为什么Regularization可以解决过拟合
一、总结
一句话总结:
Regularization是把参数w加到loss里面去,而y=wx+b,参数越小,y越平滑
也就是y对x越不敏感,自然可以解决x本身噪声带来的影响(也就是去除特别数据带来的影响),也就自然越接近真实模型
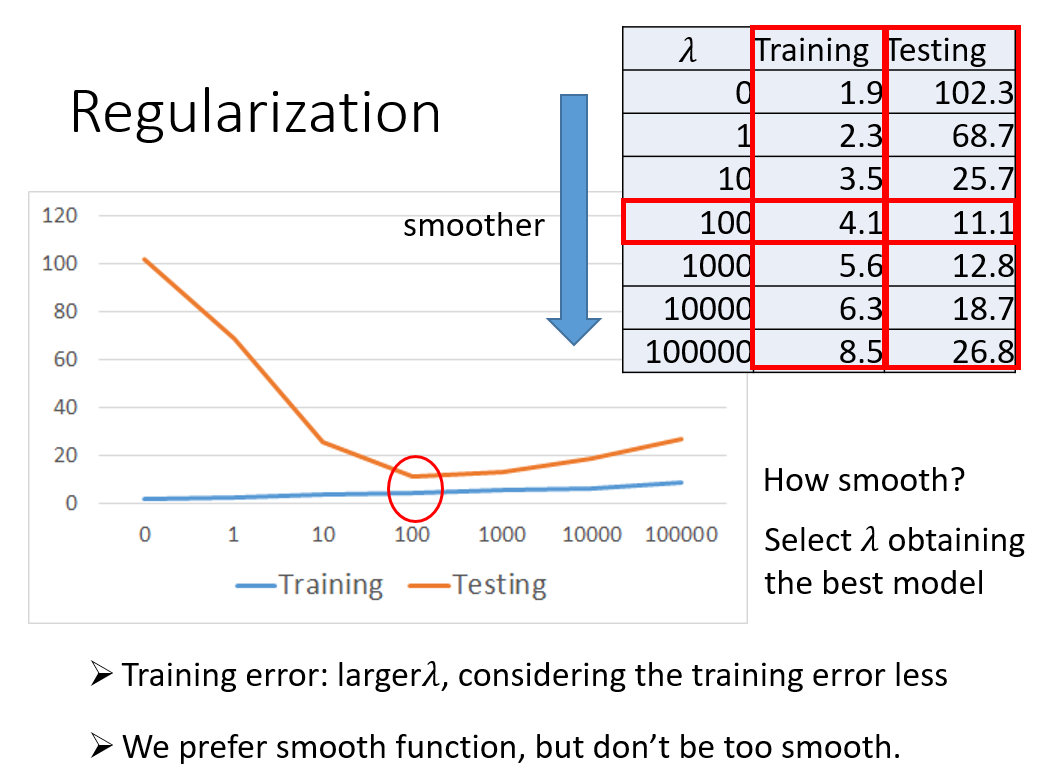
1、正则化loss算上w的时候,还有lambda参数?
$$L = sum _ { n } ( hat { y } ^ { n } - ( b + sum w _ { i } x _ { i } ) ) ^ { 2 }+ lambda sum ( w _ { i } ) ^ { 2 }$$
不同lambda得到的测试集的准确率不一样,详见正文图,选择最合适的lambda即可
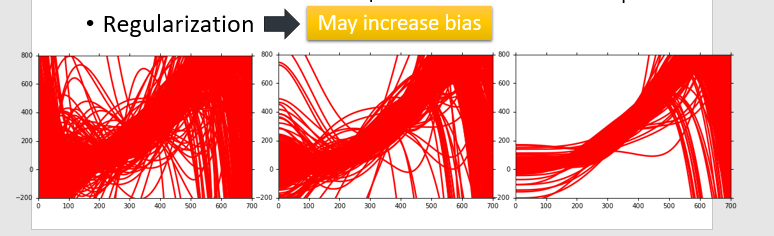
2、为什么正则化可以降低variance,却可能增加bias?
因为把曲线变平滑了,也就是对输入数据不敏感了,
也可以理解为变平滑之后,target变小了
也可以理解为变平滑之后,向低维函数靠近了
二、为什么Regularization可以解决过拟合
博客对应课程的视频位置:

最左边是正则化之前,右边是正则化之后,