-
请列举几种典型的流计算框架。
商业级的流计算平台
开源流计算框架
公司为支持自身业务开发的流计算框架
-
请阐述流计算的基本处理流程。
数据实时采集
数据实时计算
实时查询服务
-
请阐述数据采集系统的各个组成部分的功能。
agent:主动采集数据,并把数据推送到collector部分。
collector:接受多个agent的数据,并实现有序、可靠、高性能的转发。
store:存储collector转发过来的数据。
-
请阐述数据实时计算的基本流程。
流数据系统接收数据采集系统不断发来的实时数据,实时地进行分析计算,并反馈结果。
-
请阐述 Spark Streaming 的基本设计原理。
将实时输入数据流以时间片为单位进行拆分,然后采用spark引擎以类似批处理的方式处理每个时间片。
-
请阐述 Spark Streaming 的工作机制。
-
请阐述 Spark Streaming 程序编写的基本步骤。
1)通过创建输入 DStream ( Input Dstream )来定义输入源。流计算处理的数据对象是来自输入源的数据,这些输入源会源源不断地产生数据,并发送给 Spark Streaming ,由 Receiver 组件接收以后,交给用户自定义的 Spark Streaming 程序进行处理。
2)通过对 DStream 应用转换操作和输出操作来定义流计算。流计算过程通常是由用户自定义实现的,需要调用各种 DStream 操作实现用户处理逻辑。
3)调用 StreamingContext 对象的 start() 方法来开始接收数据和处理流程。
4)通过调用 StreamingContext 对象的
awaitTermination()方法来等待流计算进程结束,或者也可以通过调用StreamingContext 对象的stop()方法来手动结束流计算进程。 -
Spark Streaming 主要包括哪3种类型的基本输入源?
文件流、套接字流、RDD队列流
-
请阐述 DStream 有状态转换操作和无状态转换操作的区别。
前者可以跨批次数据之间维护历史状态信息。
后者无法维护历史批次的状态信息。
第 7 章简答题
1.请阐述 Spark Structured Streaming 与 Spark SQL 和 Spark Streaming 的区别。
Structured Streaming 处理的数据与 Spark Streaming 一样,也是源源不断的数据流,它们之间的区别在于, Spark Streaming 采用的数据抽象是 DStream (本质上就是一系列 RDD ),而 Structured Streaming 采用的数据抽象是 DataFrame . Structured Streaming 可以使用 Spark SQL 的 DataFrame / Dataset 来处理数据流。虽然 Spark SQL 也是采用 DataFrame 作为数据抽象,但是 Spark SQL 只能处理静态的数据 Structured,而 Streaming 可以处理结构化的数据流。此外, Spark Streaming 只能实现秒级的实时响应,而 Structured Streaming 由于采用了全新的设计方式,采用微批处理模型时可以实现100毫秒级别的实时响应,采用持续处理模型时可以支持毫秒级的实时响应。
2.请总结编写 Structured Streaming 程序的基本步骤。
- 导入pyspark模块。
- 创建sparksession对象。
- 创建输入数据源。
- 定义流计算过程。
- 启动流计算并输出结果。
-
请阐述 Append 、 complete 、 Update 这3种输出模式的异同。
append模式:只有结果表中自上次触发间隔后增加的新行,才会被写入到外部存储器。
complete模式:已更新的完整的结果表可被写入外部存储器。
update模式:只有自上次触发间隔后结果表中发生更新的行,才会被写入外部存储器。
第 8 章简答题
1.与 Map-Reduce 框架相比,为何 Spark 更适合进行机器学习中各算法的处理?
- MapReduce 自身存在缺陷,延迟高,磁盘开销大,无法高效支持迭代计算,使得 MapReduce 无法很好的支持分布式 ML 算法
- 而Spark 立足于内存计算,天然适合用于迭代计算,能很好与机器学习算法相匹配
2.简述流水线的( Pipeline )的几个部件及主要作用,使用 Pipeline 来构建机器学习工作流有什么好处?
- DataFrame,即 Spark SQL 中的 DataFrame,用于容纳各种数据类型
- 转换器:一种可以将一个 DataFrame 转化成另一个 DataFrame 的算法
- 评估器:学习算法或训练数据上训练方法的概念抽象
- 流水线,把多个工作流阶段连接在一起,形成 ML 的工作流,并获得输出结果
- 参数,用来设置转换器或评估器的参数